Yim Won Cheol, Cushman John C
Department of Biochemistry and Molecular Biology, University of Nevada-Reno, Reno, NV, United States of America.
PeerJ. 2017 Jun 22;5:e3486. doi: 10.7717/peerj.3486. eCollection 2017.
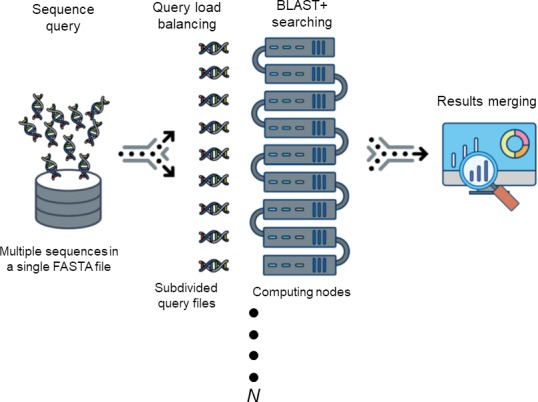
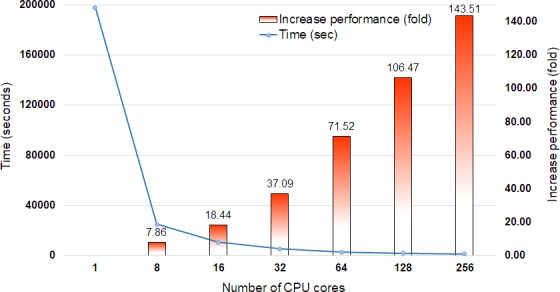
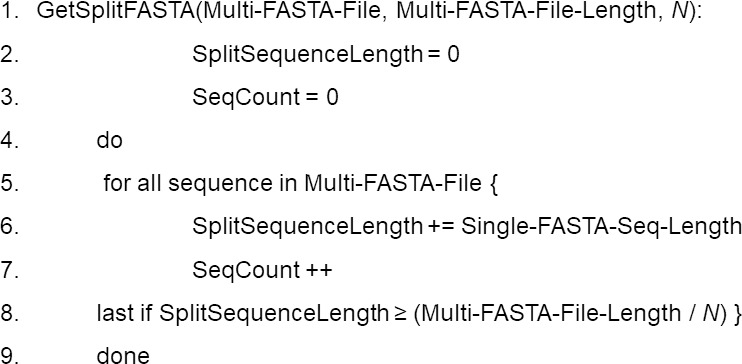
Bioinformatics is currently faced with very large-scale data sets that lead to computational jobs, especially sequence similarity searches, that can take absurdly long times to run. For example, the National Center for Biotechnology Information (NCBI) Basic Local Alignment Search Tool (BLAST and BLAST+) suite, which is by far the most widely used tool for rapid similarity searching among nucleic acid or amino acid sequences, is highly central processing unit (CPU) intensive. While the BLAST suite of programs perform searches very rapidly, they have the potential to be accelerated. In recent years, distributed computing environments have become more widely accessible and used due to the increasing availability of high-performance computing (HPC) systems. Therefore, simple solutions for data parallelization are needed to expedite BLAST and other sequence analysis tools. However, existing software for parallel sequence similarity searches often requires extensive computational experience and skill on the part of the user. In order to accelerate BLAST and other sequence analysis tools, Divide and Conquer BLAST (DCBLAST) was developed to perform NCBI BLAST searches within a cluster, grid, or HPC environment by using a query sequence distribution approach. Scaling from one (1) to 256 CPU cores resulted in significant improvements in processing speed. Thus, DCBLAST dramatically accelerates the execution of BLAST searches using a simple, accessible, robust, and parallel approach. DCBLAST works across multiple nodes automatically and it overcomes the speed limitation of single-node BLAST programs. DCBLAST can be used on any HPC system, can take advantage of hundreds of nodes, and has no output limitations. This freely available tool simplifies distributed computation pipelines to facilitate the rapid discovery of sequence similarities between very large data sets.
生物信息学目前面临着规模非常大的数据集,这些数据集导致计算任务,尤其是序列相似性搜索,可能需要荒谬的长时间才能运行。例如,美国国家生物技术信息中心(NCBI)的基本局部比对搜索工具(BLAST和BLAST+)套件,是目前在核酸或氨基酸序列之间进行快速相似性搜索使用最广泛的工具,它对中央处理器(CPU)的要求很高。虽然BLAST套件程序执行搜索非常迅速,但它们仍有加速的潜力。近年来,由于高性能计算(HPC)系统的可用性不断提高,分布式计算环境变得更容易访问和使用。因此,需要简单的数据并行化解决方案来加速BLAST和其他序列分析工具。然而,现有的用于并行序列相似性搜索的软件通常需要用户具备丰富的计算经验和技能。为了加速BLAST和其他序列分析工具,开发了分治BLAST(DCBLAST),通过使用查询序列分布方法在集群、网格或HPC环境中执行NCBI BLAST搜索。从1个CPU核心扩展到256个CPU核心,显著提高了处理速度。因此,DCBLAST使用简单、可访问、健壮且并行的方法极大地加速了BLAST搜索的执行。DCBLAST能自动跨多个节点运行,克服了单节点BLAST程序的速度限制。DCBLAST可用于任何HPC系统,可利用数百个节点,且没有输出限制。这个免费工具简化了分布式计算管道,以促进在非常大的数据集之间快速发现序列相似性。