Nguyen Thanh-Tung, Huang Joshua Zhexue, Nguyen Thuy Thi
Shenzhen Key Laboratory of High Performance Data Mining, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen 518055, China ; University of Chinese Academy of Sciences, Beijing 100049, China ; School of Computer Science and Engineering, Water Resources University, Hanoi 10000, Vietnam.
Shenzhen Key Laboratory of High Performance Data Mining, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen 518055, China ; College of Computer Science and Software Engineering, Shenzhen University, Shenzhen 518060, China.
ScientificWorldJournal. 2015;2015:471371. doi: 10.1155/2015/471371. Epub 2015 Mar 24.
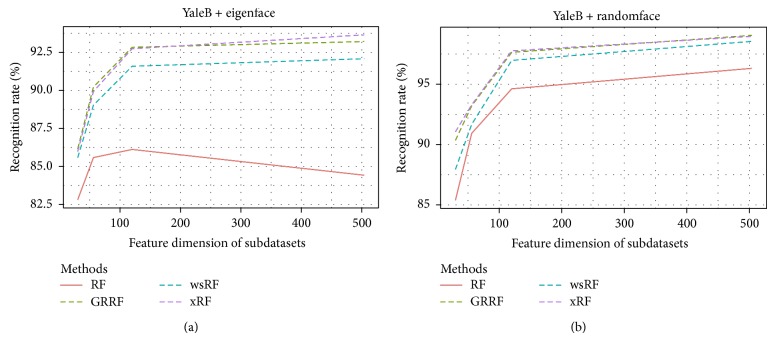
