McGovern Mark E, Bärnighausen Till, Salomon Joshua A, Canning David
Harvard Center for Population and Development Studies, 9 Bow Street, Cambridge, MA, 02138, USA.
Department of Global Health and Population, Harvard T.H. Chan School of Public Health, Boston, MA, 02115, USA.
BMC Med Res Methodol. 2015 Feb 5;15:8. doi: 10.1186/1471-2288-15-8.
Selection bias in HIV prevalence estimates occurs if non-participation in testing is correlated with HIV status. Longitudinal data suggests that individuals who know or suspect they are HIV positive are less likely to participate in testing in HIV surveys, in which case methods to correct for missing data which are based on imputation and observed characteristics will produce biased results.
The identity of the HIV survey interviewer is typically associated with HIV testing participation, but is unlikely to be correlated with HIV status. Interviewer identity can thus be used as a selection variable allowing estimation of Heckman-type selection models. These models produce asymptotically unbiased HIV prevalence estimates, even when non-participation is correlated with unobserved characteristics, such as knowledge of HIV status. We introduce a new random effects method to these selection models which overcomes non-convergence caused by collinearity, small sample bias, and incorrect inference in existing approaches. Our method is easy to implement in standard statistical software, and allows the construction of bootstrapped standard errors which adjust for the fact that the relationship between testing and HIV status is uncertain and needs to be estimated.
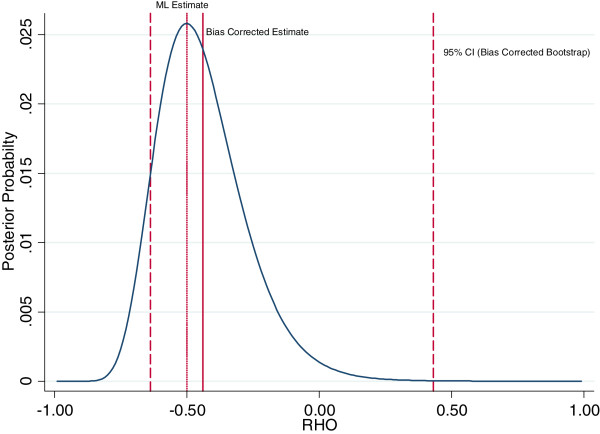
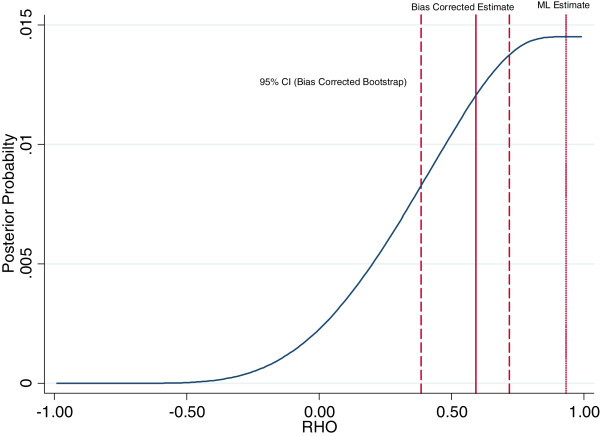
Using nationally representative data from the Demographic and Health Surveys, we illustrate our approach with new point estimates and confidence intervals (CI) for HIV prevalence among men in Ghana (2003) and Zambia (2007). In Ghana, we find little evidence of selection bias as our selection model gives an HIV prevalence estimate of 1.4% (95% CI 1.2% - 1.6%), compared to 1.6% among those with a valid HIV test. In Zambia, our selection model gives an HIV prevalence estimate of 16.3% (95% CI 11.0% - 18.4%), compared to 12.1% among those with a valid HIV test. Therefore, those who decline to test in Zambia are found to be more likely to be HIV positive.
Our approach corrects for selection bias in HIV prevalence estimates, is possible to implement even when HIV prevalence or non-participation is very high or very low, and provides a practical solution to account for both sampling and parameter uncertainty in the estimation of confidence intervals. The wide confidence intervals estimated in an example with high HIV prevalence indicate that it is difficult to correct statistically for the bias that may occur when a large proportion of people refuse to test.
如果未参与检测与艾滋病毒感染状况相关,那么在艾滋病毒流行率估计中就会出现选择偏倚。纵向数据表明,知晓或怀疑自己感染艾滋病毒呈阳性的个体参与艾滋病毒调查检测的可能性较小,在这种情况下,基于插补法和观察到的特征来校正缺失数据的方法会产生有偏结果。
艾滋病毒调查访员的身份通常与艾滋病毒检测参与情况相关,但不太可能与艾滋病毒感染状况相关。因此,访员身份可作为一个选择变量,用于估计赫克曼型选择模型。这些模型能得出渐近无偏的艾滋病毒流行率估计值,即使未参与检测与未观察到的特征(如艾滋病毒感染状况的知晓情况)相关时也是如此。我们在这些选择模型中引入了一种新的随机效应方法,该方法克服了现有方法中由共线性、小样本偏差和错误推断导致的不收敛问题。我们的方法易于在标准统计软件中实现,并允许构建经自抽样调整的标准误差,以适应检测与艾滋病毒感染状况之间的关系不确定且需要估计这一事实。
利用人口与健康调查的全国代表性数据,我们通过新的点估计值和加纳(2003年)及赞比亚(2007年)男性艾滋病毒流行率的置信区间(CI)来说明我们的方法。在加纳,我们几乎没有发现选择偏倚的证据,因为我们的选择模型得出的艾滋病毒流行率估计值为1.4%(95%CI为1.2% - 1.6%),而有有效艾滋病毒检测结果的人群中这一比例为1.6%。在赞比亚,我们的选择模型得出的艾滋病毒流行率估计值为16.3%(95%CI为11.0% - 18.4%),而有有效艾滋病毒检测结果的人群中这一比例为12.1%。因此,发现赞比亚那些拒绝检测的人感染艾滋病毒呈阳性的可能性更大。
我们的方法校正了艾滋病毒流行率估计中的选择偏倚,即使在艾滋病毒流行率或未参与检测率非常高或非常低的情况下也有可能实施,并为在估计置信区间时考虑抽样和参数不确定性提供了一个切实可行的解决方案。在一个艾滋病毒高流行率的例子中估计出的宽置信区间表明,当很大一部分人拒绝检测时,很难从统计学上校正可能出现的偏差。