Wang Tianmin, Mori Hiroshi, Zhang Chong, Kurokawa Ken, Xing Xin-Hui, Yamada Takuji
Department of Biological Information, Graduate School of Bioscience and Biotechnology, Tokyo Institute of Technology, 2-12-1 M6-3, Ookayama, Meguro-ku, Tokyo, 152-8550, Japan.
Department of Chemical Engineering, Tsinghua University, Beijing, 100084, China.
BMC Bioinformatics. 2015 Mar 21;16:96. doi: 10.1186/s12859-015-0499-y.
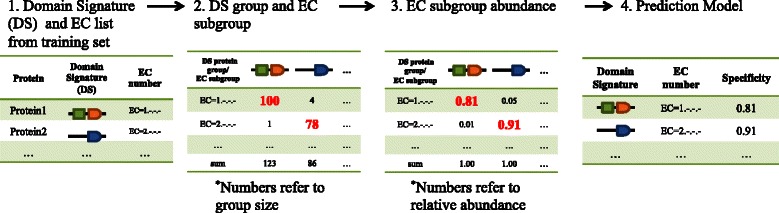
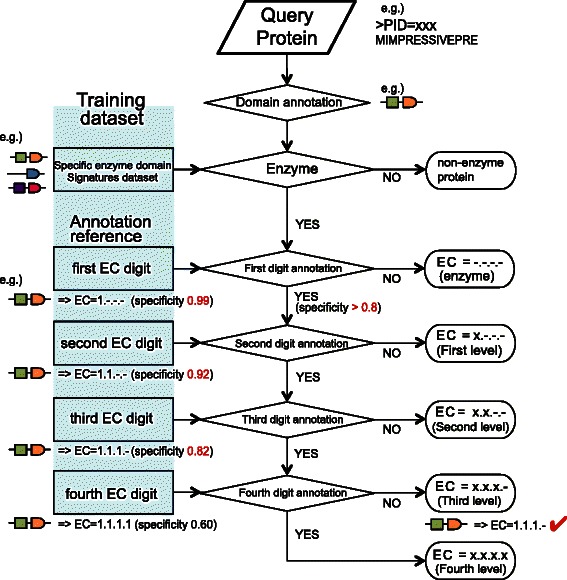
Computational predictions of catalytic function are vital for in-depth understanding of enzymes. Because several novel approaches performing better than the common BLAST tool are rarely applied in research, we hypothesized that there is a large gap between the number of known annotated enzymes and the actual number in the protein universe, which significantly limits our ability to extract additional biologically relevant functional information from the available sequencing data. To reliably expand the enzyme space, we developed DomSign, a highly accurate domain signature-based enzyme functional prediction tool to assign Enzyme Commission (EC) digits.
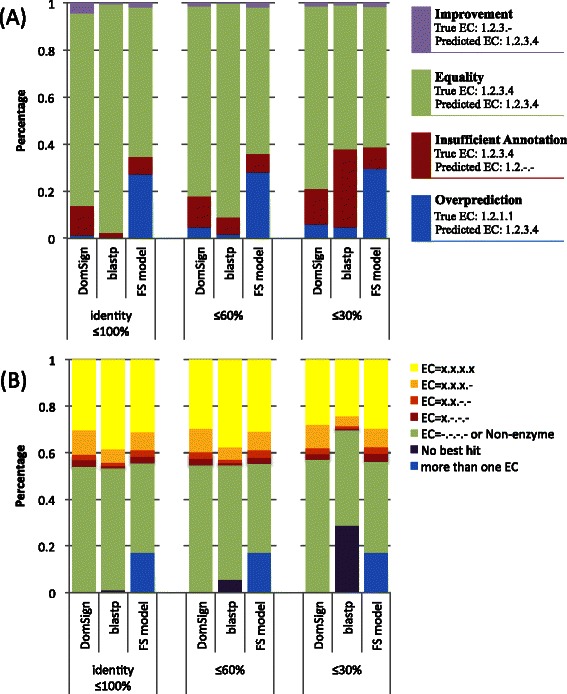
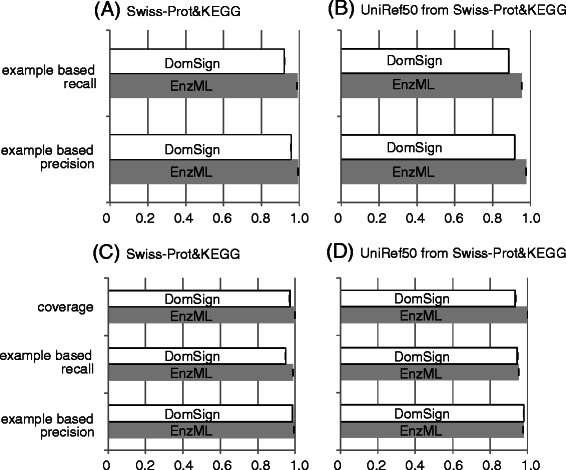
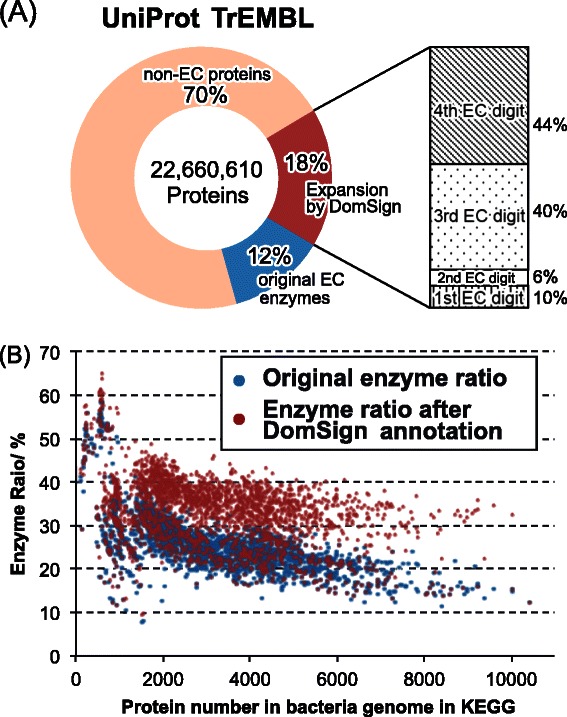
DomSign is a top-down prediction engine that yields results comparable, or superior, to those from many benchmark EC number prediction tools, including BLASTP, when a homolog with an identity >30% is not available in the database. Performance tests showed that DomSign is a highly reliable enzyme EC number annotation tool. After multiple tests, the accuracy is thought to be greater than 90%. Thus, DomSign can be applied to large-scale datasets, with the goal of