Al-Hebshi Nezar Noor, Nasher Akram Thabet, Idris Ali Mohamed, Chen Tsute
Department of Preventive Dentistry, Faculty of Dentistry, Jazan University, Jazan, Kingdom of Saudi Arabia;
Department of Oral and Maxillofacial Surgery, Faculty of Dentistry, Sana'a University, Sana'a, Yemen.
J Oral Microbiol. 2015 Sep 29;7:28934. doi: 10.3402/jom.v7.28934. eCollection 2015.
Usefulness of next-generation sequencing (NGS) in assessing bacteria associated with oral squamous cell carcinoma (OSCC) has been undermined by inability to classify reads to the species level.
The purpose of this study was to develop a robust algorithm for species-level classification of NGS reads from oral samples and to pilot test it for profiling bacteria within OSCC tissues.
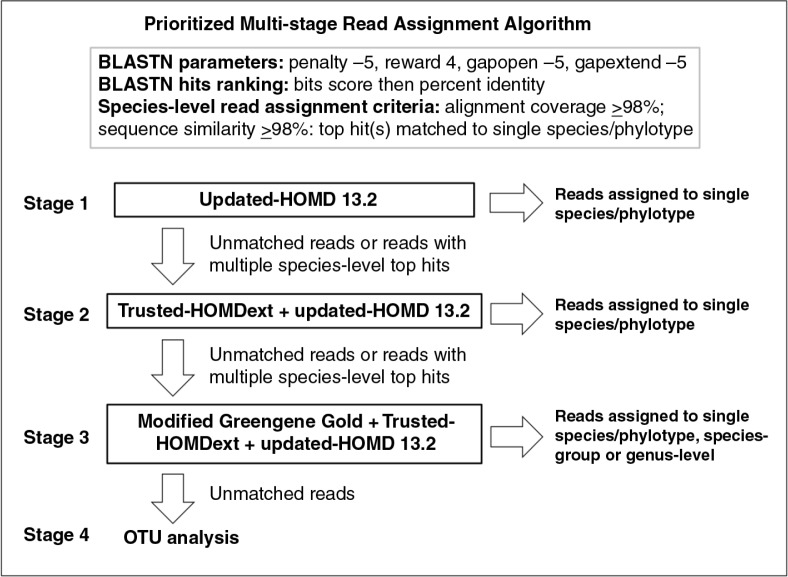
Bacterial 16S V1-V3 libraries were prepared from three OSCC DNA samples and sequenced using 454's FLX chemistry. High-quality, well-aligned, and non-chimeric reads ≥350 bp were classified using a novel, multi-stage algorithm that involves matching reads to reference sequences in revised versions of the Human Oral Microbiome Database (HOMD), HOMD extended (HOMDEXT), and Greengene Gold (GGG) at alignment coverage and percentage identity ≥98%, followed by assignment to species level based on top hit reference sequences. Priority was given to hits in HOMD, then HOMDEXT and finally GGG. Unmatched reads were subject to operational taxonomic unit analysis.
