Wang Zichen, Monteiro Caroline D, Jagodnik Kathleen M, Fernandez Nicolas F, Gundersen Gregory W, Rouillard Andrew D, Jenkins Sherry L, Feldmann Axel S, Hu Kevin S, McDermott Michael G, Duan Qiaonan, Clark Neil R, Jones Matthew R, Kou Yan, Goff Troy, Woodland Holly, Amaral Fabio M R, Szeto Gregory L, Fuchs Oliver, Schüssler-Fiorenza Rose Sophia M, Sharma Shvetank, Schwartz Uwe, Bausela Xabier Bengoetxea, Szymkiewicz Maciej, Maroulis Vasileios, Salykin Anton, Barra Carolina M, Kruth Candice D, Bongio Nicholas J, Mathur Vaibhav, Todoric Radmila D, Rubin Udi E, Malatras Apostolos, Fulp Carl T, Galindo John A, Motiejunaite Ruta, Jüschke Christoph, Dishuck Philip C, Lahl Katharina, Jafari Mohieddin, Aibar Sara, Zaravinos Apostolos, Steenhuizen Linda H, Allison Lindsey R, Gamallo Pablo, de Andres Segura Fernando, Dae Devlin Tyler, Pérez-García Vicente, Ma'ayan Avi
Department of Pharmacological Sciences, BD2K-LINCS Data Coordination and Integration Center, Illuminating the Druggable Genome Knowledge Management Center, Icahn School of Medicine at Mount Sinai, One Gustave L. Levy Place Box 1215, New York, New York 10029, USA.
Fluid Physics and Transport Processes Branch, NASA Glenn Research Center, 21000 Brookpark Rd, Cleveland, Ohio 44135, USA.
Nat Commun. 2016 Sep 26;7:12846. doi: 10.1038/ncomms12846.
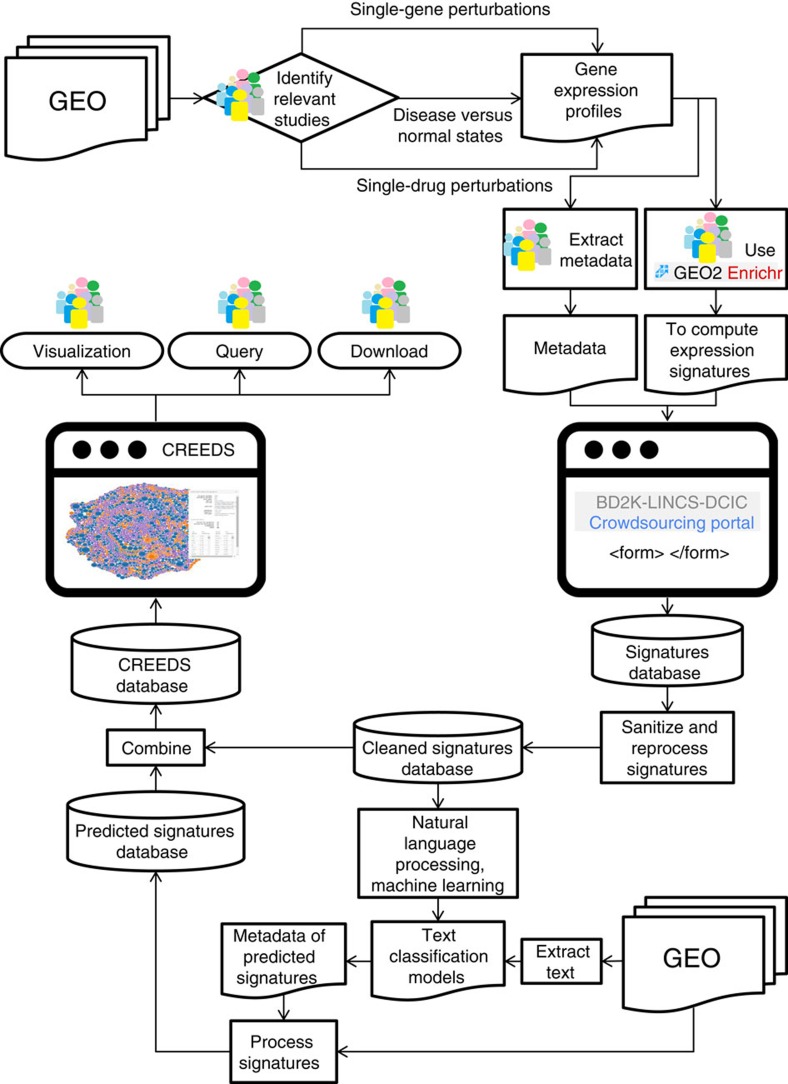
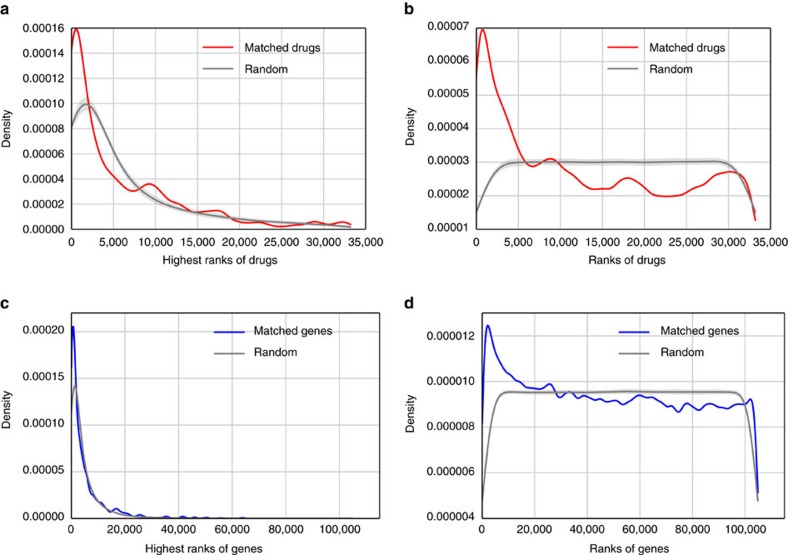
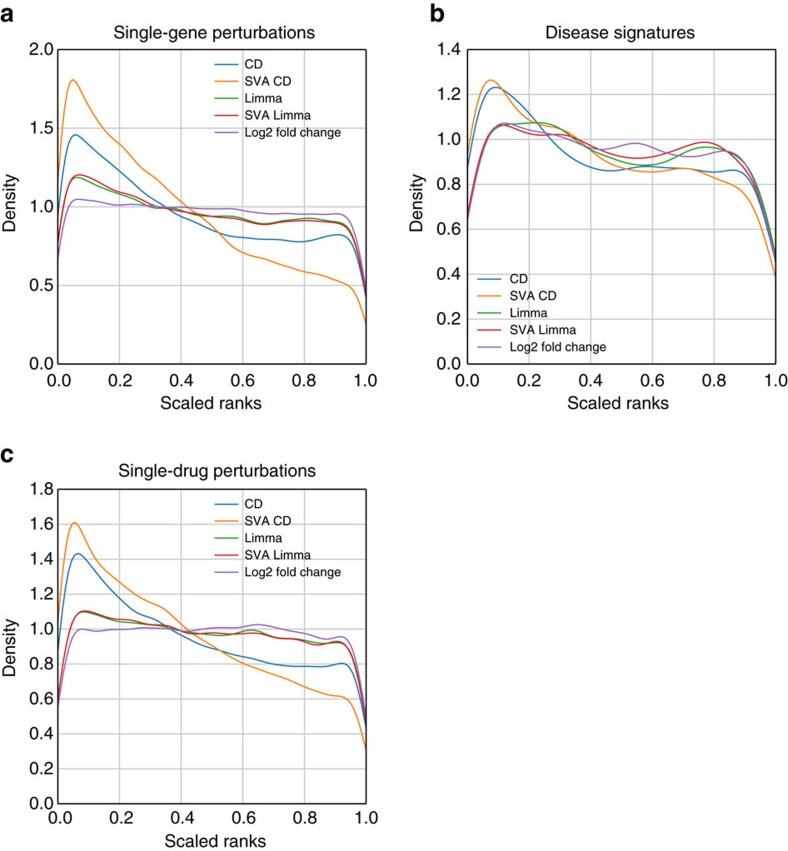
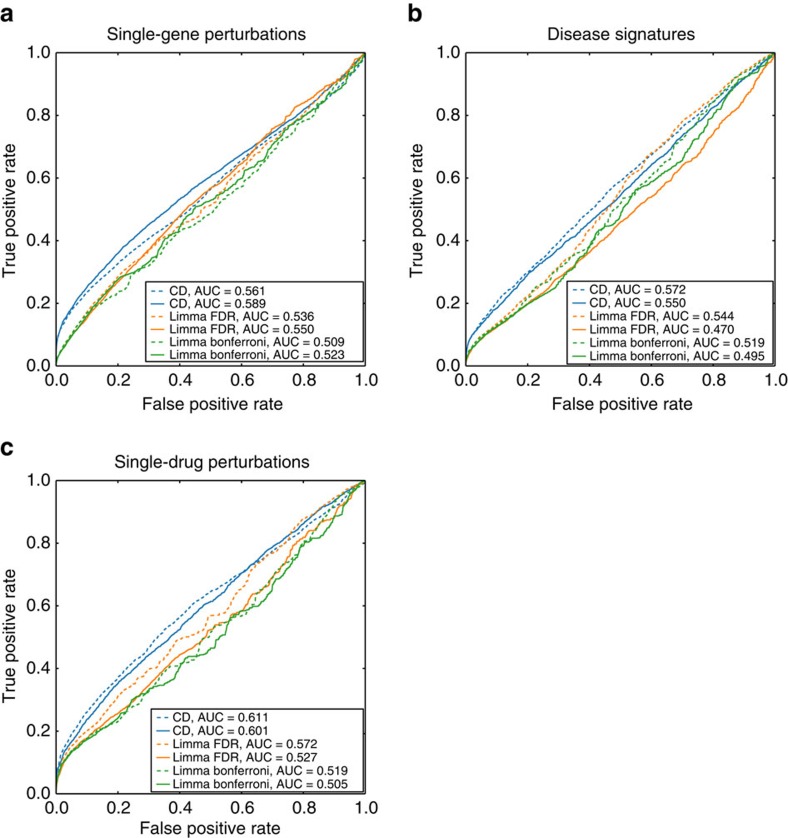
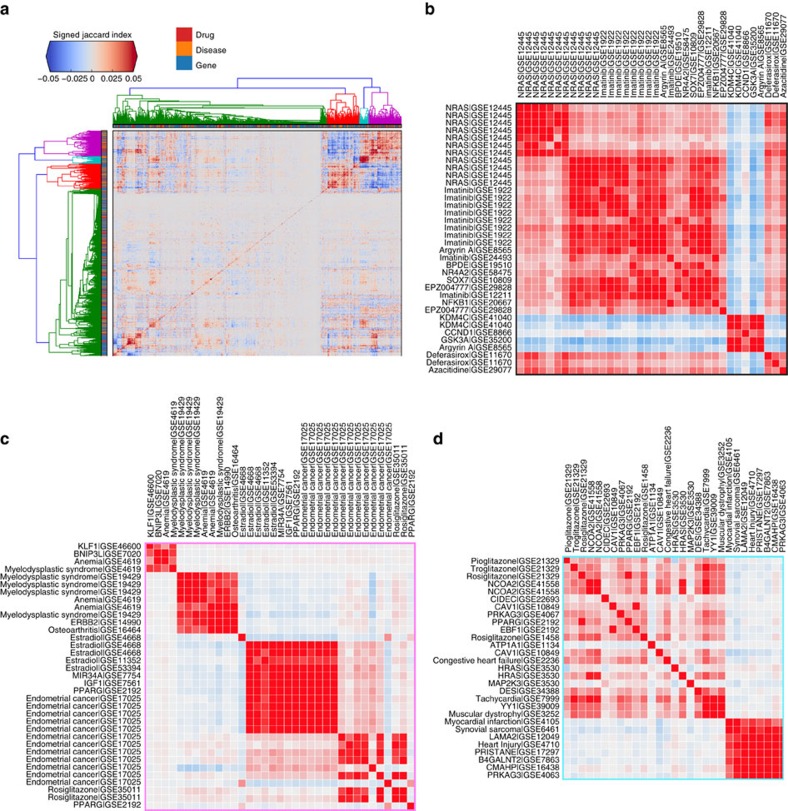
Gene expression data are accumulating exponentially in public repositories. Reanalysis and integration of themed collections from these studies may provide new insights, but requires further human curation. Here we report a crowdsourcing project to annotate and reanalyse a large number of gene expression profiles from Gene Expression Omnibus (GEO). Through a massive open online course on Coursera, over 70 participants from over 25 countries identify and annotate 2,460 single-gene perturbation signatures, 839 disease versus normal signatures, and 906 drug perturbation signatures. All these signatures are unique and are manually validated for quality. Global analysis of these signatures confirms known associations and identifies novel associations between genes, diseases and drugs. The manually curated signatures are used as a training set to develop classifiers for extracting similar signatures from the entire GEO repository. We develop a web portal to serve these signatures for query, download and visualization.
公共数据库中的基因表达数据正在呈指数级积累。对这些研究中的主题数据集进行重新分析和整合可能会提供新的见解,但需要进一步的人工整理。在此,我们报告一项众包项目,该项目对来自基因表达综合数据库(GEO)的大量基因表达谱进行注释和重新分析。通过在Coursera上开展的大规模在线开放课程,来自25个以上国家的70多名参与者识别并注释了2460个单基因扰动特征、839个疾病与正常对照特征以及906个药物扰动特征。所有这些特征都是独一无二的,并经过人工质量验证。对这些特征的全局分析证实了已知的关联,并识别出基因、疾病和药物之间的新关联。经过人工整理的特征被用作训练集,以开发用于从整个GEO数据库中提取相似特征的分类器。我们开发了一个门户网站来提供这些特征以供查询、下载和可视化。