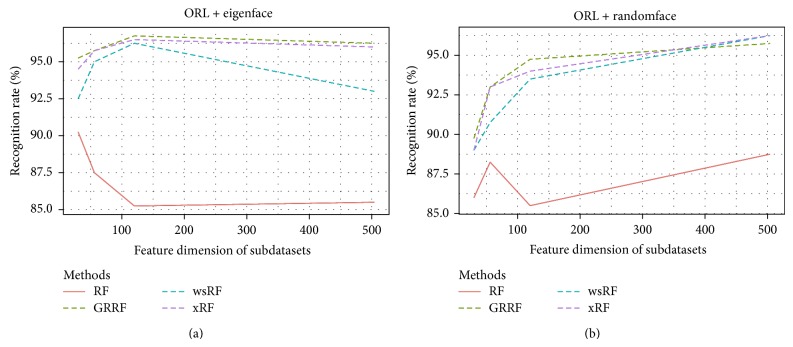
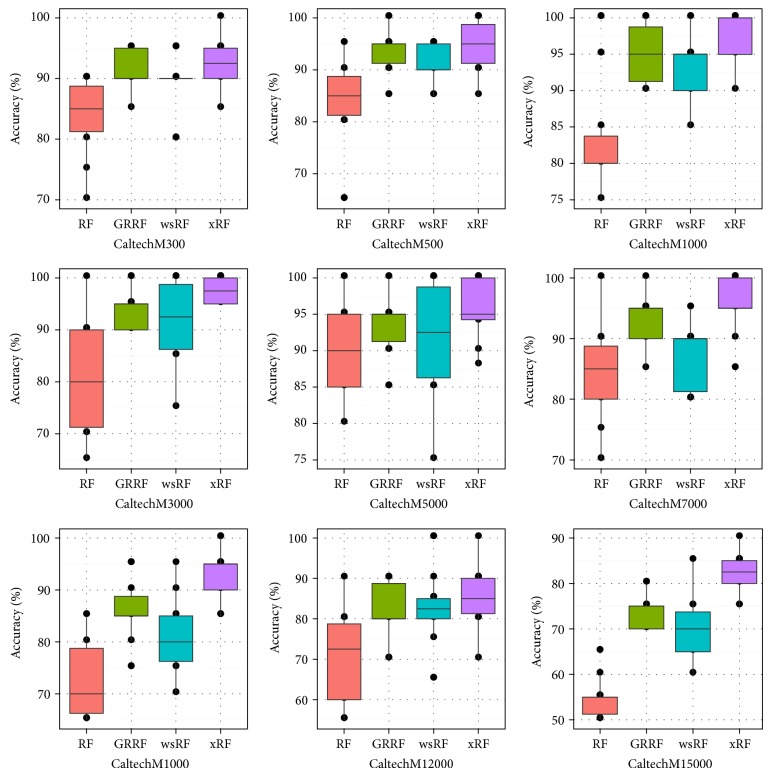
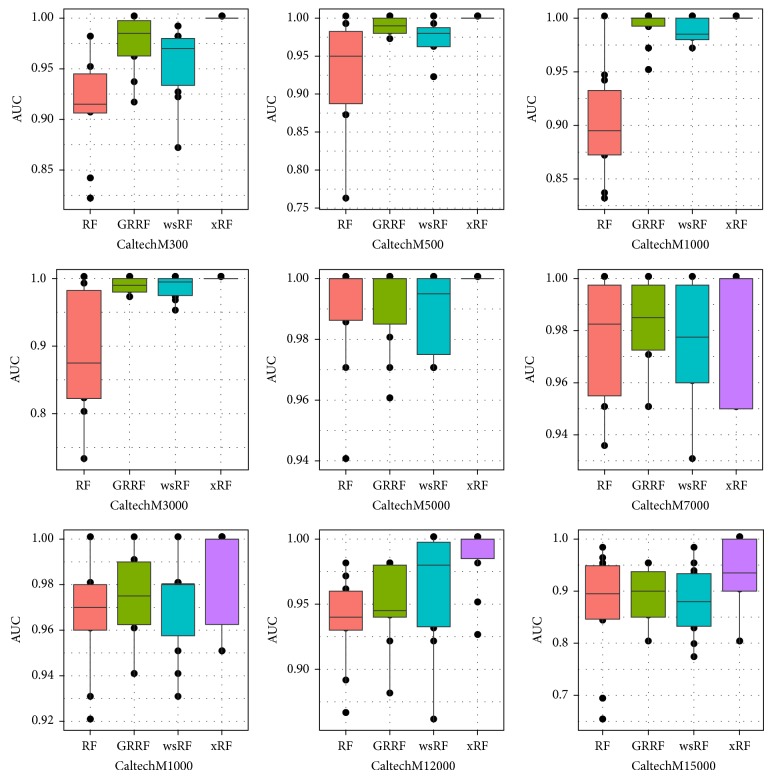
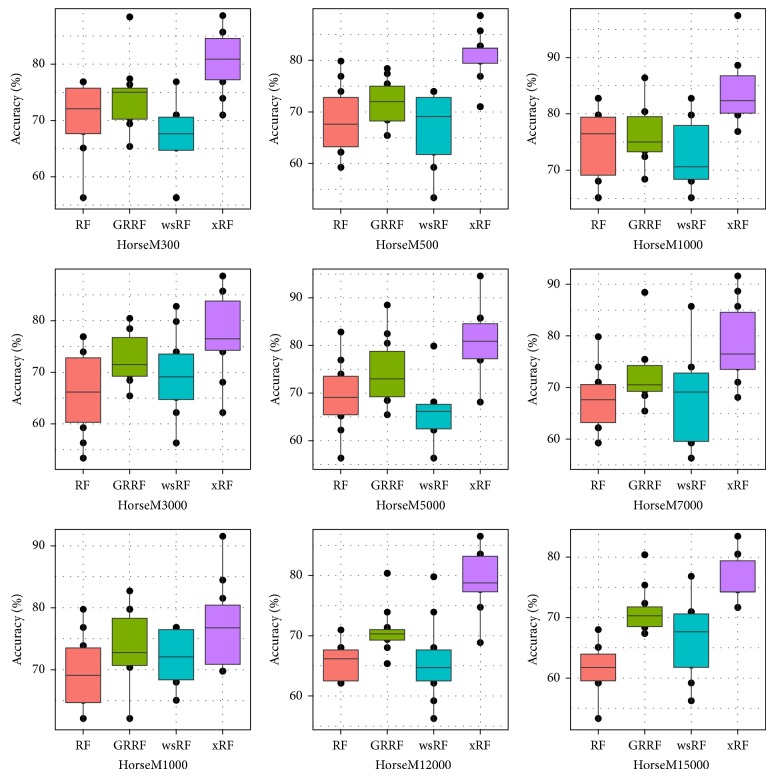
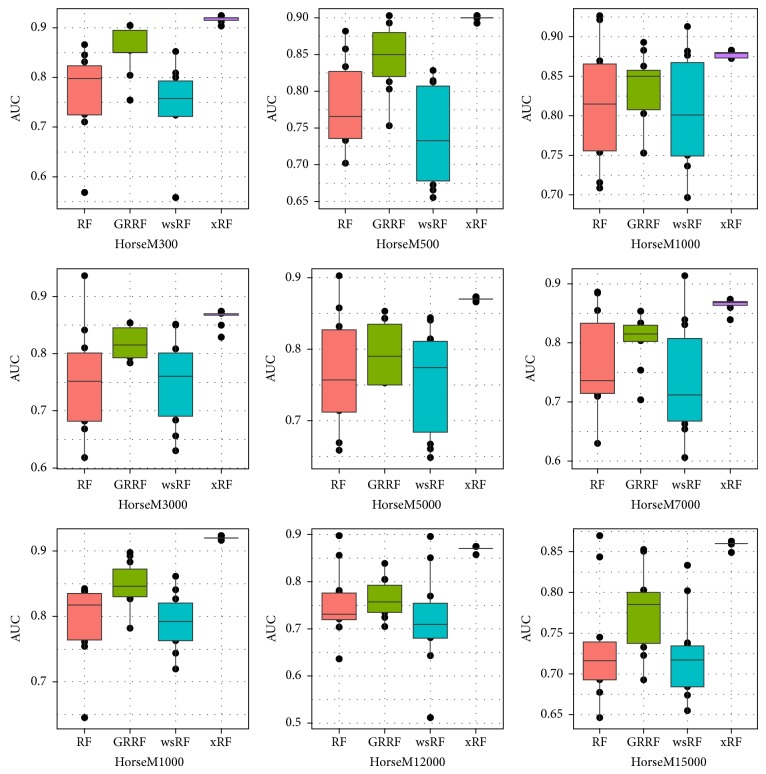
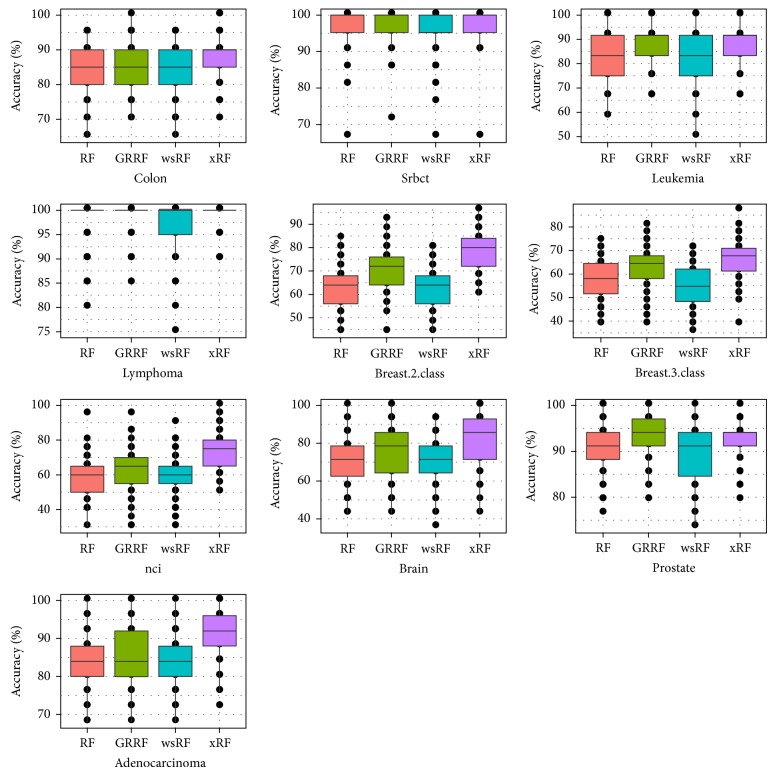
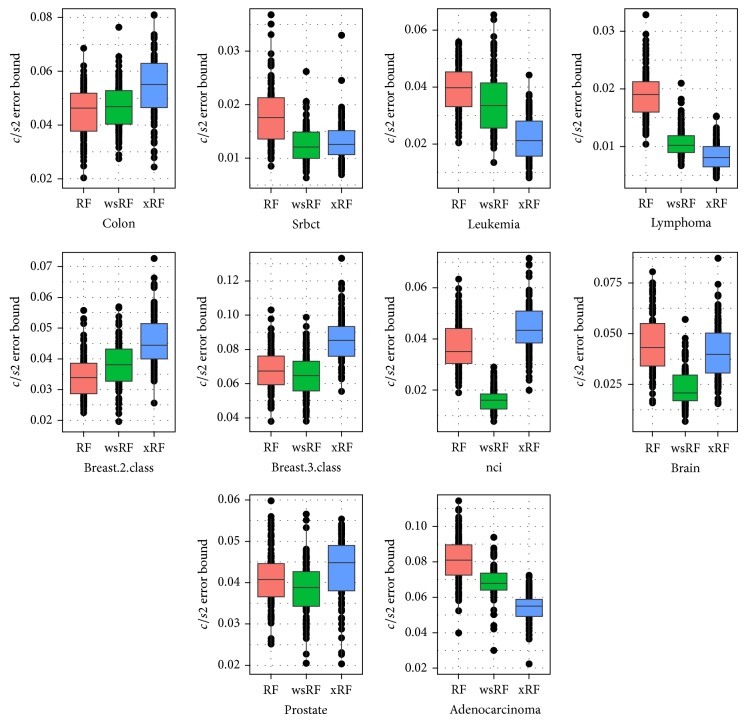
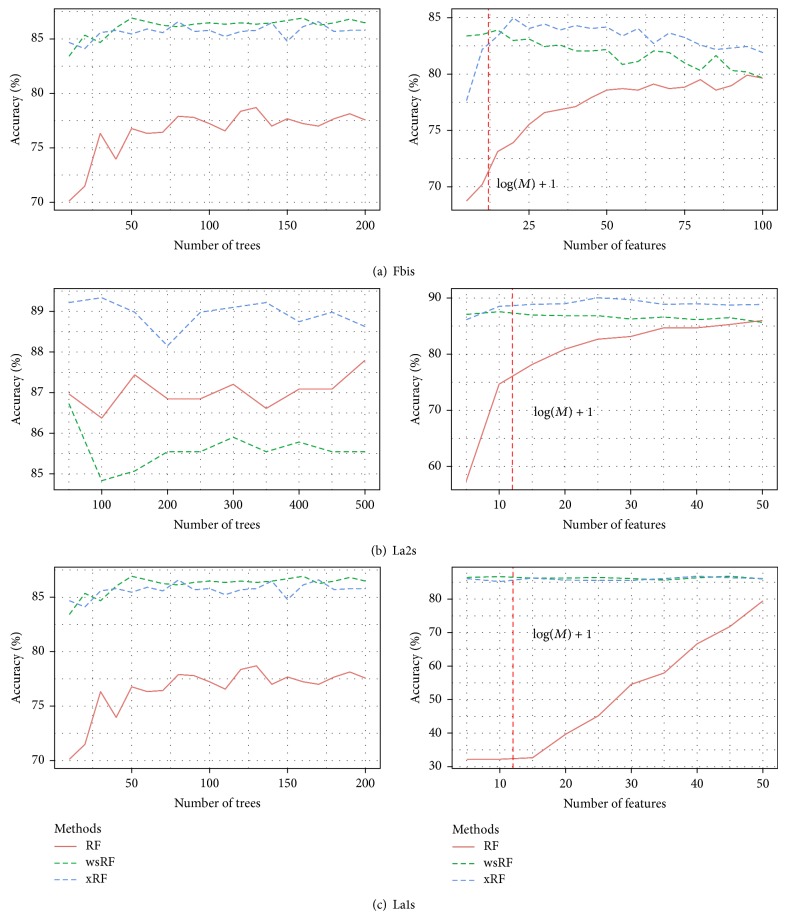
Random forests (RFs) have been widely used as a powerful classification method. However, with the randomization in both bagging samples and feature selection, the trees in the forest tend to select uninformative features for node splitting. This makes RFs have poor accuracy when working with high-dimensional data. Besides that, RFs have bias