Wu Ze-Ying, Zeng Zhong-da, Xiao Zi-Dan, Mok Daniel Kam-Wah, Liang Yi-Zeng, Chau Foo-Tim, Chan Hoi-Yan
School of Mathematics, Physics and Chemical Engineering, Changzhou Institute of Technology, Changzhou 213002, China; State Key Testing Laboratory of Food Contact Materials, Changzhou Entry-Exit Inspection and Quarantine Bureau, Changzhou 213002, China.
Chemometrics and Herbal Medicine Laboratory, Department of Applied Biology and Chemical Technology, The Hong Kong Polytechnic University, Hung Hom, Kowloon, Hong Kong; Dalian ChemDataSolution Technology Co. Ltd., High-Tech Zone, Dalian, Liaoning 116023, China.
J Anal Methods Chem. 2017;2017:9402045. doi: 10.1155/2017/9402045. Epub 2017 Jan 12.
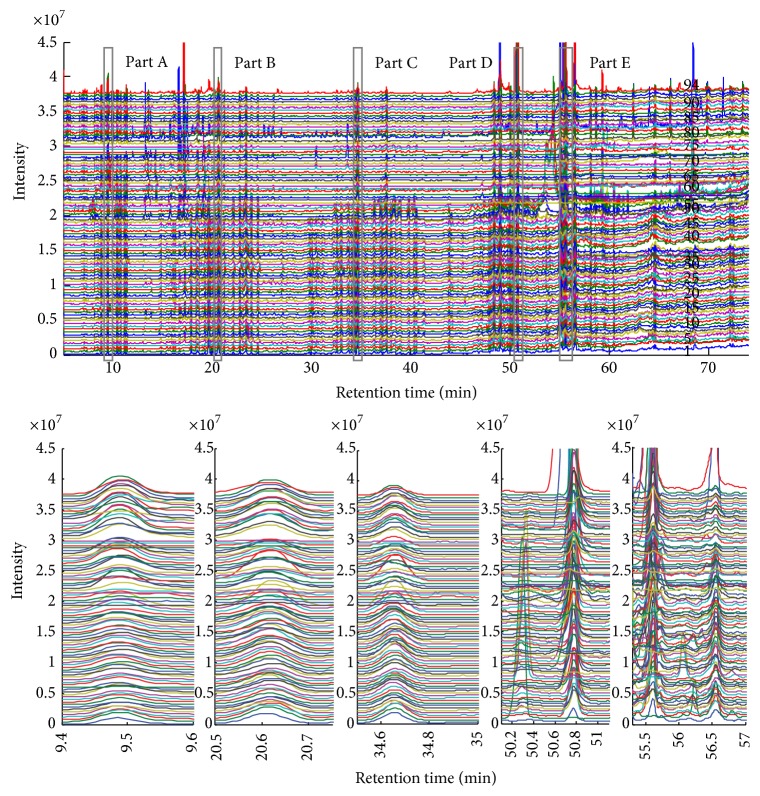
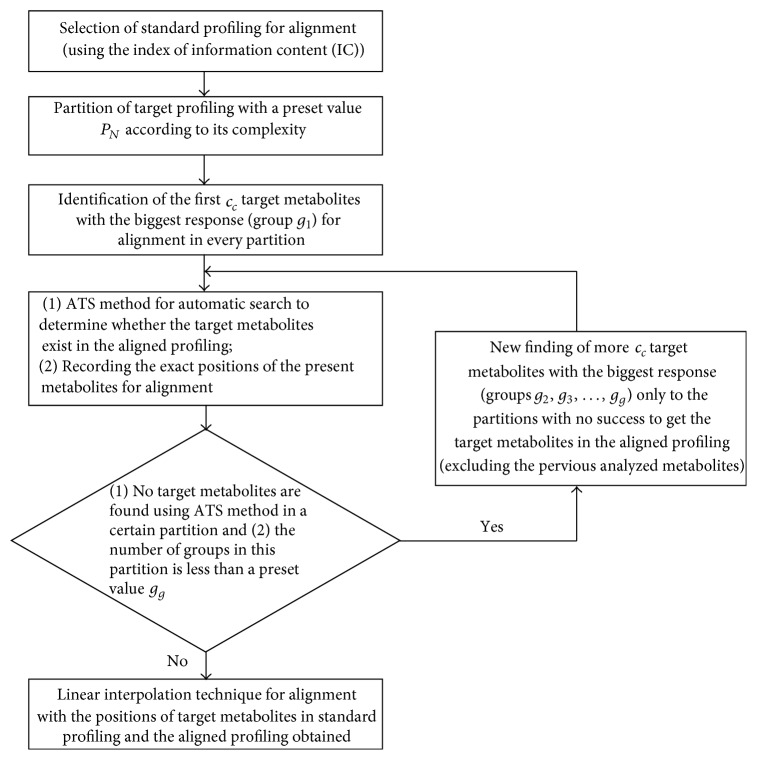
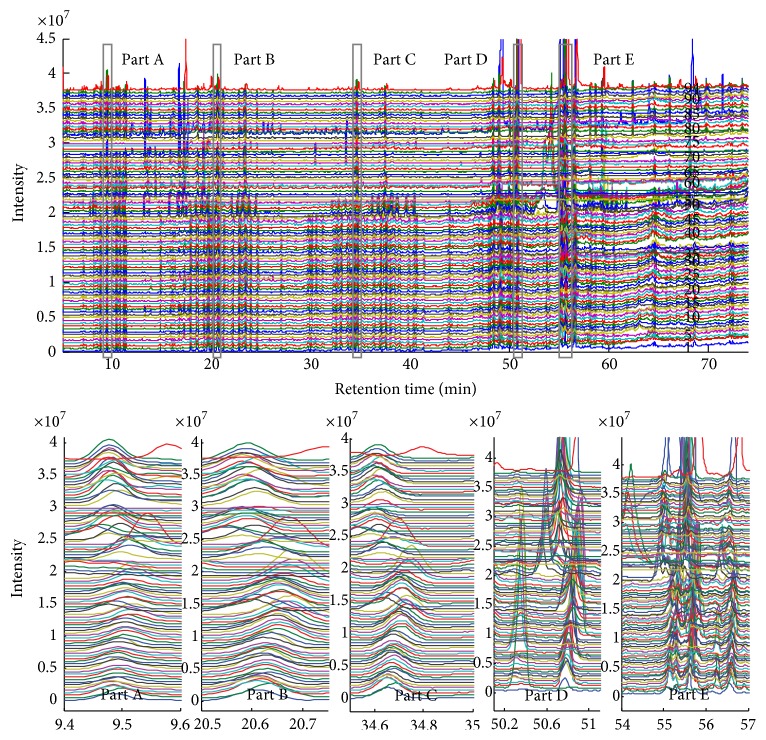
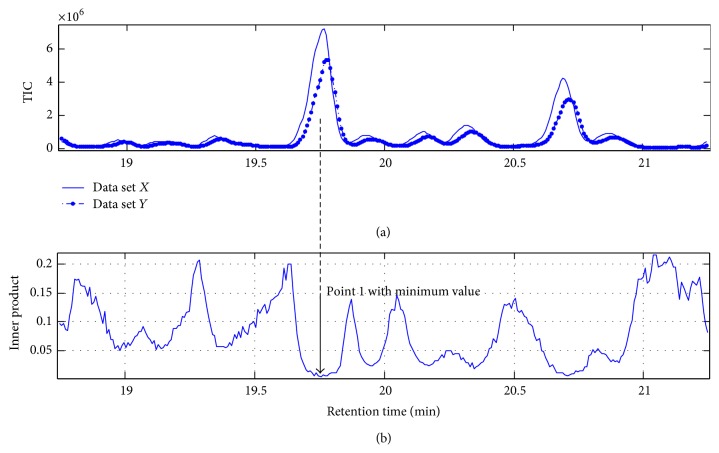
The rapid increase in the use of metabolite profiling/fingerprinting techniques to resolve complicated issues in metabolomics has stimulated demand for data processing techniques, such as alignment, to extract detailed information. In this study, a new and automated method was developed to correct the retention time shift of high-dimensional and high-throughput data