Ramakrishnan Kandan, Scholte H Steven, Groen Iris I A, Smeulders Arnold W M, Ghebreab Sennay
Intelligent Systems Lab Amsterdam, Institute of Informatics, University of Amsterdam Amsterdam, Netherlands.
Cognitive Neuroscience Group, Department of Psychology, University of Amsterdam Amsterdam, Netherlands.
Front Comput Neurosci. 2015 Jan 15;8:168. doi: 10.3389/fncom.2014.00168. eCollection 2014.
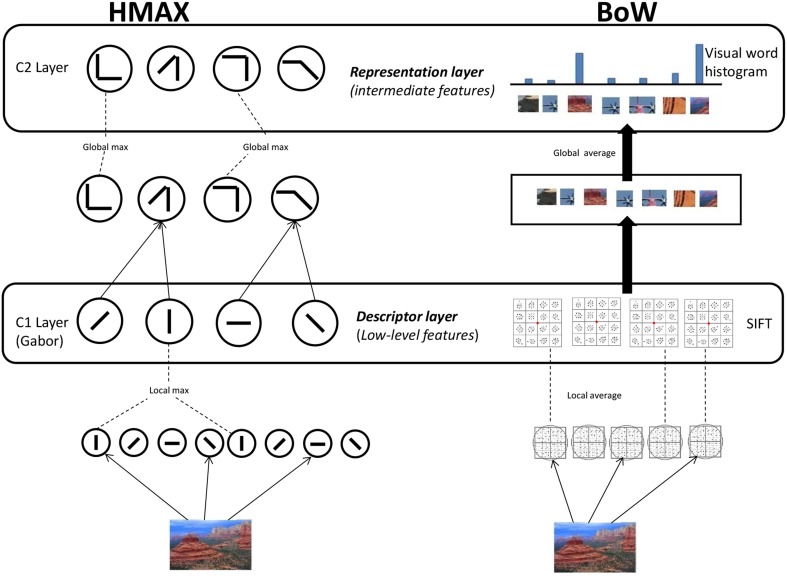
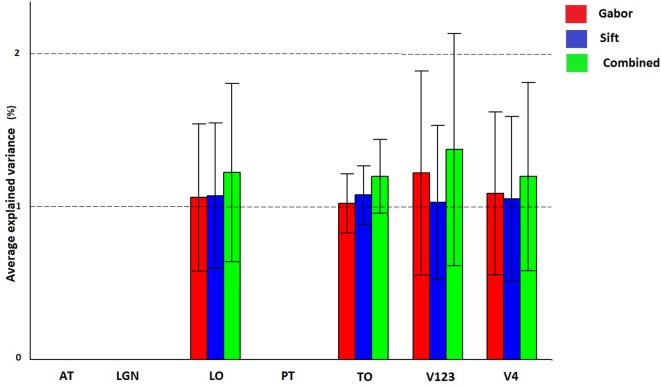
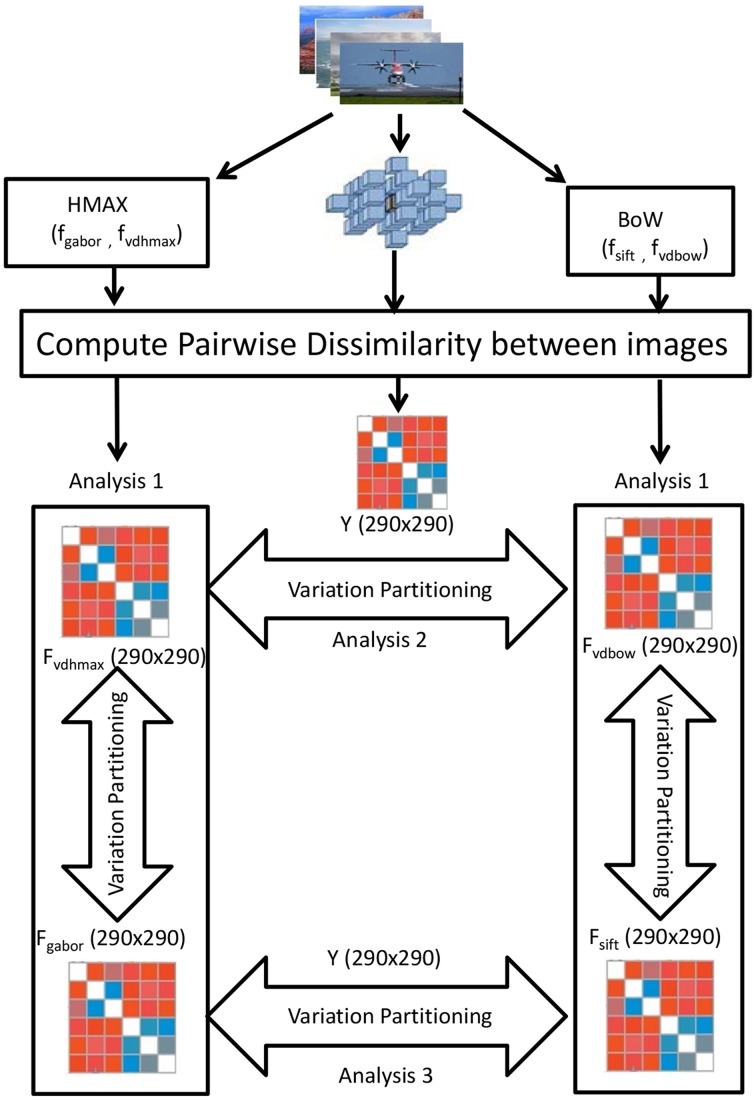
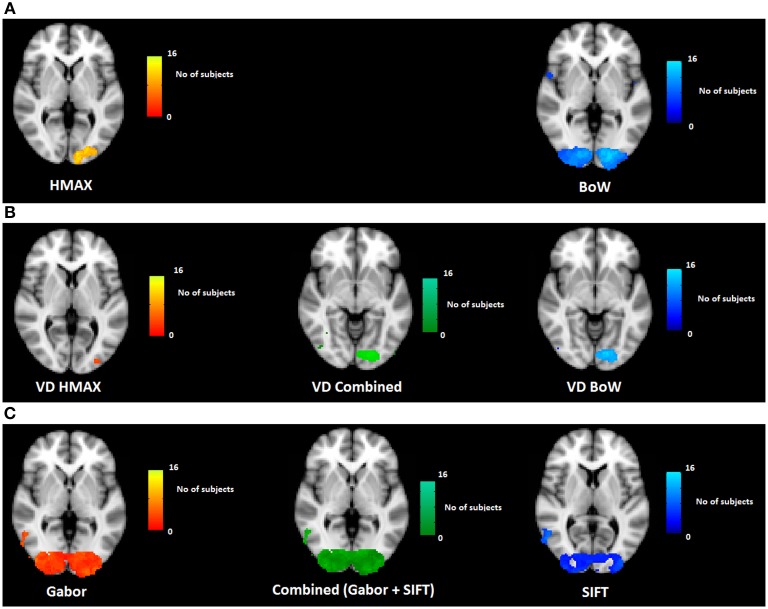
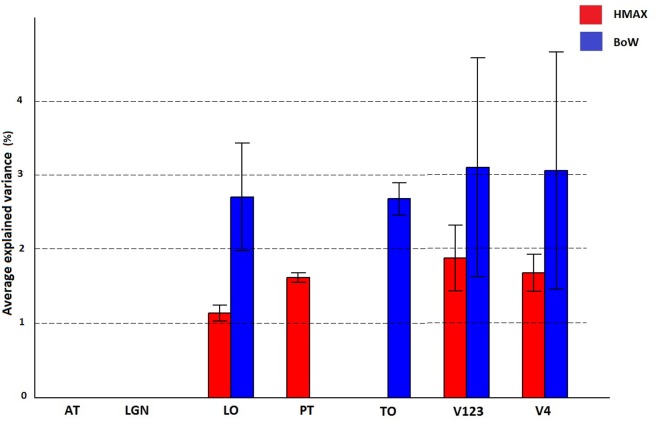
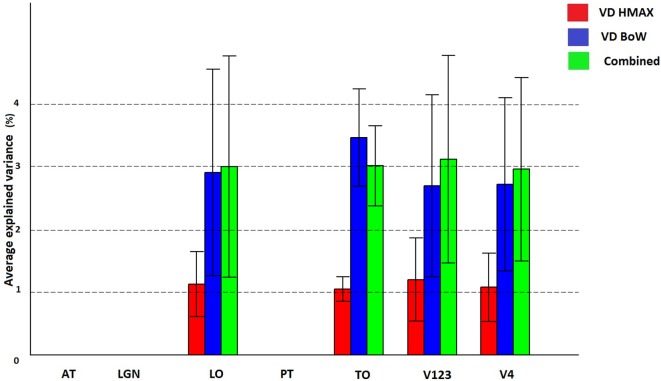
The human visual system is assumed to transform low level visual features to object and scene representations via features of intermediate complexity. How the brain computationally represents intermediate features is still unclear. To further elucidate this, we compared the biologically plausible HMAX model and Bag of Words (BoW) model from computer vision. Both these computational models use visual dictionaries, candidate features of intermediate complexity, to represent visual scenes, and the models have been proven effective in automatic object and scene recognition. These models however differ in the computation of visual dictionaries and pooling techniques. We investigated where in the brain and to what extent human fMRI responses