Gagie Travis, Hartikainen Aleksi, Karhu Kalle, Kärkkäinen Juha, Navarro Gonzalo, Puglisi Simon J, Sirén Jouni
CeBiB - Center of Biotechnology and Bioengineering, School of Computer Science and Telecommunications, Diego Portales University, Santiago, Chile.
Google Inc, Mountain View, CA USA.
Inf Retr Boston. 2017;20(3):253-291. doi: 10.1007/s10791-017-9297-7. Epub 2017 Apr 1.
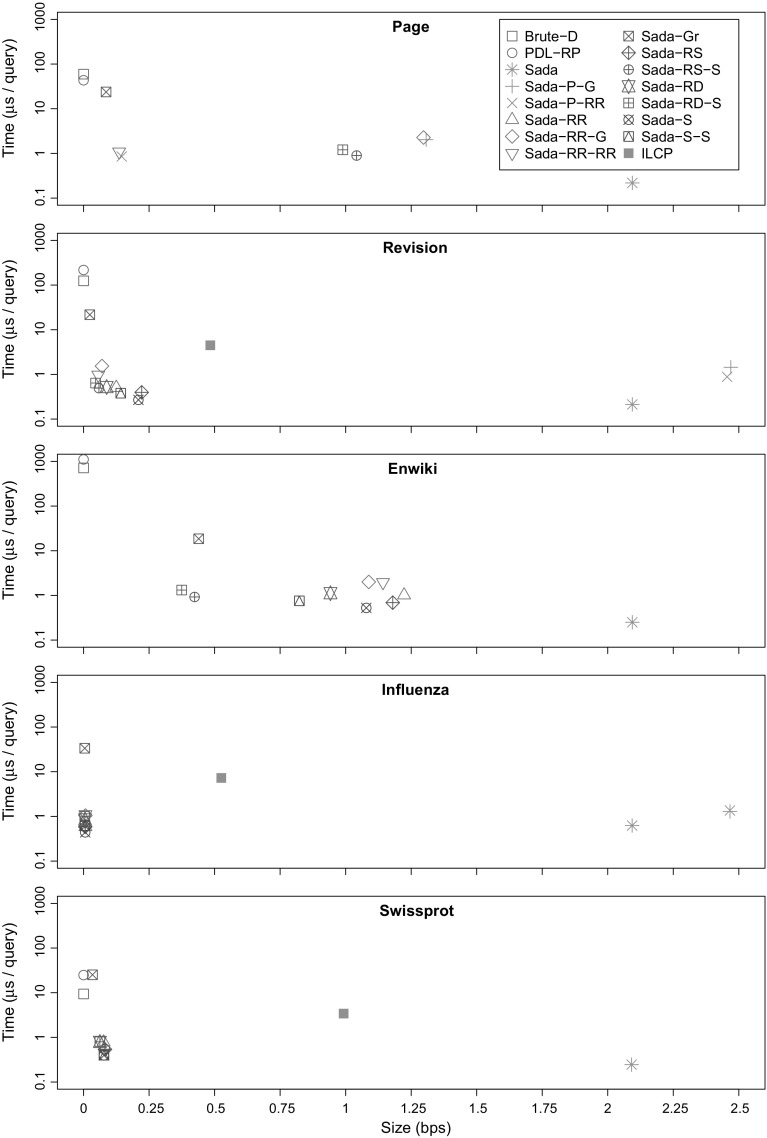
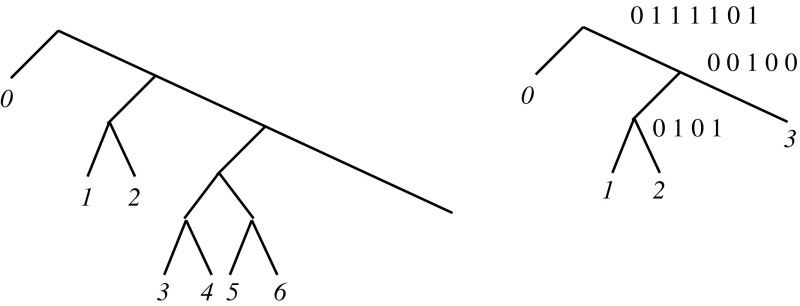
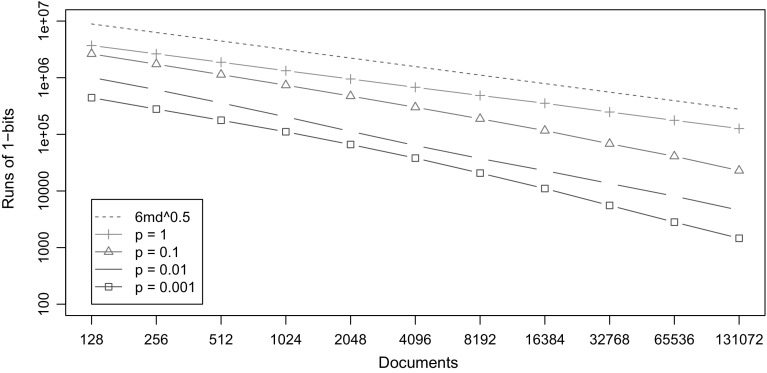
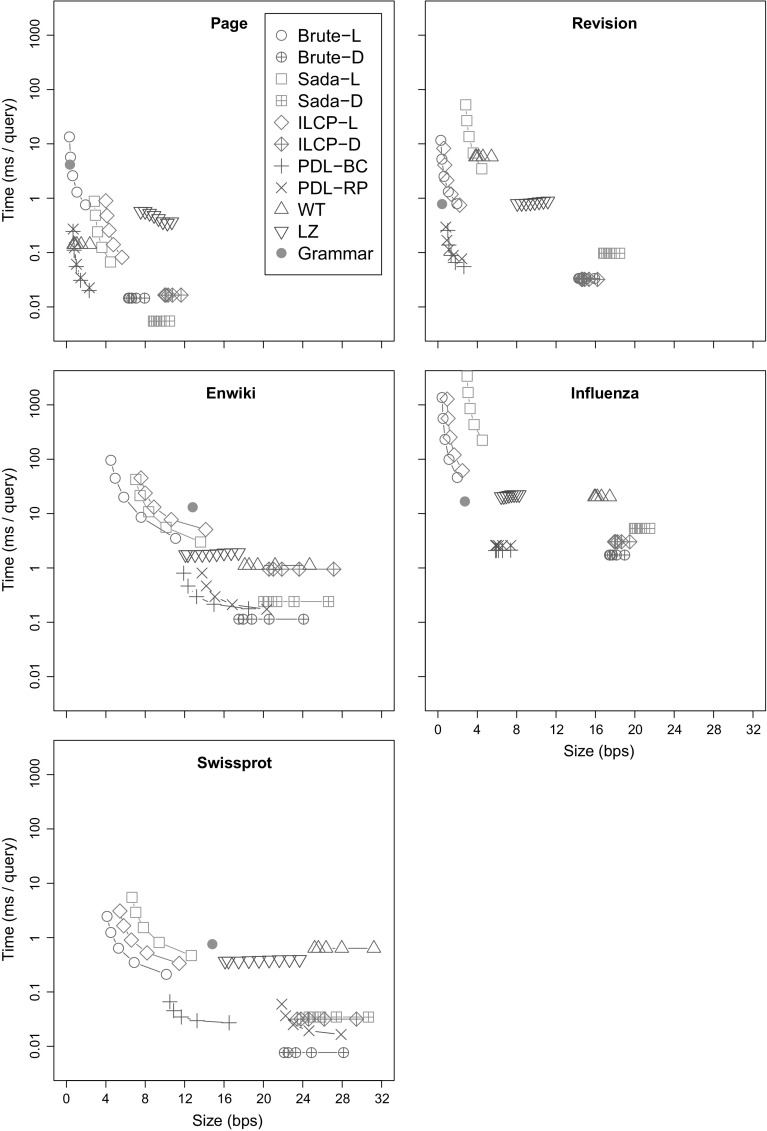
