Lee Hyukki, Kim Soohyung, Kim Jong Wook, Chung Yon Dohn
Department of Computer Science and Engineering, Korea University, 145 Anam-ro, Seongbuk-gu, Seoul, 02841, Republic of Korea.
Department of IT Convegence, Korea University, Seoul, 145 Anam-ro, Seongbuk-gu, 02841, Republic of Korea.
BMC Med Inform Decis Mak. 2017 Jul 11;17(1):104. doi: 10.1186/s12911-017-0499-0.
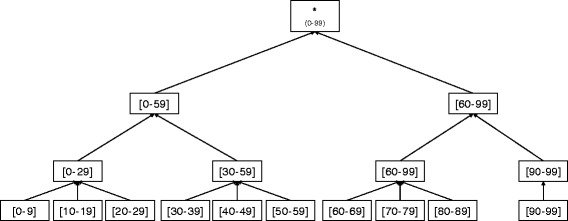
Publishing raw electronic health records (EHRs) may be considered as a breach of the privacy of individuals because they usually contain sensitive information. A common practice for the privacy-preserving data publishing is to anonymize the data before publishing, and thus satisfy privacy models such as k-anonymity. Among various anonymization techniques, generalization is the most commonly used in medical/health data processing. Generalization inevitably causes information loss, and thus, various methods have been proposed to reduce information loss. However, existing generalization-based data anonymization methods cannot avoid excessive information loss and preserve data utility.
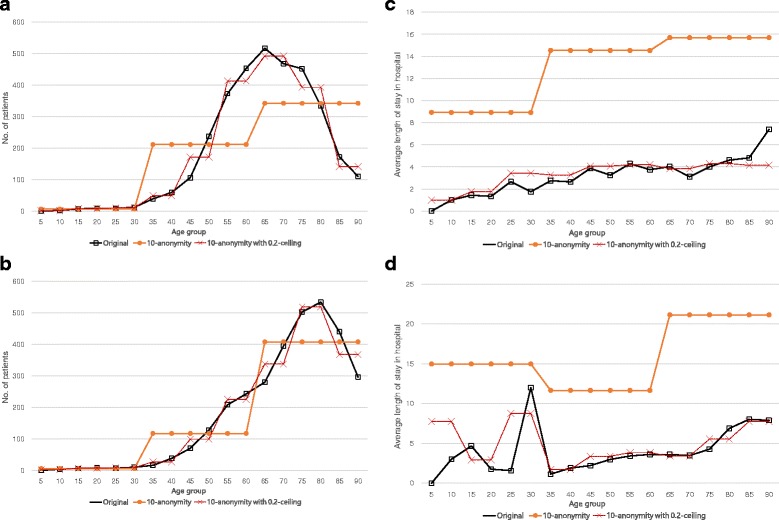
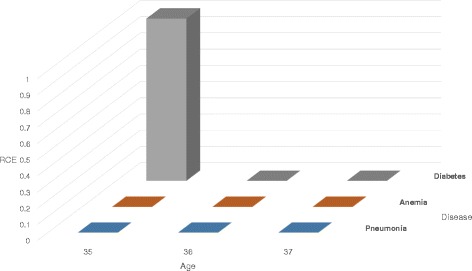
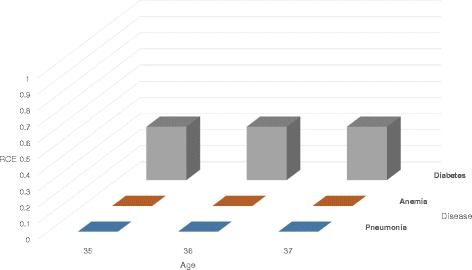
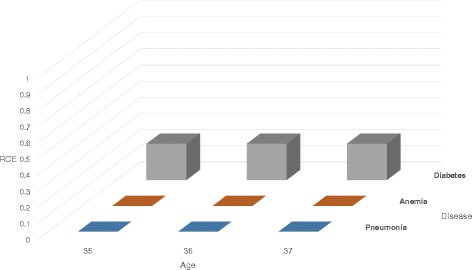
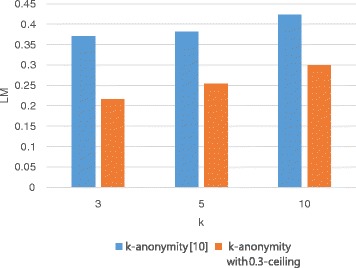
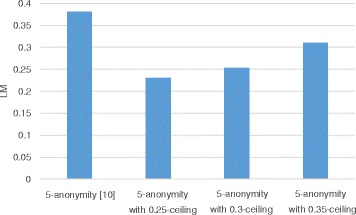
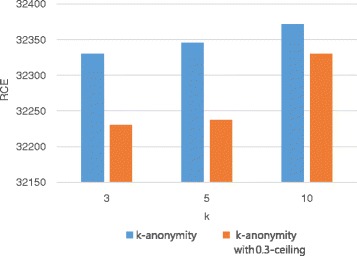