to short video can be accounted for by multiple hierarchical levels of the HMAX and BoW models. Brain activity of 20 subjects obtained while viewing a short video clip was analyzed voxel-wise using a distance-based variation partitioning method. Results revealed that both HMAX and BoW explain a significant amount of brain activity in early visual regions V1, V2, and V3. However, BoW exhibits more consistency across subjects in accounting for brain activity compared to HMAX. Furthermore, visual dictionary representations by HMAX and BoW explain significantly some brain activity in higher areas which are believed to process intermediate features. Overall our results indicate that, although both HMAX and BoW account for activity in the human visual system, the BoW seems to more faithfully represent neural responses in low and intermediate level visual areas of the brain.
人类视觉系统被认为是通过中等复杂度的特征,将低级视觉特征转换为物体和场景表征。大脑如何通过计算来表征中等特征仍不清楚。为了进一步阐明这一点,我们比较了计算机视觉中具有生物学合理性的HMAX模型和词袋(BoW)模型。这两种计算模型都使用视觉词典(中等复杂度的候选特征)来表征视觉场景,并且这些模型已被证明在自动物体和场景识别中是有效的。然而,这些模型在视觉词典的计算和池化技术方面存在差异。我们研究了大脑中的哪些区域以及在何种程度上,人类对短视频的功能磁共振成像(fMRI)反应可以由HMAX和BoW模型的多个层次水平来解释。使用基于距离的变异划分方法,对20名受试者观看短视频片段时获得的大脑活动进行了逐体素分析。结果显示,HMAX和BoW都能解释早期视觉区域V1、V2和V3中大量的大脑活动。然而,与HMAX相比,BoW在解释大脑活动方面在受试者之间表现出更高的一致性。此外,HMAX和BoW的视觉词典表征在一些被认为处理中等特征的更高区域中,也能显著解释部分大脑活动。总体而言,我们的结果表明,尽管HMAX和BoW都能解释人类视觉系统中的活动,但BoW似乎更忠实地代表了大脑低水平和中等水平视觉区域的神经反应。