Zhu Yeying, Coffman Donna L, Ghosh Debashis
Department of Statistics and Actuarial Science, University of Waterloo, 200 University Ave W, Waterloo, ON N2L 3G1, Canada.
The Methodology Center, The Pennsylvania State University, University Park, PA, USA.
J Causal Inference. 2015 Mar 1;3(1):25-40. doi: 10.1515/jci-2014-0022. Epub 2014 Aug 1.
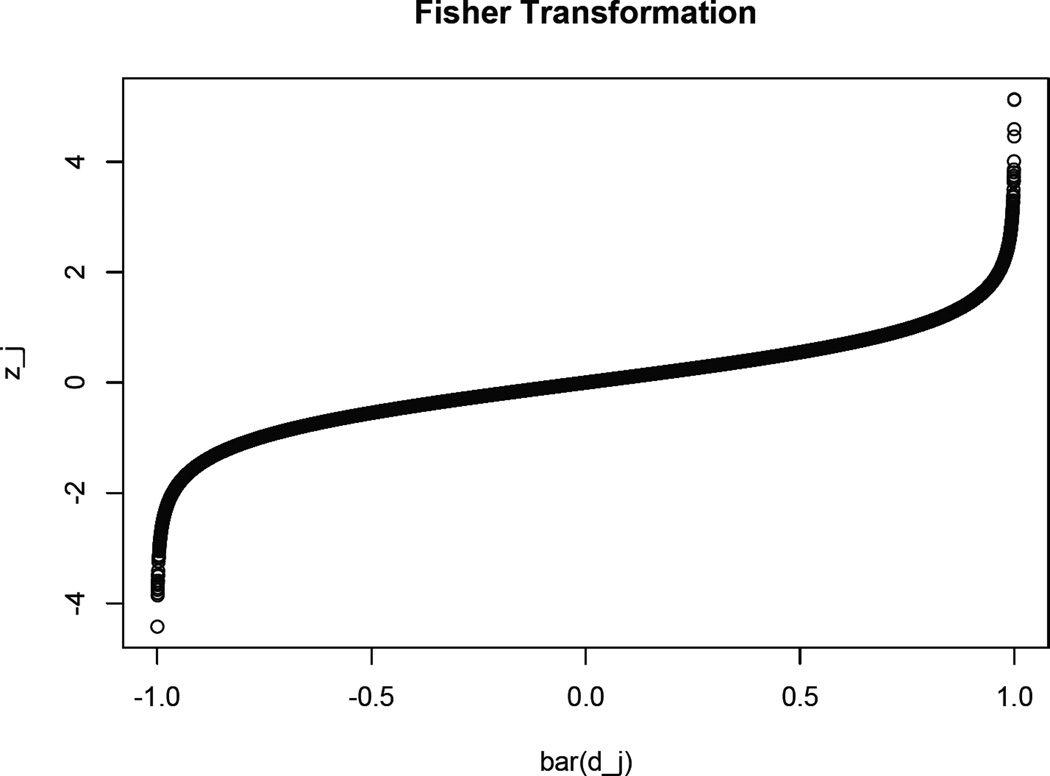
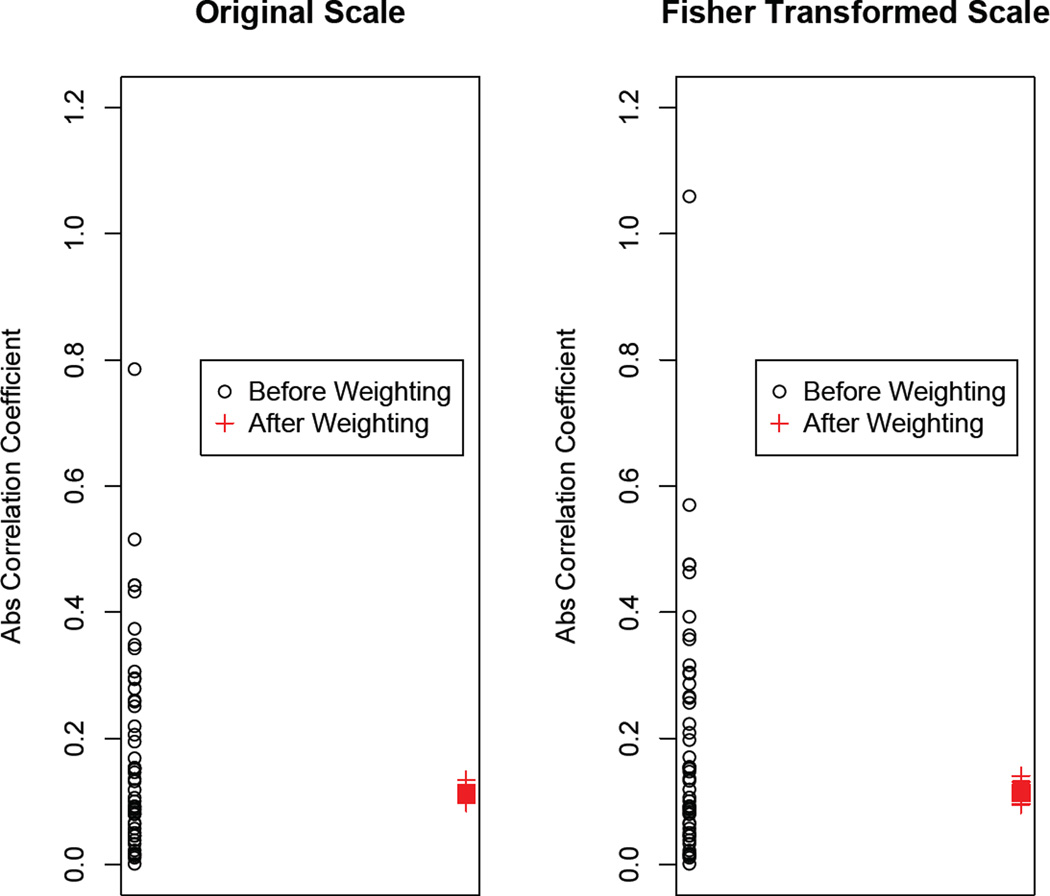
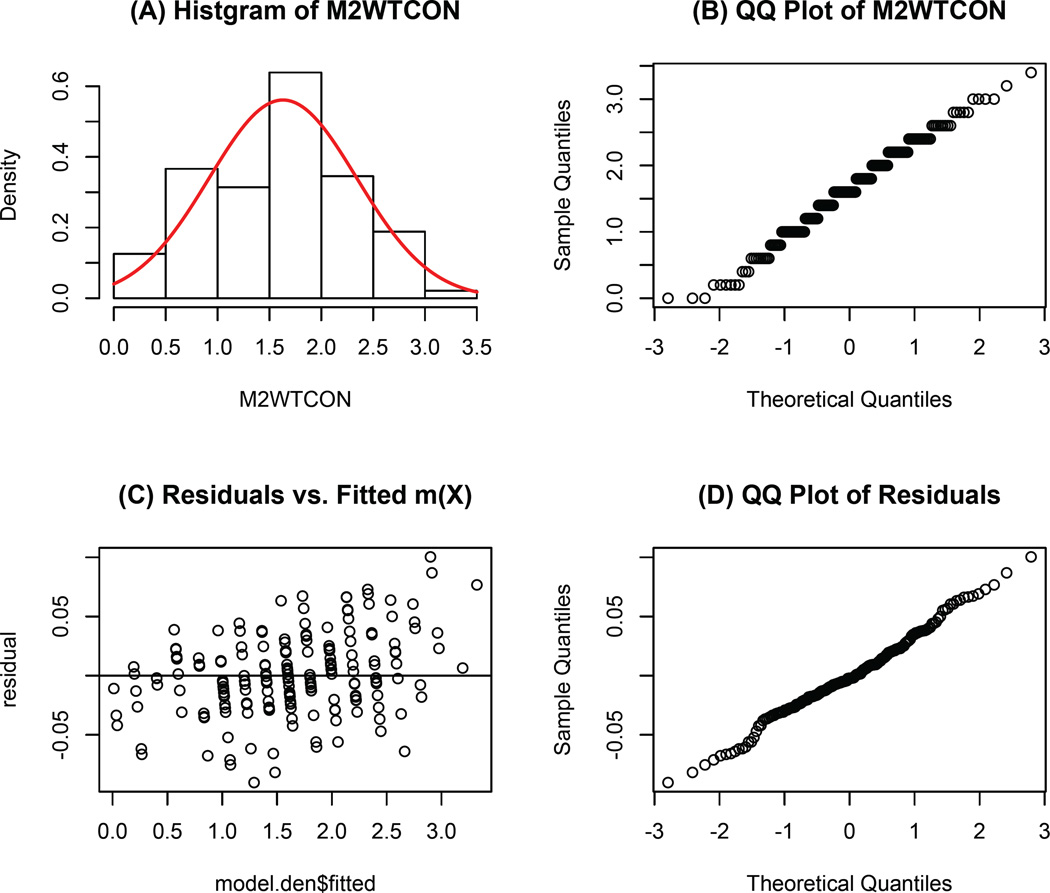
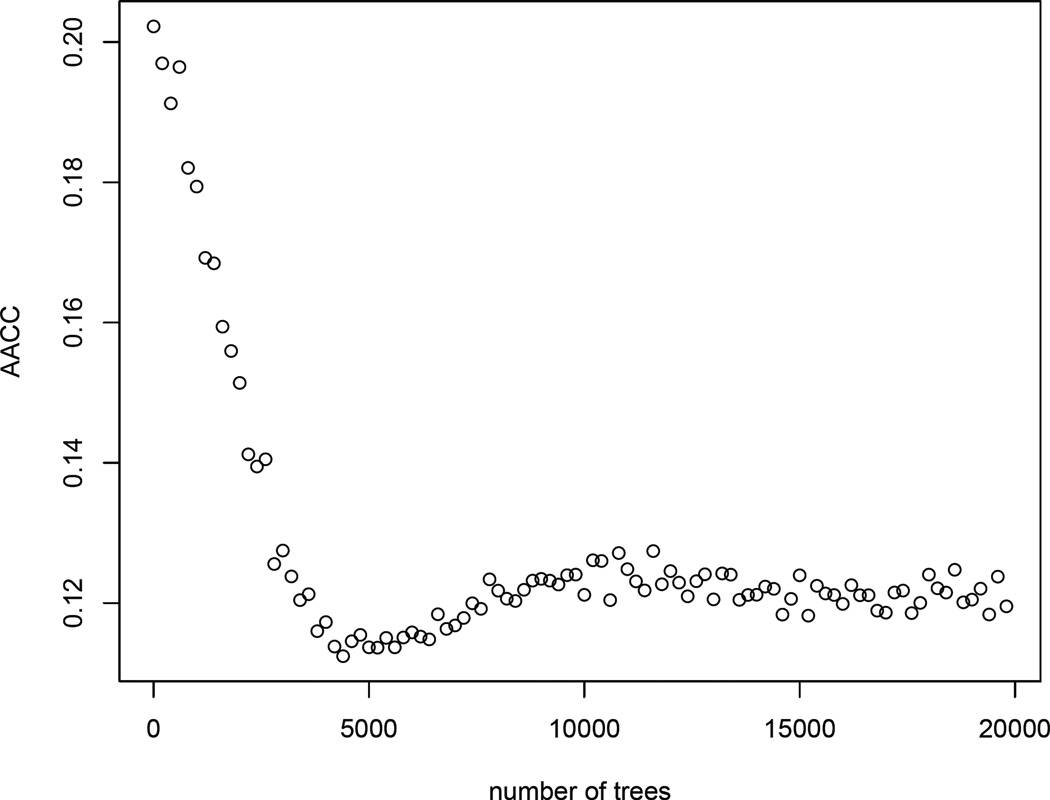
In this article, we study the causal inference problem with a continuous treatment variable using propensity score-based methods. For a continuous treatment, the generalized propensity score is defined as the conditional density of the treatment-level