We propose a utility-preserving anonymization for privacy preserving data publishing (PPDP). To preserve data utility, the proposed method comprises three parts: (1) utility-preserving model, (2) counterfeit record insertion, (3) catalog of the counterfeit records. We also propose an anonymization algorithm using the proposed method. Our anonymization algorithm applies full-domain generalization algorithm. We evaluate our method in comparison with existence method on two aspects, information loss measured through various quality metrics and error rate of analysis result.
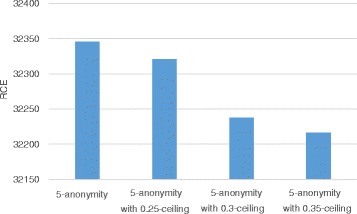
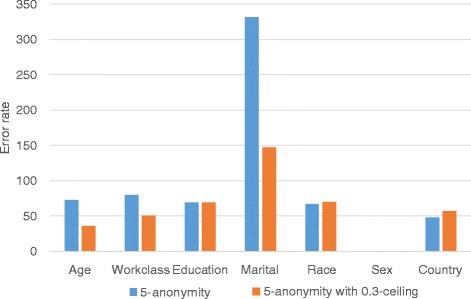
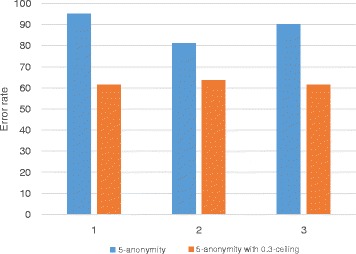
With all different types of quality metrics, our proposed method show the lower information loss than the existing method. In the real-world EHRs analysis, analysis results show small portion of error between the anonymized data through the proposed method and original data.
We propose a new utility-preserving anonymization method and an anonymization algorithm using the proposed method. Through experiments on various datasets, we show that the utility of EHRs anonymized by the proposed method is significantly better than those anonymized by previous approaches.
发布原始电子健康记录(EHRs)可能被视为侵犯个人隐私,因为它们通常包含敏感信息。隐私保护数据发布的一种常见做法是在发布前对数据进行匿名化处理,从而满足诸如k-匿名等隐私模型。在各种匿名化技术中,泛化是医疗/健康数据处理中最常用的方法。泛化不可避免地会导致信息丢失,因此,人们提出了各种方法来减少信息丢失。然而,现有的基于泛化的数据匿名化方法无法避免过多的信息丢失并保留数据效用。
我们提出了一种用于隐私保护数据发布(PPDP)的效用保留匿名化方法。为了保留数据效用,该方法包括三个部分:(1)效用保留模型,(2)伪造记录插入,(3)伪造记录目录。我们还提出了一种使用该方法的匿名化算法。我们的匿名化算法应用全域泛化算法。我们在两个方面将我们的方法与现有方法进行比较评估,一是通过各种质量指标衡量的信息丢失,二是分析结果的错误率。
在所有不同类型的质量指标下,我们提出的方法显示出比现有方法更低的信息丢失。在实际的电子健康记录分析中,分析结果表明,通过我们提出的方法匿名化的数据与原始数据之间的误差很小。
我们提出了一种新的效用保留匿名化方法以及使用该方法的匿名化算法。通过在各种数据集上的实验,我们表明,通过我们提出的方法匿名化的电子健康记录的效用明显优于通过先前方法匿名化的记录。