Synthetic Genomics Research Group, Biomass Engineering Research Division, RIKEN Center for Sustainable Resource Science (CSRS), 1-7-22 Suehiro-cho, Tsurumi-ku, Yokohama, Kanagawa, 230-0045, Japan.
Centre for Chemical Biology, Universiti Sains Malaysia, 11900 Bayan Lepas, Penang, Malaysia.
BMC Genomics. 2018 Jan 19;19(Suppl 1):922. doi: 10.1186/s12864-017-4333-y.
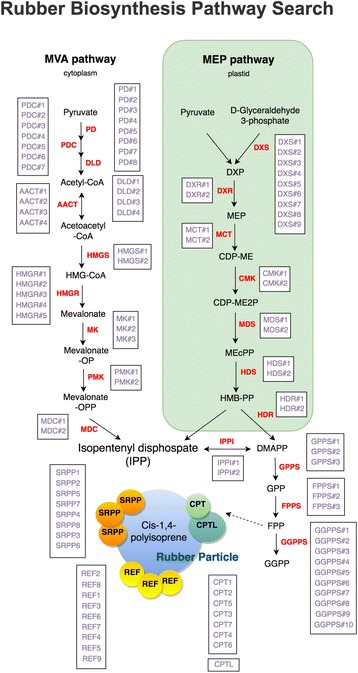
Natural rubber is an economically important material. Currently the Pará rubber tree, Hevea brasiliensis is the main commercial source. Little is known about rubber biosynthesis at the molecular level. Next-generation sequencing (NGS) technologies brought draft genomes of three rubber cultivars and a variety of RNA sequencing (RNA-seq) data. However, no current genome or transcriptome databases (DB) are organized by gene.
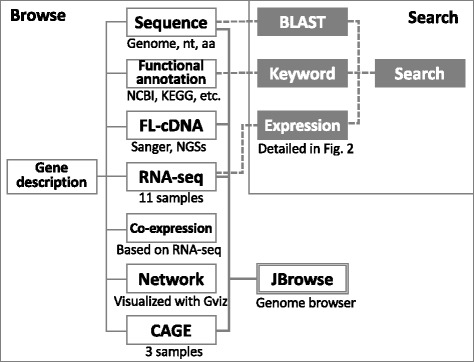
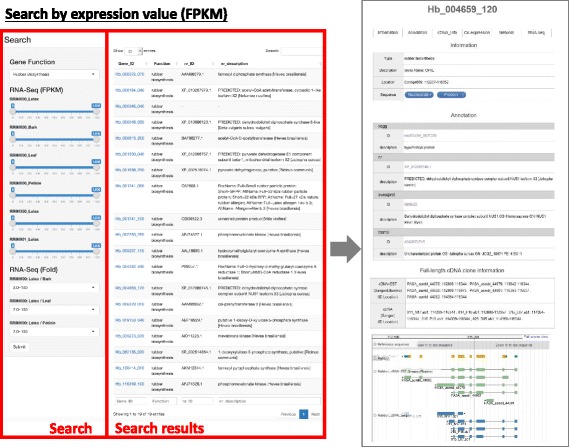
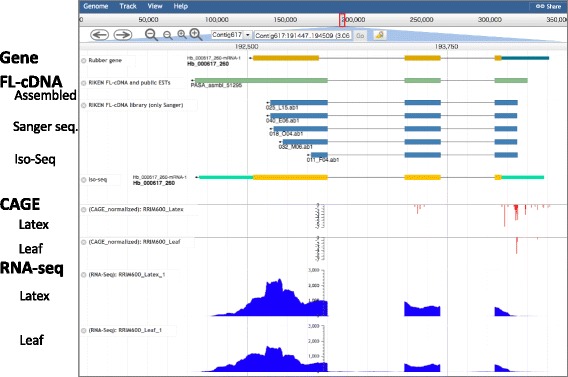
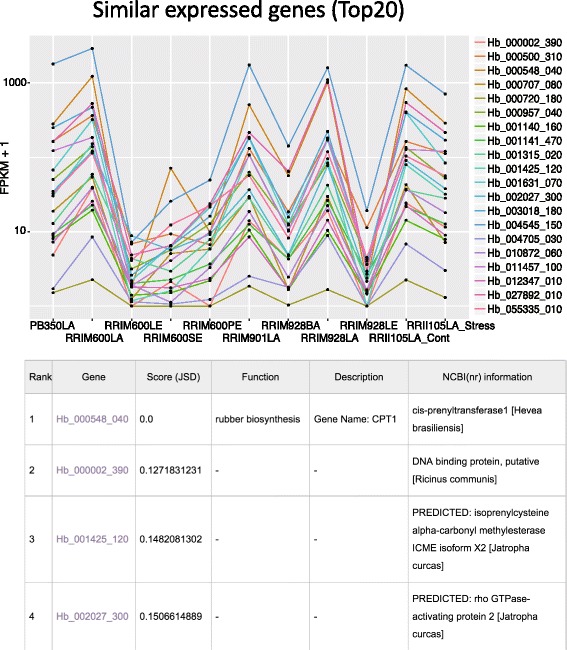
A gene-oriented database is a valuable support for rubber research. Based on our original draft genome sequence of H. brasiliensis RRIM600, we constructed a rubber tree genome and transcriptome DB. Our DB provides genome information including gene functional annotations and multi-transcriptome data of RNA-seq, full-length cDNAs including PacBio Isoform sequencing (Iso-Seq), ESTs and genome wide transcription start sites (TSSs) derived from CAGE technology. Using our original and publically available RNA-seq