sets. Information from the target chromatographic profiles was used to determine the standard profile as a reference for alignment. A novel, piecewise data partition strategy was applied for the determination of the target components in the standard profile as markers for alignment. An automated target search (ATS) method was proposed to find the exact retention times of the selected targets in other profiles for alignment. The linear interpolation technique (LIT) was employed to align the profiles prior to pattern recognition, comprehensive comparison analysis, and other data processing steps. In total, 94 metabolite profiles of ginseng were studied, including the most volatile secondary metabolites. The method used in this article could be an essential step in the extraction of information from high-throughput data acquired in the study of systems biology, metabolomics, and biomarker discovery.
代谢物谱分析/指纹识别技术在解决代谢组学复杂问题方面的应用迅速增加,这刺激了对诸如校准等数据处理技术的需求,以便提取详细信息。在本研究中,开发了一种新的自动化方法来校正高维和高通量数据集的保留时间偏移。来自目标色谱图的信息用于确定标准图谱作为校准的参考。一种新颖的分段数据划分策略被应用于确定标准图谱中的目标成分作为校准标记。提出了一种自动目标搜索(ATS)方法来找到其他图谱中所选目标的精确保留时间以进行校准。在模式识别、综合比较分析和其他数据处理步骤之前,采用线性插值技术(LIT)来校准图谱。总共研究了94个人参代谢物谱,包括最易挥发的次生代谢物。本文中使用的方法可能是从系统生物学、代谢组学和生物标志物发现研究中获取的高通量数据中提取信息的关键步骤。