Gersch Timothy M, Foley Nicholas C, Eisenberg Ian, Gottlieb Jacqueline
Department of Neuroscience, Columbia University, New York, New York, United States of America.
Department of Neuroscience, Columbia University, New York, New York, United States of America ; The Kavli Institute for Brain Science Columbia University, New York, New York, United States of America.
PLoS One. 2014 Feb 11;9(2):e88725. doi: 10.1371/journal.pone.0088725. eCollection 2014.
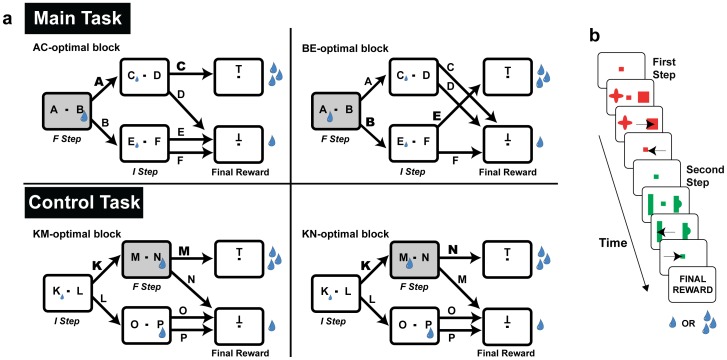
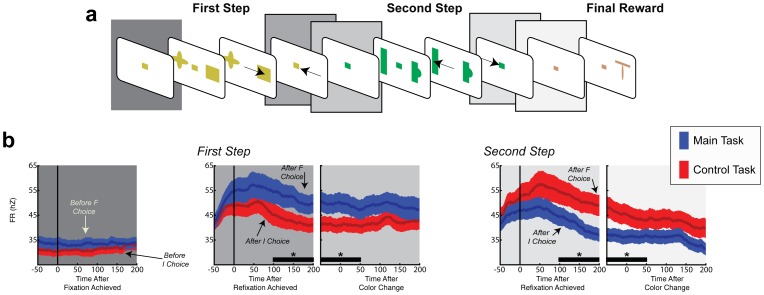
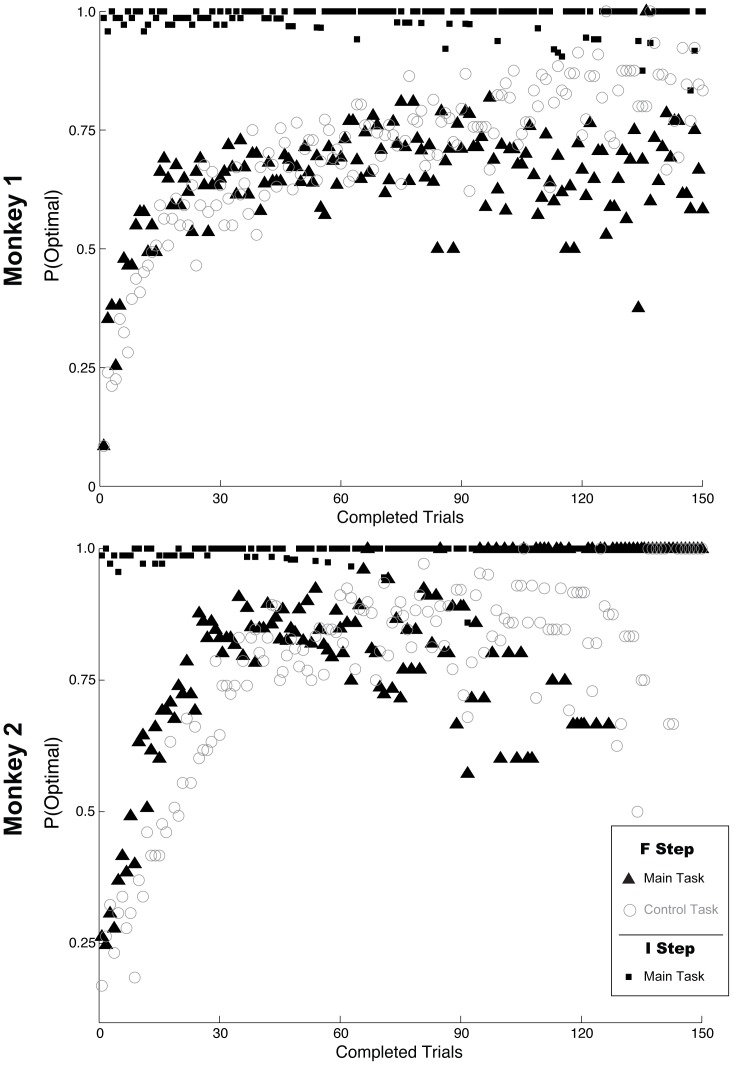
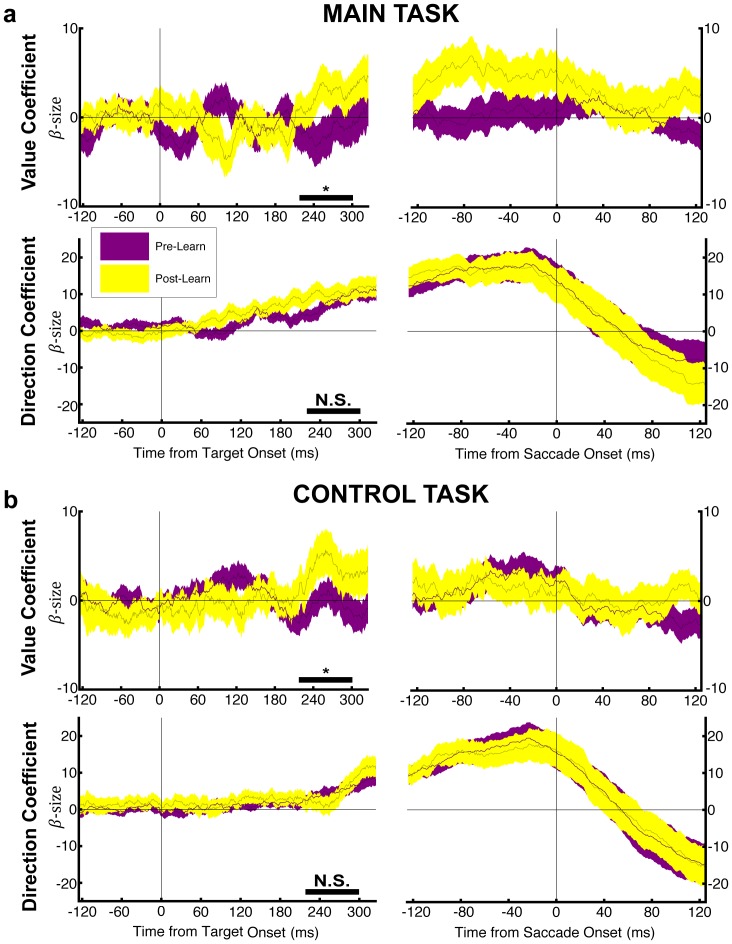
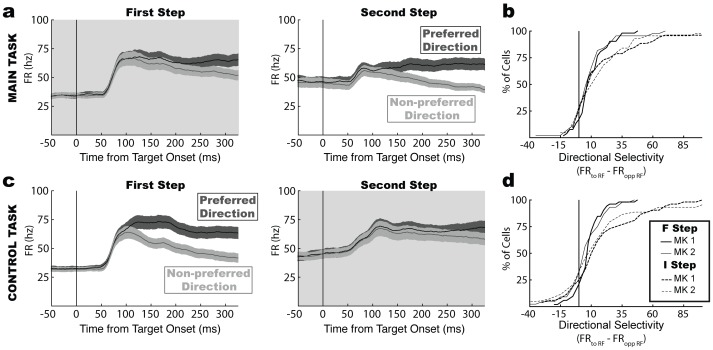
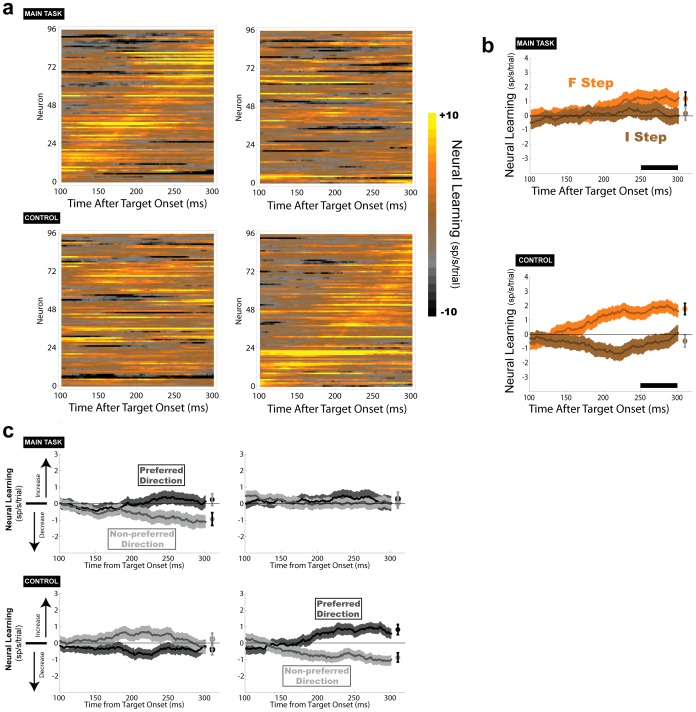
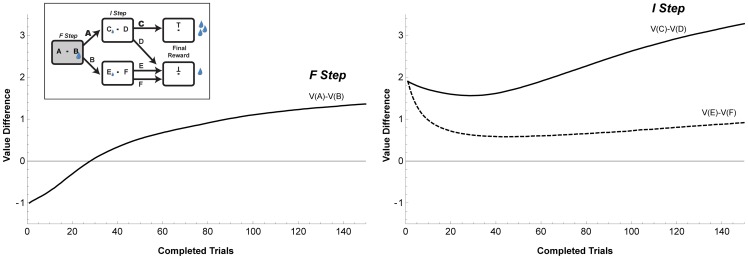
Empirical studies of decision making have typically assumed that value learning is governed by time, such that a reward prediction error arising at a specific time triggers