data, we calculated co-expressed genes for identifying functionally related gene sets and/or genes regulated by the same transcription factor (TF). Users can access multi-transcriptome data through both a gene-oriented web page and a genome browser. For the gene searching system, we provide keyword search, sequence homology search and gene expression search; users can also select their expression threshold easily.
The rubber genome and transcriptome DB provides rubber tree genome sequence and multi-transcriptomics data. This DB is useful for comprehensive understanding of the rubber transcriptome. This will assist both industrial and academic researchers for rubber and economically important close relatives such as R. communis, M. esculenta and J. curcas. The Rubber Transcriptome DB release 2017.03 is accessible at http://matsui-lab.riken.jp/rubber/ .
天然橡胶是一种具有重要经济价值的材料。目前,巴西橡胶树(Hevea brasiliensis)是主要的商业来源。关于橡胶生物合成的分子水平知之甚少。下一代测序(NGS)技术带来了三个橡胶品种和多种 RNA 测序(RNA-seq)数据的草图基因组。然而,目前没有按基因组织的基因组或转录组数据库(DB)。
面向基因的数据库是橡胶研究的有价值的支持。基于我们原始的巴西橡胶树 RRIM600 草图基因组序列,我们构建了橡胶树基因组和转录组数据库。我们的数据库提供了基因组信息,包括基因功能注释和 RNA-seq 的多转录组数据、全长 cDNA,包括 PacBio Isoform sequencing(Iso-Seq)、EST 和 CAGE 技术衍生的全基因组转录起始位点(TSS)。使用我们原始和公开的 RNA-seq 数据,我们计算了共表达基因,以识别功能相关的基因集和/或受同一转录因子(TF)调节的基因。用户可以通过面向基因的网页和基因组浏览器访问多转录组数据。对于基因搜索系统,我们提供了关键字搜索、序列同源性搜索和基因表达搜索;用户还可以轻松选择他们的表达阈值。
橡胶基因组和转录组数据库提供了橡胶树基因组序列和多转录组学数据。该数据库有助于全面了解橡胶转录组。这将有助于工业界和学术界研究人员研究橡胶以及经济上重要的近亲,如橡胶树、印度麻和麻疯树。橡胶转录组数据库 2017.03 版可在 http://matsui-lab.riken.jp/rubber/ 访问。