Ahmad Muhammad, Protasov Stanislav, Khan Adil Mehmood, Hussain Rasheed, Khattak Asad Masood, Khan Wajahat Ali
Machine Learning and Knowledge Representation (MlKr) Lab, Institute of Robotics, Innopolis University, Innopolis, 420500, Kazan, Tatarstan, Russia.
Institute of Information Systems, Innopolis University, Innopolis, 420500, Kazan, Tatarstan, Russia.
PLoS One. 2018 Jan 5;13(1):e0188996. doi: 10.1371/journal.pone.0188996. eCollection 2018.
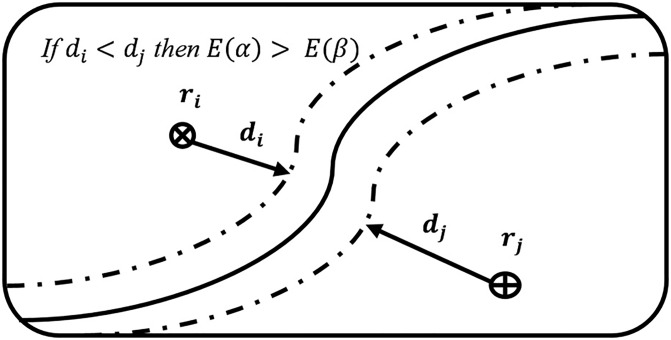
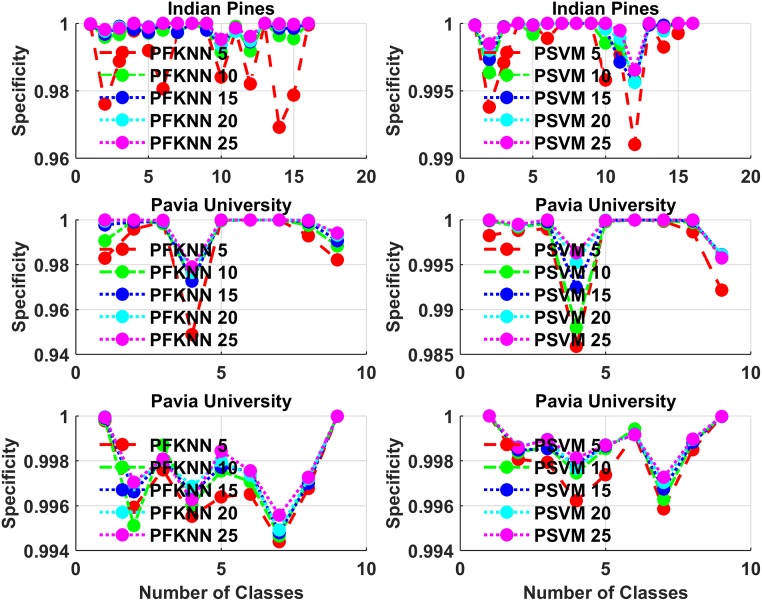
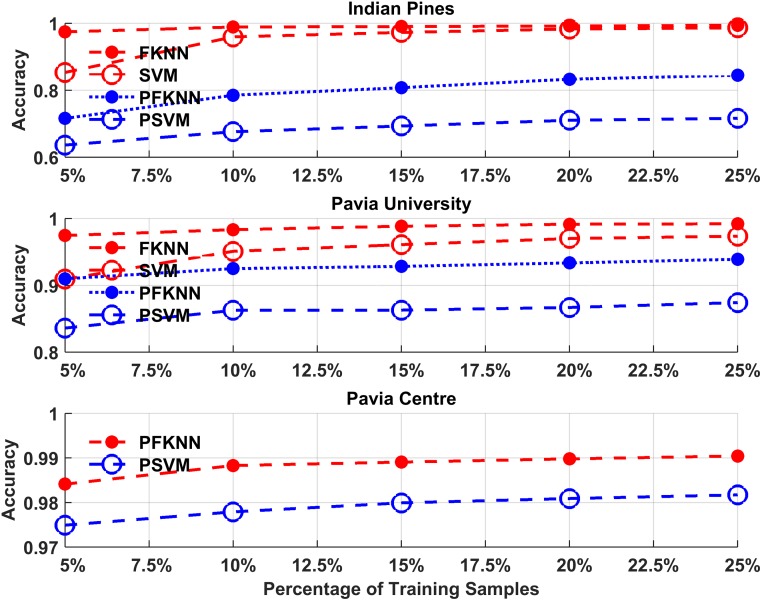
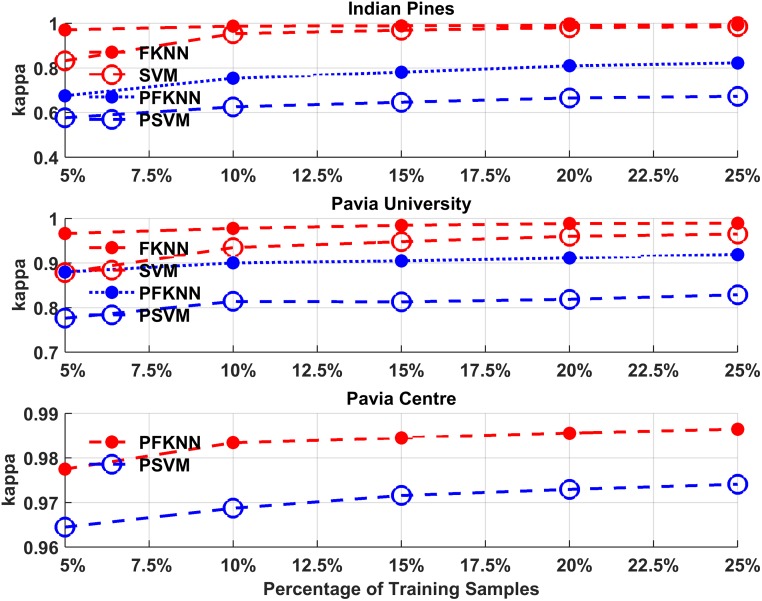
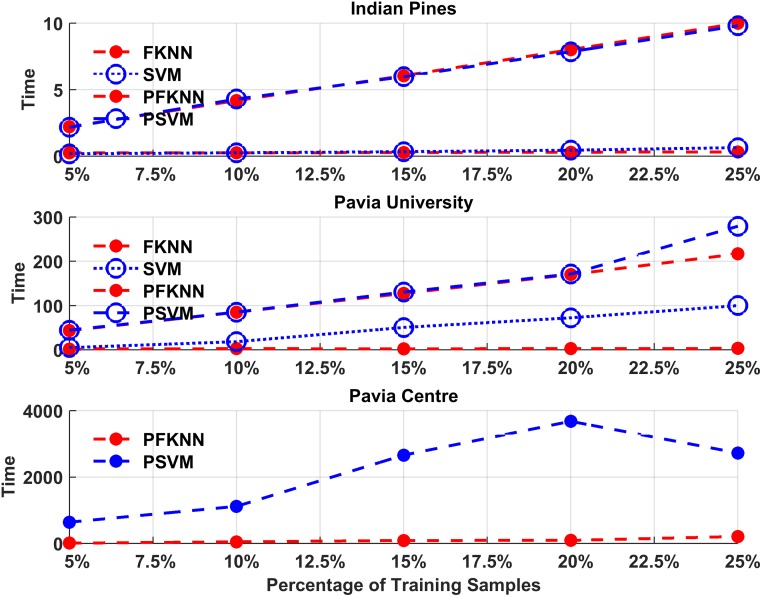
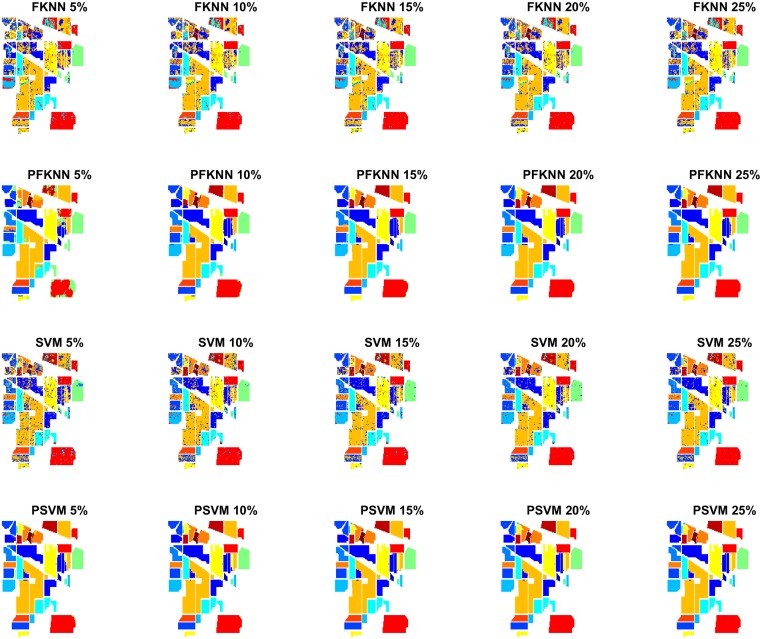
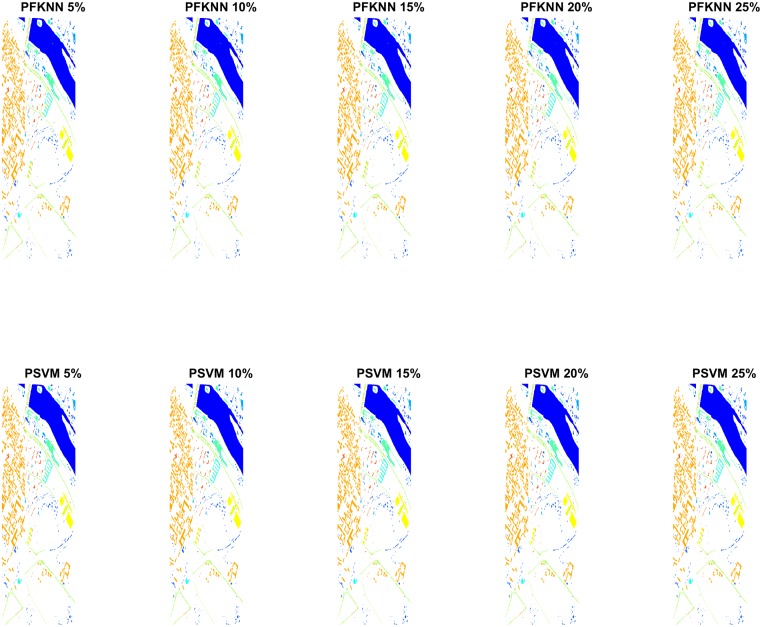
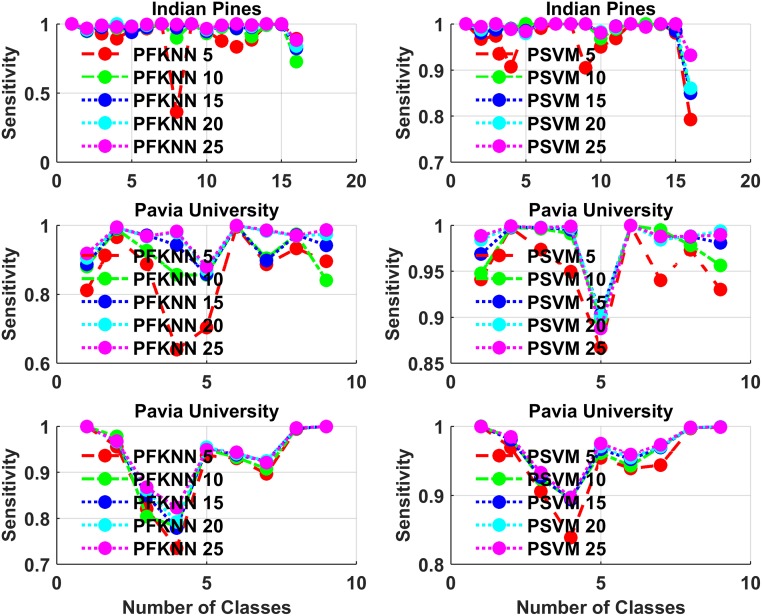