temporally-discounted learning for all preceding actions. However, in natural behavior, goals must be acquired through multiple actions, and each action can have different significance for the final outcome. As is recognized in computational research, carrying out multi-step actions requires the use of credit assignment mechanisms that focus learning on specific steps, but little is known about the neural correlates of these mechanisms. To investigate this question we recorded neurons in the monkey lateral intraparietal area (LIP) during a serial decision task where two consecutive eye movement decisions led to a final reward. The underlying decision trees were structured such that the two decisions had different relationships with the final reward, and the optimal strategy was to learn based on the final reward at one of the steps (the "F" step) but ignore changes in this reward at the remaining step (the "I" step). In two distinct contexts, the F step was either the first or the second in the sequence, controlling for effects of temporal discounting. We show that LIP neurons had the strongest value learning and strongest post-decision responses during the transition after the F step regardless of the serial position of this step. Thus, the neurons encode correlates of temporal credit assignment mechanisms that allocate learning to specific steps independently of temporal discounting.
决策的实证研究通常假定价值学习受时间支配,即特定时间出现的奖励预测误差会触发对所有先前行动的时间折扣学习。然而,在自然行为中,目标必须通过多个行动来实现,且每个行动对最终结果可能具有不同的意义。正如在计算研究中所认识到的,执行多步行动需要使用信用分配机制,将学习聚焦于特定步骤,但对于这些机制的神经关联知之甚少。为了研究这个问题,我们在一个串行决策任务中记录了猴子外侧顶内区(LIP)的神经元,在该任务中,两个连续的眼动决策会导致最终奖励。潜在的决策树结构使得这两个决策与最终奖励具有不同的关系,并且最优策略是在其中一个步骤(“F”步骤)基于最终奖励进行学习,而在其余步骤(“I”步骤)忽略该奖励的变化。在两种不同的情境中,F步骤要么是序列中的第一个,要么是第二个,以控制时间折扣的影响。我们发现,无论F步骤在序列中的位置如何,LIP神经元在F步骤之后的转换期间具有最强的价值学习和最强的决策后反应。因此,这些神经元编码了时间信用分配机制的关联物,该机制将学习独立于时间折扣分配到特定步骤。