National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, Maryland 20894, USA.
Sci Data. 2018 Jun 12;5:180104. doi: 10.1038/sdata.2018.104.
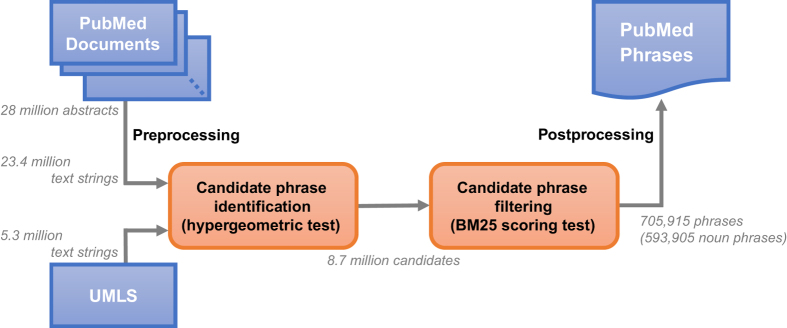
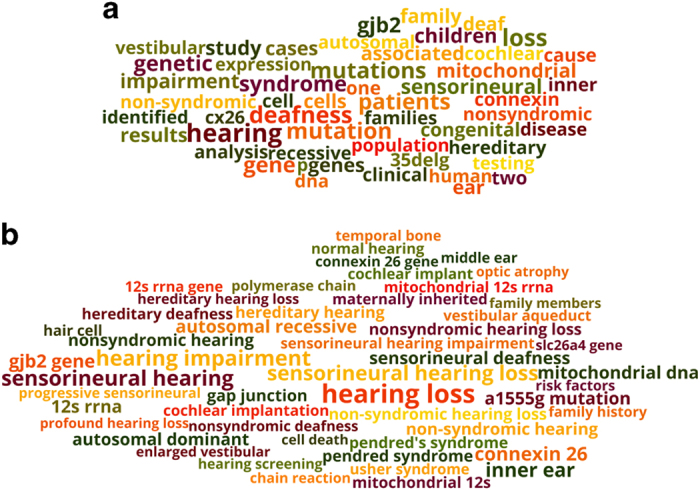
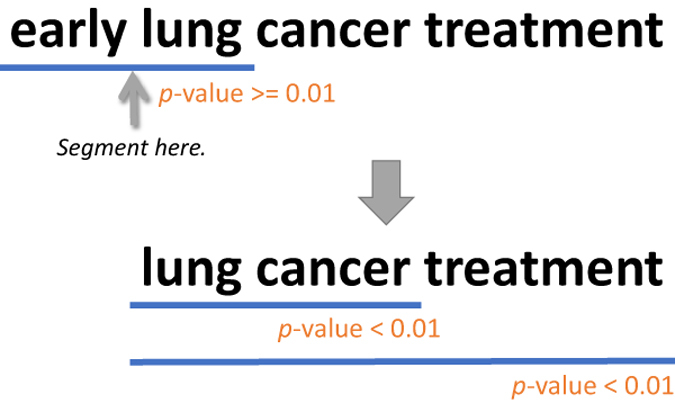
In biomedicine, key concepts are often expressed by multiple words (e.g., 'zinc finger protein'). Previous work has shown treating a sequence of words as a meaningful unit, where applicable, is not only important for human understanding but also beneficial for automatic information seeking. Here we present a collection of PubMed Phrases that are beneficial for information retrieval and human comprehension. We define these phrases as coherent chunks that are logically connected. To collect the phrase set, we apply the hypergeometric test to detect segments of consecutive terms that are likely to appear together in PubMed. These text segments are then filtered using the BM25 ranking function to ensure that they are beneficial from an information retrieval perspective. Thus, we obtain a set of 705,915 PubMed Phrases. We evaluate the quality of the set by investigating PubMed user click data and manually annotating a sample of 500 randomly selected noun phrases. We also analyze and discuss the usage of these PubMed Phrases in literature search.
在生物医学领域,关键概念通常由多个词来表达(例如,“锌指蛋白”)。之前的研究表明,将词序列视为有意义的单元(在适用的情况下)不仅对人类理解很重要,而且对自动信息检索也有好处。在这里,我们提供了一套有助于信息检索和人类理解的 PubMed Phrases。我们将这些短语定义为逻辑上相互关联的连贯片段。为了收集短语集,我们应用超几何检验来检测连续术语段,这些术语段很可能在 PubMed 中一起出现。然后,使用 BM25 排名函数对这些文本片段进行过滤,以确保从信息检索的角度来看它们是有益的。因此,我们获得了一套 705915 个 PubMed Phrases。我们通过调查 PubMed 用户点击数据并手动注释 500 个随机选择的名词短语样本来评估该短语集的质量。我们还分析和讨论了这些在文献检索中使用 PubMed Phrases 的情况。