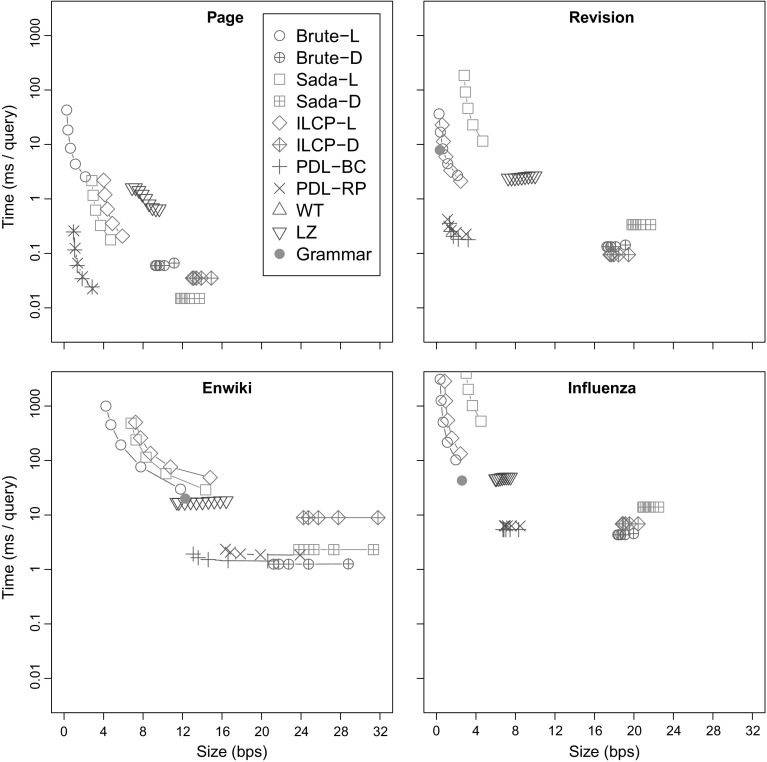
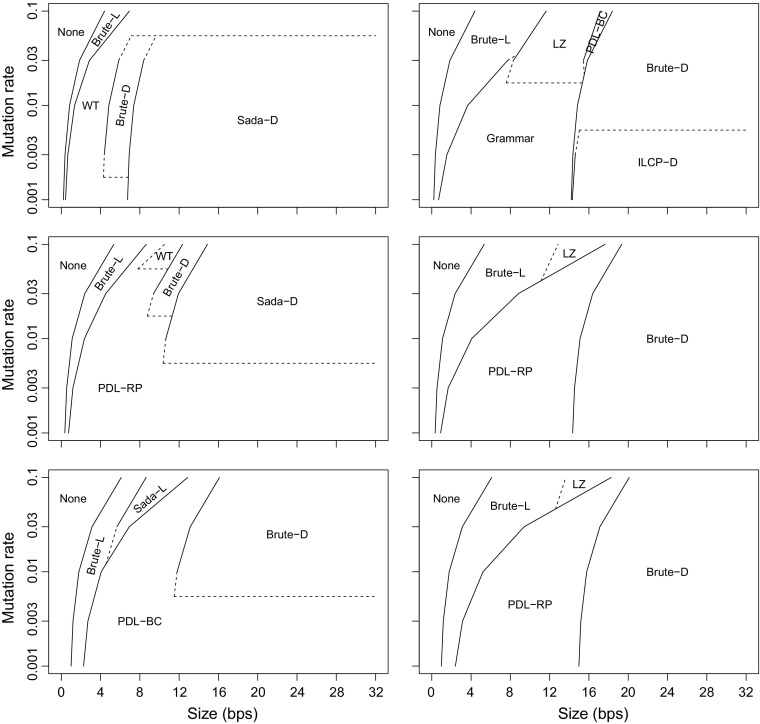
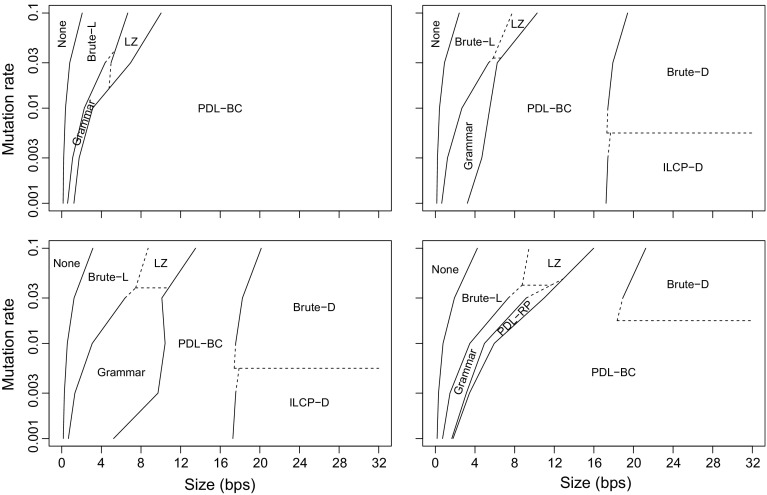
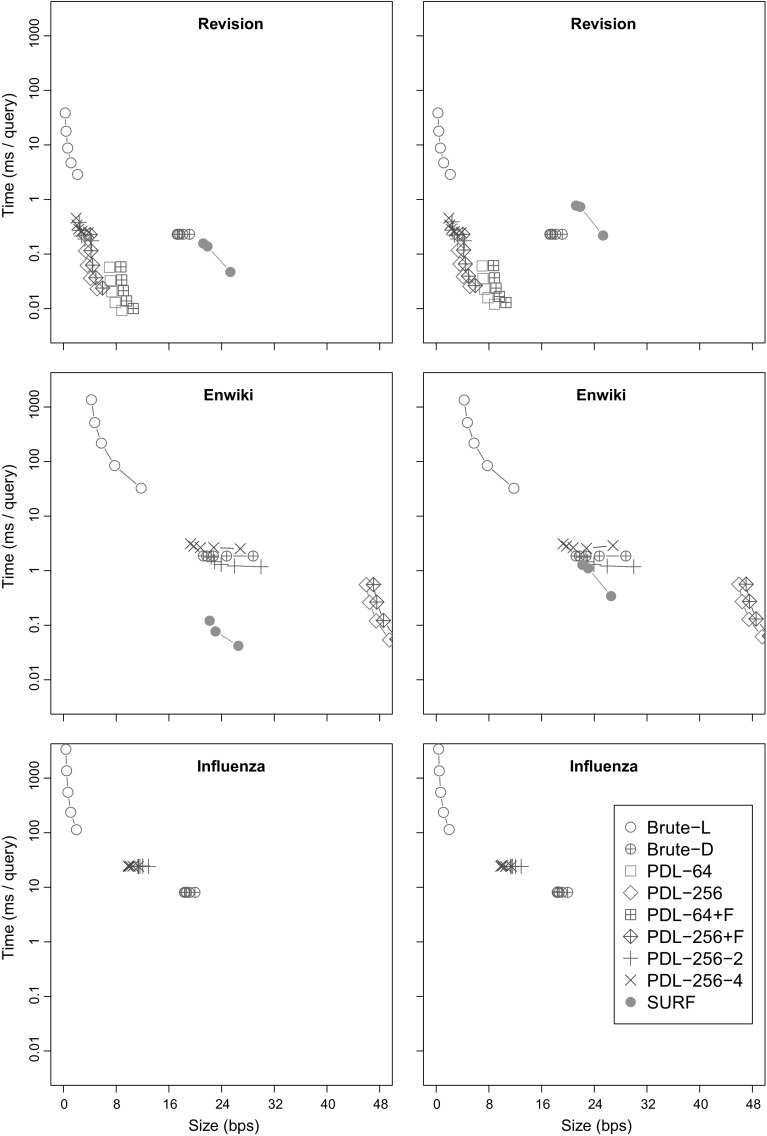
Most of the fastest-growing string collections today are repetitive, that is, most of the constituent documents are similar to many others. As these collections keep growing, a key approach to handling them is to exploit their repetitiveness, which can reduce their space usage by orders of magnitude. We study the problem of indexing repetitive string collections in order to perform efficient document retrieval operations on them. Document retrieval problems are routinely solved by search engines on large natural language collections, but the techniques are less developed on generic string collections. The case of repetitive string collections is even less understood, and there are very few existing solutions. We develop two novel ideas, and , that yield highly compressed indexes solving the problem of document listing (find all the documents where a string appears), top- document retrieval (find the documents where a string appears most often), and document counting (count the number of documents where a string appears). We also show that a classical data structure supporting the latter query becomes highly compressible on repetitive data. Finally, we show how the tools we developed can be combined to solve ranked conjunctive and disjunctive multi-term queries under the simple [Formula: see text] model of relevance. We thoroughly evaluate the resulting techniques in various real-life repetitiveness scenarios, and recommend the best choices for each case.