Wang Wei, Sun Lin, Zhang Shiguang, Zhang Hongjun, Shi Jinling, Xu Tianhe, Li Keliang
College of Computer and Information Engineering, Henan Normal University, Xinxiang, Henan Province, 453007, China.
Laboratory of Computation Intelligence and Information Processing, Engineering Technology Research Center for Computing Intelligence and Data Mining, Xinxiang, Henan Province, 453007, China.
BMC Bioinformatics. 2017 Jun 12;18(1):300. doi: 10.1186/s12859-017-1715-8.
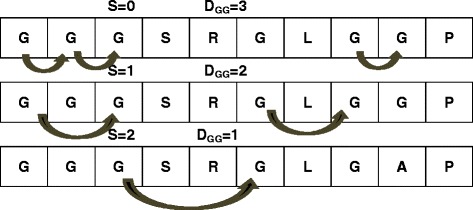
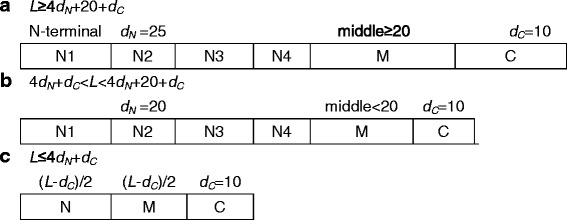
DNA-binding proteins perform important functions in a great number of biological activities. DNA-binding proteins can interact with ssDNA (single-stranded DNA) or dsDNA (double-stranded DNA), and DNA-binding proteins can be categorized as single-stranded DNA-binding proteins (SSBs) and double-stranded DNA-binding proteins (DSBs). The identification of DNA-binding proteins from amino acid sequences can help to annotate protein functions and understand the binding specificity. In this study, we systematically consider a variety of schemes to represent protein sequences: OAAC (overall amino acid composition) features, dipeptide compositions, PSSM (position-specific scoring matrix profiles) and split amino acid composition (SAA), and then we adopt SVM (support vector machine) and RF (random forest) classification model to distinguish SSBs from DSBs.
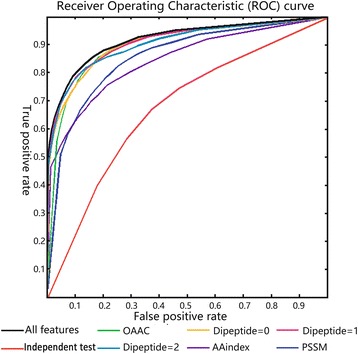
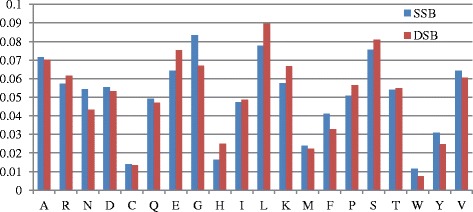
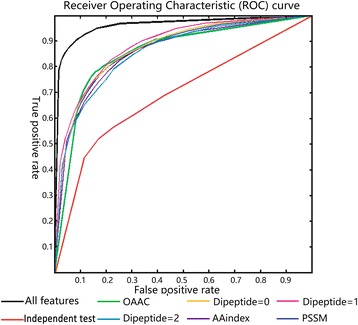
Our results suggest that some sequence features can significantly differentiate DSBs and SSBs. Evaluated by 10 fold cross-validation on the benchmark datasets, our prediction method can achieve the accuracy of 88.7% and AUC (area under the curve) of 0.919. Moreover, our method has good performance in independent testing.
Using various sequence-derived features, a novel method is proposed to distinguish DSBs and SSBs accurately. The method also explores novel features, which could be helpful to discover the binding specificity of DNA-binding proteins.
DNA结合蛋白在大量生物活动中发挥着重要作用。DNA结合蛋白可与单链DNA(ssDNA)或双链DNA(dsDNA)相互作用,且DNA结合蛋白可分为单链DNA结合蛋白(SSB)和双链DNA结合蛋白(DSB)。从氨基酸序列中识别DNA结合蛋白有助于注释蛋白质功能并理解结合特异性。在本研究中,我们系统地考虑了多种表示蛋白质序列的方案:整体氨基酸组成(OAAC)特征、二肽组成、位置特异性评分矩阵谱(PSSM)和分割氨基酸组成(SAA),然后采用支持向量机(SVM)和随机森林(RF)分类模型来区分SSB和DSB。
我们的结果表明,一些序列特征能够显著区分DSB和SSB。在基准数据集上通过10折交叉验证进行评估,我们的预测方法可达到88.7%的准确率和0.919的曲线下面积(AUC)。此外,我们的方法在独立测试中表现良好。
利用各种源自序列的特征,提出了一种准确区分DSB和SSB的新方法。该方法还探索了新的特征,这可能有助于发现DNA结合蛋白的结合特异性。