Hyperspectral image classification with a limited number of training samples without loss of accuracy is desirable, as collecting such data is often expensive and time-consuming. However, classifiers trained with limited samples usually end up with a large generalization error. To overcome the said problem, we propose a fuzziness-based active learning framework (FALF), in which we implement the idea of selecting optimal training samples to enhance generalization performance for two different kinds of classifiers, discriminative and generative (e.g. SVM and KNN). The optimal samples are selected by first estimating the boundary of each class and then calculating the fuzziness-based distance between each sample and the estimated class boundaries. Those samples that are at smaller distances from the boundaries and have higher fuzziness are chosen as target candidates for the training set. Through detailed experimentation on three publically available datasets, we showed that when trained with the proposed sample selection framework, both classifiers achieved higher classification accuracy and lower processing time with the small amount of training data as opposed to the case where the training samples were selected randomly. Our experiments demonstrate the effectiveness of our proposed method, which equates favorably with the state-of-the-art methods.
在不损失准确性的情况下,利用有限数量的训练样本进行高光谱图像分类是很有必要的,因为收集此类数据通常既昂贵又耗时。然而,使用有限样本训练的分类器通常会导致较大的泛化误差。为了克服上述问题,我们提出了一种基于模糊性的主动学习框架(FALF),在该框架中,我们实现了选择最优训练样本的想法,以提高两种不同类型分类器(判别式和生成式,如支持向量机和K近邻算法)的泛化性能。通过首先估计每个类别的边界,然后计算每个样本与估计的类边界之间基于模糊性的距离来选择最优样本。那些与边界距离较小且模糊性较高的样本被选作训练集的目标候选样本。通过在三个公开可用数据集上进行的详细实验,我们表明,与随机选择训练样本的情况相比,当使用所提出的样本选择框架进行训练时,两种分类器在少量训练数据的情况下都实现了更高的分类准确率和更短的处理时间。我们的实验证明了我们提出的方法的有效性,该方法与当前的先进方法相比具有优势。