expanding the enzyme space with high fidelity. Using DomSign, we successfully increased the percentage of EC-tagged enzymes from 12% to 30% in UniProt-TrEMBL. In the Kyoto Encyclopedia of Genes and Genomes bacterial database, the percentage of EC-tagged enzymes for each bacterial genome could be increased from 26.0% to 33.2% on average. Metagenomic mining was also efficient, as exemplified by the application of DomSign to the Human Microbiome Project dataset, recovering nearly one million new EC-labeled enzymes.
Our results offer preliminarily confirmation of the existence of the hypothesized huge number of "hidden enzymes" in the protein universe, the identification of which could substantially further our understanding of the metabolisms of diverse organisms and also facilitate bioengineering by providing a richer enzyme resource. Furthermore, our results highlight the necessity of using more advanced computational tools than BLAST in protein database annotations to extract additional biologically relevant functional information from the available biological sequences.
催化功能的计算预测对于深入理解酶至关重要。由于几种比常用的BLAST工具性能更好的新方法在研究中很少被应用,我们推测已知注释酶的数量与蛋白质宇宙中的实际数量之间存在很大差距,这严重限制了我们从现有测序数据中提取更多生物学相关功能信息的能力。为了可靠地扩展酶空间,我们开发了DomSign,这是一种基于结构域特征的高精度酶功能预测工具,用于分配酶委员会(EC)编号。
DomSign是一种自上而下的预测引擎,当数据库中不存在同一性>30%的同源物时,其产生的结果与许多基准EC编号预测工具(包括BLASTP)的结果相当或更优。性能测试表明,DomSign是一种高度可靠的酶EC编号注释工具。经过多次测试,其准确率被认为大于90%。因此,DomSign可应用于大规模数据集,目标是以高保真度扩展酶空间。使用DomSign,我们成功地将UniProt-TrEMBL中带有EC标签的酶的百分比从12%提高到了30%。在京都基因与基因组百科全书细菌数据库中,每个细菌基因组中带有EC标签的酶的百分比平均可从26.0%提高到33.2%。宏基因组挖掘也很有效,例如将DomSign应用于人类微生物组计划数据集,发现了近100万个新的带有EC标签的酶。
我们的结果初步证实了蛋白质宇宙中存在大量假设的“隐藏酶”,对其进行鉴定可以极大地增进我们对不同生物体代谢的理解,还可以通过提供更丰富的酶资源促进生物工程。此外,我们的结果凸显了在蛋白质数据库注释中使用比BLAST更先进的计算工具以从现有生物序列中提取更多生物学相关功能信息的必要性。