given covariates (confounders). The dose-response function is then estimated by inverse probability weighting, where the weights are calculated from the estimated propensity scores. When the dimension of the covariates is large, the traditional nonparametric density estimation suffers from the curse of dimensionality. Some researchers have suggested a two-step estimation procedure by first modeling the mean function. In this study, we suggest a boosting algorithm to estimate the mean function of the treatment given covariates. In boosting, an important tuning parameter is the number of trees to be generated, which essentially determines the trade-off between bias and variance of the causal estimator. We propose a criterion called average absolute correlation coefficient (AACC) to determine the optimal number of trees. Simulation results show that the proposed approach performs better than a simple linear approximation or L2 boosting. The proposed methodology is also illustrated through the Early Dieting in Girls study, which examines the influence of mothers' overall weight concern on daughters' dieting behavior.
在本文中,我们使用基于倾向得分的方法研究具有连续处理变量的因果推断问题。对于连续处理,广义倾向得分被定义为给定协变量(混杂因素)时处理水平的条件密度。然后通过逆概率加权估计剂量反应函数,其中权重是根据估计的倾向得分计算得出的。当协变量的维度很大时,传统的非参数密度估计会受到维度诅咒的影响。一些研究人员提出了一种两步估计程序,首先对均值函数进行建模。在本研究中,我们提出一种提升算法来估计给定协变量时处理的均值函数。在提升算法中,一个重要的调优参数是要生成的树的数量,它本质上决定了因果估计量偏差和方差之间的权衡。我们提出一种称为平均绝对相关系数(AACC)的准则来确定最优树的数量。模拟结果表明,所提出的方法比简单线性近似或L2提升表现更好。还通过女孩早期节食研究对所提出的方法进行了说明,该研究考察了母亲对总体体重的关注对女儿节食行为的影响。