Surowiec Izabella, Johansson Erik, Torell Frida, Idborg Helena, Gunnarsson Iva, Svenungsson Elisabet, Jakobsson Per-Johan, Trygg Johan
Computational Life Science Cluster (CLiC), Department of Chemistry, Umeå University, 901 81 Umeå, Sweden.
Sartorius Stedim Data Analytics AB, 907 19 Umeå, Sweden.
Metabolomics. 2017;13(10):114. doi: 10.1007/s11306-017-1248-1. Epub 2017 Aug 24.
Availability of large cohorts of samples with related metadata provides scientists with extensive material for studies. At the same time, recent development of modern high-throughput 'omics' technologies, including metabolomics, has resulted in the potential for analysis of large sample sizes. Representative subset selection becomes critical for selection of samples from bigger cohorts and their division into analytical batches. This especially holds true when relative quantification of compound levels is used.
We present a multivariate strategy for representative sample selection and integration of results from multi-batch experiments in metabolomics.
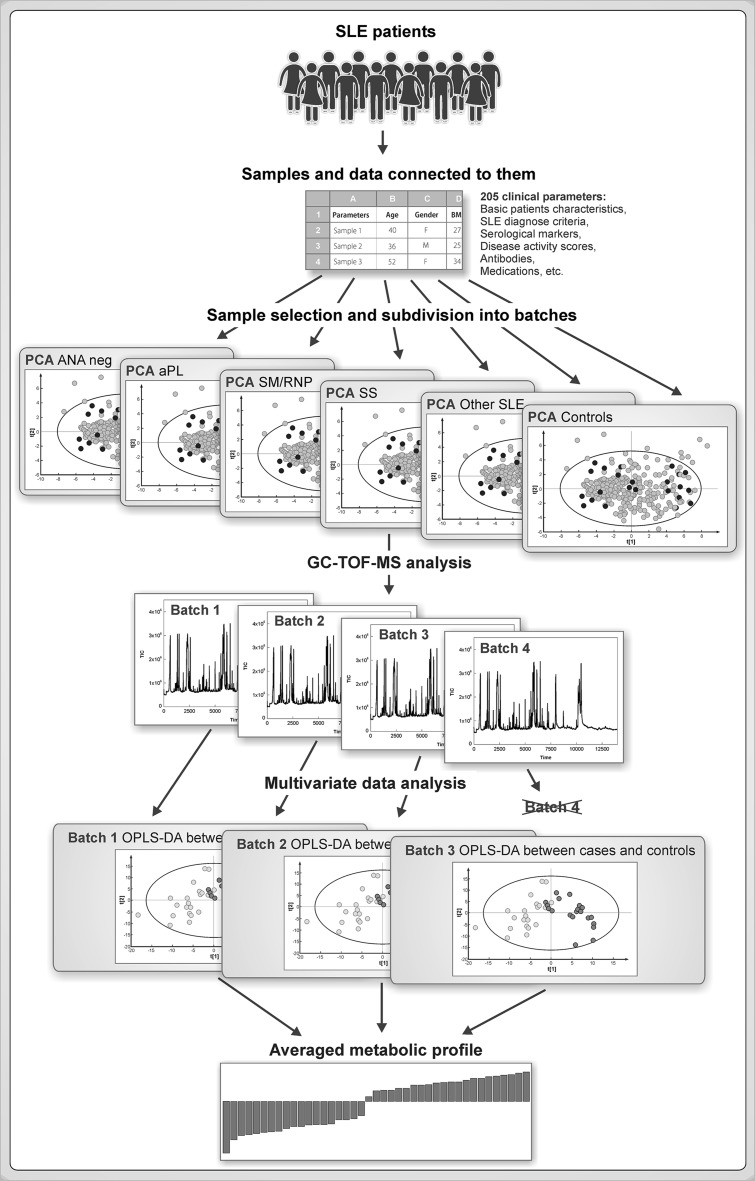
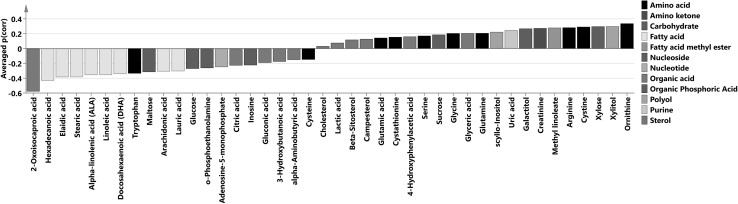
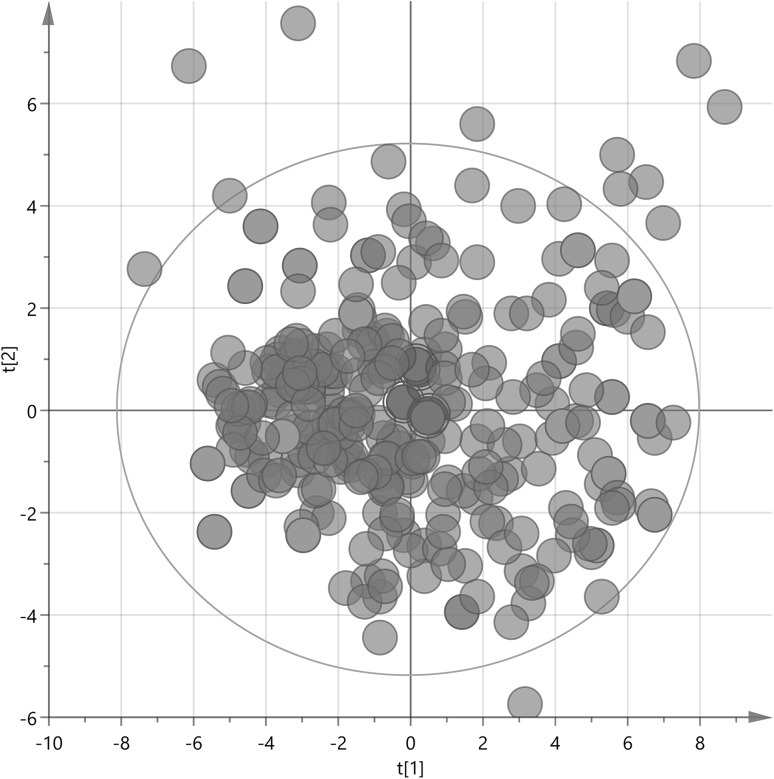
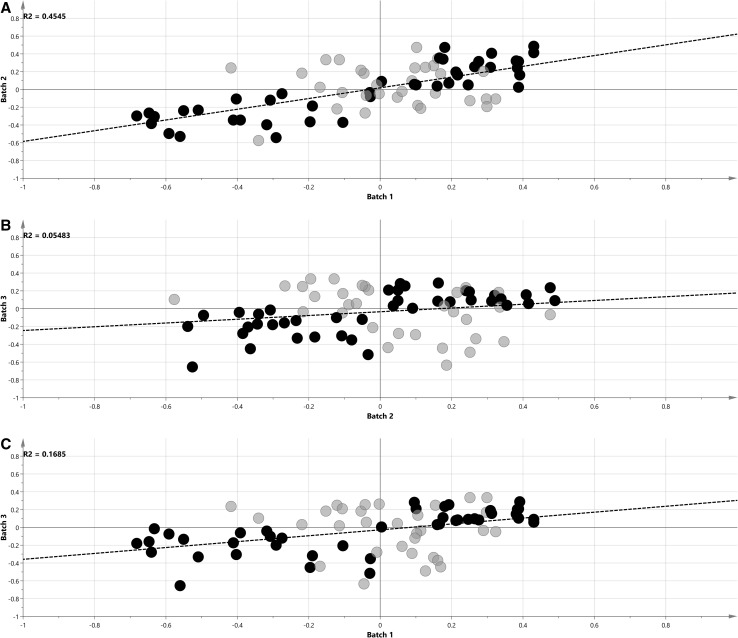