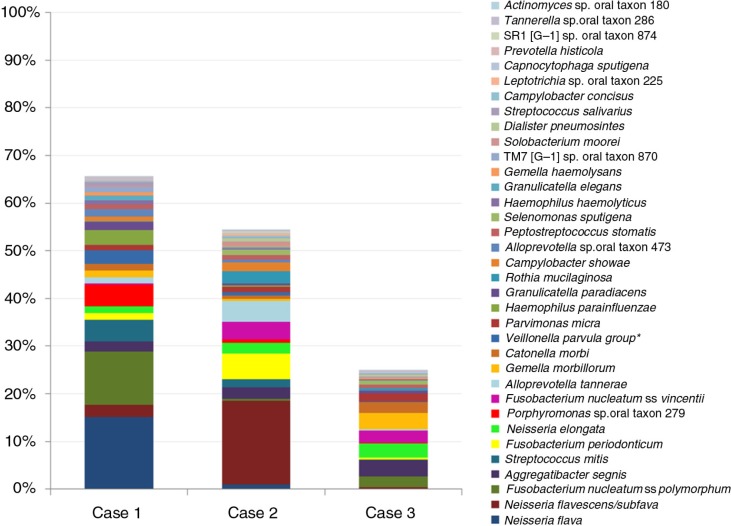
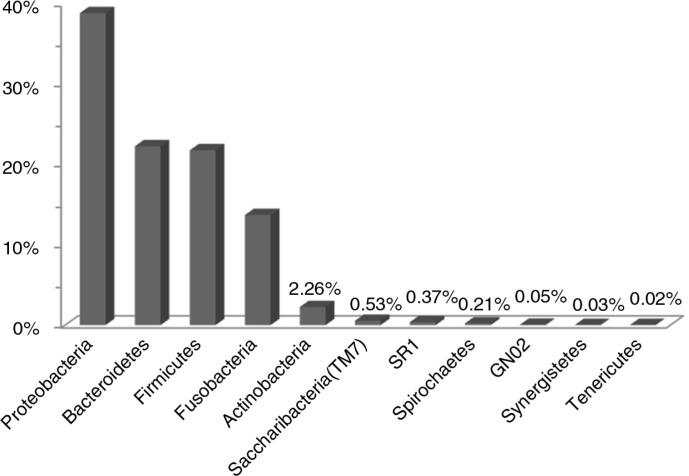
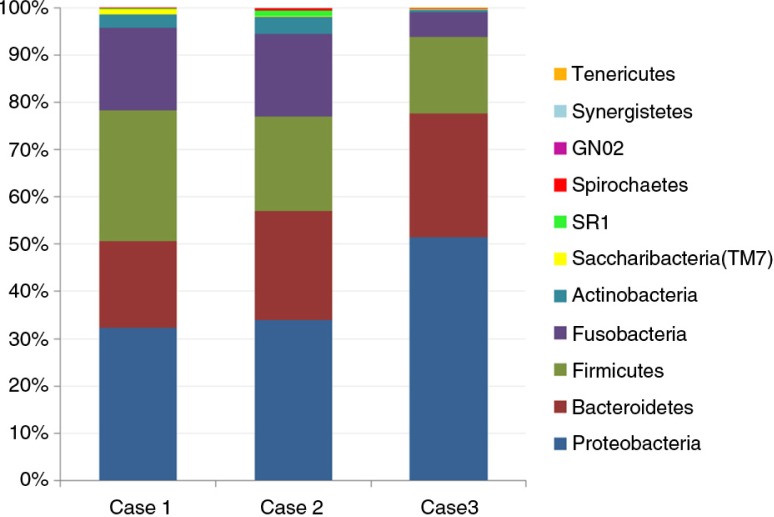
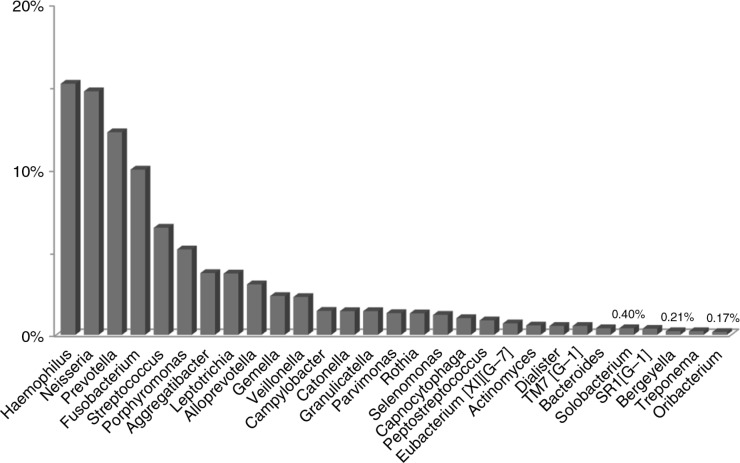
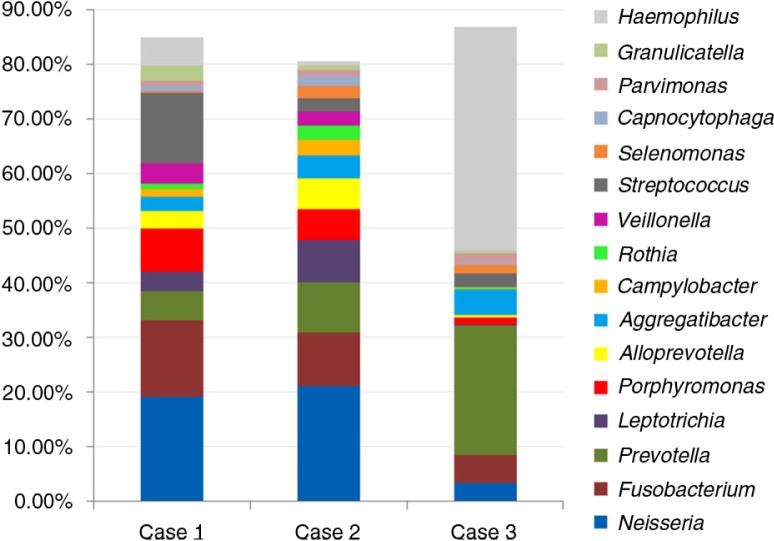
Nearly, 92.8% of the reads were matched to updated-HOMD 13.2, 1.83% to trusted-HOMDEXT, and 1.36% to modified-GGG. Of all matched reads, 99.6% were classified to species level. A total of 228 species-level taxa were identified, representing 11 phyla; the most abundant were Proteobacteria, Bacteroidetes, Firmicutes, Fusobacteria, and Actinobacteria. Thirty-five species-level taxa were detected in all samples. On average, Prevotella oris, Neisseria flava, Neisseria flavescens/subflava, Fusobacterium nucleatum ss polymorphum, Aggregatibacter segnis, Streptococcus mitis, and Fusobacterium periodontium were the most abundant. Bacteroides fragilis, a species rarely isolated from the oral cavity, was detected in two samples.