in the feature selection process where multivalued features are favored. Aiming at debiasing feature selection in RFs, we propose a new RF algorithm, called xRF, to select good features in learning RFs for high-dimensional data. We first remove the uninformative features using p-value assessment, and the subset of unbiased features is then selected based on some statistical measures. This feature subset is then partitioned into two subsets. A feature weighting sampling technique is used to sample features from these two subsets for building trees. This approach enables one to generate more accurate trees, while allowing one to reduce dimensionality and the amount of data needed for learning RFs. An extensive set of experiments has been conducted on 47 high-dimensional real-world datasets including image datasets. The experimental results have shown that RFs with the proposed approach outperformed the existing random forests in increasing the accuracy and the AUC measures.
随机森林(RFs)作为一种强大的分类方法已被广泛应用。然而,由于在装袋样本和特征选择中都存在随机性,森林中的树倾向于选择无信息的特征进行节点分裂。这使得随机森林在处理高维数据时准确性较差。除此之外,随机森林在特征选择过程中存在偏差,其中多值特征受到青睐。为了消除随机森林中特征选择的偏差,我们提出了一种新的随机森林算法,称为xRF,用于在学习高维数据的随机森林时选择良好的特征。我们首先使用p值评估去除无信息的特征,然后基于一些统计量选择无偏差特征的子集。然后将这个特征子集划分为两个子集。使用特征加权采样技术从这两个子集中采样特征来构建树。这种方法能够生成更准确的树,同时允许降低维度以及减少学习随机森林所需的数据量。我们在包括图像数据集在内的47个高维真实世界数据集上进行了大量实验。实验结果表明,采用所提出方法的随机森林在提高准确性和AUC指标方面优于现有的随机森林。