Multivariate characterization was applied for design of experiment based sample selection and subsequent subdivision into four analytical batches which were analyzed on different days by metabolomics profiling using gas-chromatography time-of-flight mass spectrometry (GC-TOF-MS). For each batch OPLS-DA was used and its p(corr) vectors were averaged to obtain combined metabolic profile. Jackknifed standard errors were used to calculate confidence intervals for each metabolite in the average p(corr) profile.
A combined, representative metabolic profile describing differences between systemic lupus erythematosus (SLE) patients and controls was obtained and used for elucidation of metabolic pathways that could be disturbed in SLE.
Design of experiment based representative sample selection ensured diversity and minimized bias that could be introduced at this step. Combined metabolic profile enabled unified analysis and interpretation.
拥有大量带有相关元数据的样本队列,为科学家提供了丰富的研究材料。与此同时,包括代谢组学在内的现代高通量“组学”技术的最新发展,使得分析大量样本成为可能。从更大的队列中选择样本并将其划分为分析批次时,代表性子集选择变得至关重要。当使用化合物水平的相对定量时,情况尤其如此。
我们提出一种多变量策略,用于代谢组学中代表性样本的选择以及多批次实验结果的整合。
将多变量表征应用于基于实验设计的样本选择,并随后细分为四个分析批次,使用气相色谱飞行时间质谱(GC-TOF-MS)通过代谢组学分析在不同日期对其进行分析。对每个批次使用OPLS-DA,并对其p(corr)向量进行平均以获得组合代谢谱。使用留一法标准误差来计算平均p(corr)谱中每种代谢物的置信区间。
获得了一个描述系统性红斑狼疮(SLE)患者与对照组之间差异的组合代表性代谢谱,并用于阐明SLE中可能受到干扰的代谢途径。
基于实验设计的代表性样本选择确保了多样性,并最大限度地减少了在此步骤中可能引入的偏差。组合代谢谱实现了统一的分析和解释。