This multi-stage algorithm maximizes the fraction of reads classified to the species level while ensuring reliable classification by giving priority to the human, oral reference set. Applying the algorithm to OSCC samples revealed high diversity. In addition to oral taxa, a number of human, non-oral taxa were also identified, some of which are rarely detected in the oral cavity.
下一代测序(NGS)在评估与口腔鳞状细胞癌(OSCC)相关的细菌时,因无法将读数分类到物种水平而受到影响。
本研究的目的是开发一种强大的算法,用于对口腔样本的NGS读数进行物种水平分类,并对其在OSCC组织内细菌谱分析进行初步测试。
从三个OSCC DNA样本中制备细菌16S V1-V3文库,并使用454的FLX化学方法进行测序。使用一种新颖的多阶段算法对长度≥350 bp的高质量、排列良好且无嵌合体的读数进行分类,该算法包括将读数与人类口腔微生物组数据库(HOMD)修订版、扩展的HOMD(HOMDEXT)和Greengene Gold(GGG)中的参考序列进行匹配,比对覆盖率和百分比一致性≥98%,然后根据最佳匹配参考序列将其分类到物种水平。优先考虑HOMD中的匹配,然后是HOMDEXT,最后是GGG。不匹配的读数进行操作分类单元分析。
近92.8%的读数与更新后的HOMD 13.2匹配,1.83%与可信的HOMDEXT匹配,1.36%与修改后的GGG匹配。在所有匹配的读数中,99.6%被分类到物种水平。总共鉴定出228个物种水平的分类单元,代表11个门;最丰富的是变形菌门、拟杆菌门、厚壁菌门、梭杆菌门和放线菌门。在所有样本中检测到35个物种水平的分类单元。平均而言,口腔普雷沃菌、微黄奈瑟菌、浅黄奈瑟菌/亚浅黄奈瑟菌、具核梭杆菌多态亚种、迟钝聚集杆菌、缓症链球菌和牙周梭杆菌最为丰富。脆弱拟杆菌是一种很少从口腔分离出的物种,在两个样本中被检测到。
这种多阶段算法通过优先考虑人类口腔参考集,在确保可靠分类的同时,最大限度地提高了分类到物种水平的读数比例。将该算法应用于OSCC样本显示出高度的多样性。除了口腔分类单元外,还鉴定出一些人类非口腔分类单元,其中一些在口腔中很少被检测到。