School of Computer Science and Technology, Xidian University, Xi'an, 710071, China.
BMC Bioinformatics. 2018 Jun 18;19(1):228. doi: 10.1186/s12859-018-2242-y.
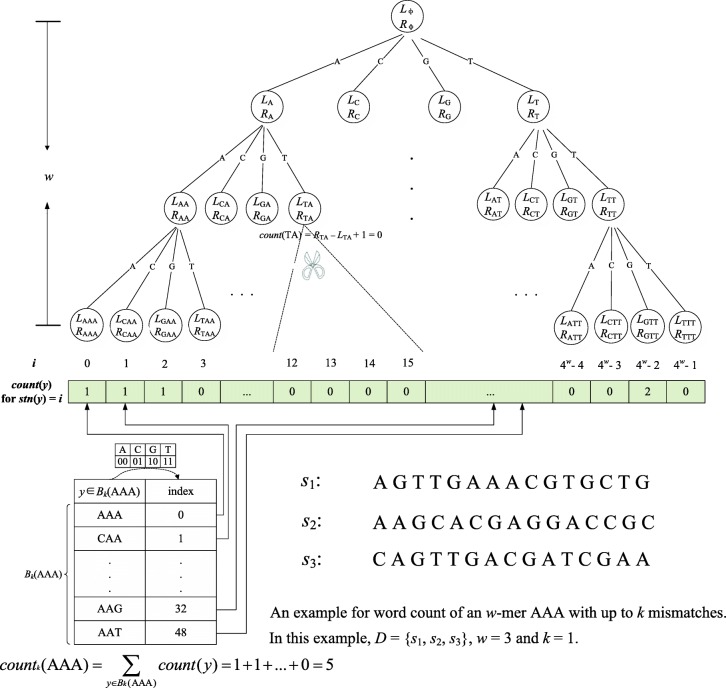
Given a set of t n-length DNA sequences, q satisfying 0 < q ≤ 1, and l and d satisfying 0 ≤ d < l < n, the quorum planted motif search (qPMS) finds l-length strings that occur in at least qt input sequences with up to d mismatches and is mainly used to locate transcription factor binding sites in DNA sequences. Existing qPMS algorithms have been able to efficiently process small standard datasets (e.g., t = 20 and n = 600), but they are too time consuming to process large DNA datasets, such as ChIP-seq datasets that contain thousands of sequences or more.
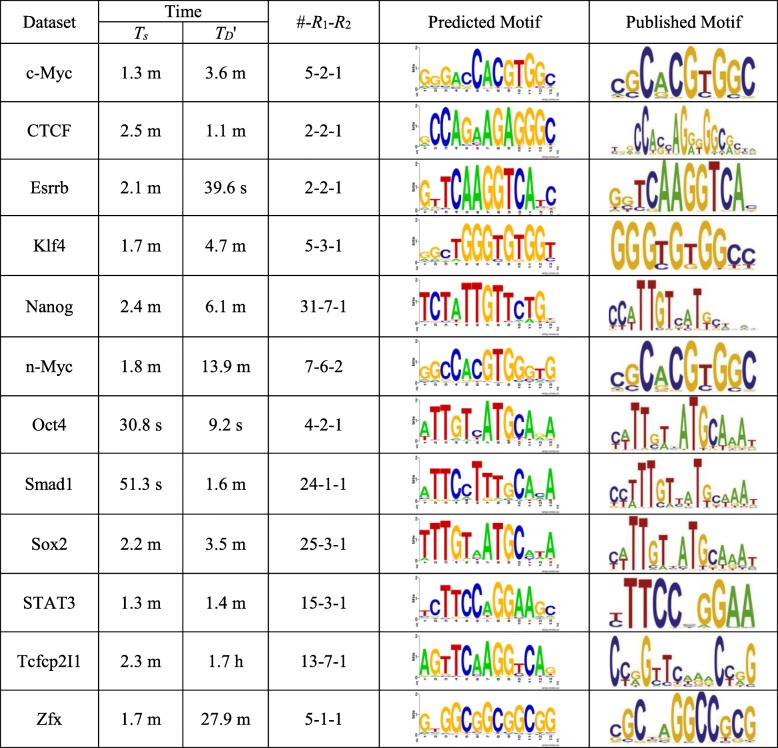
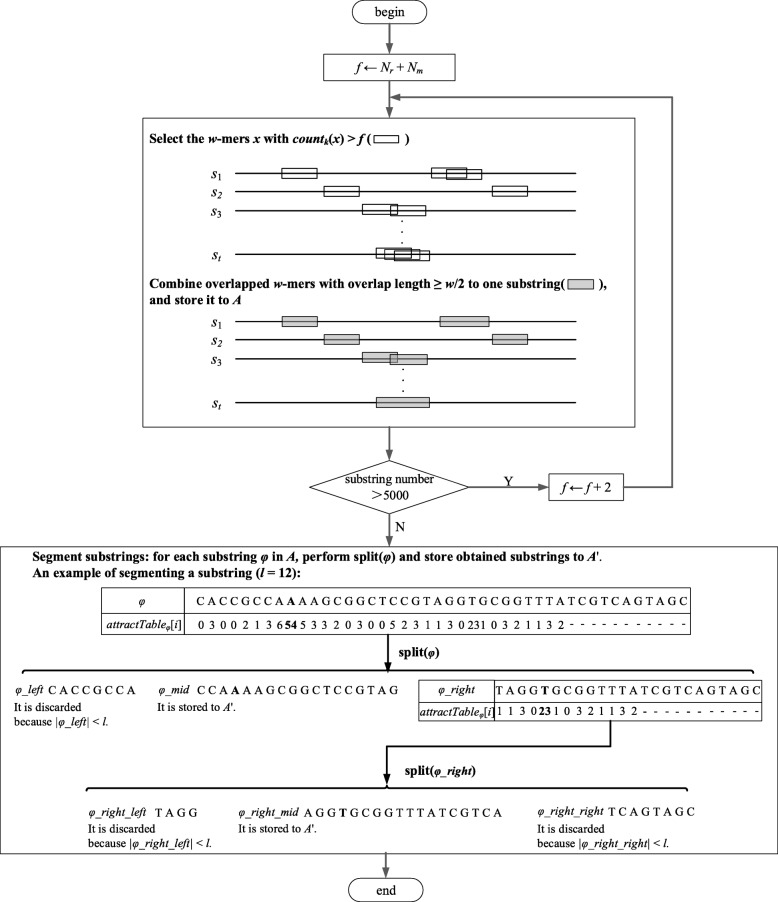
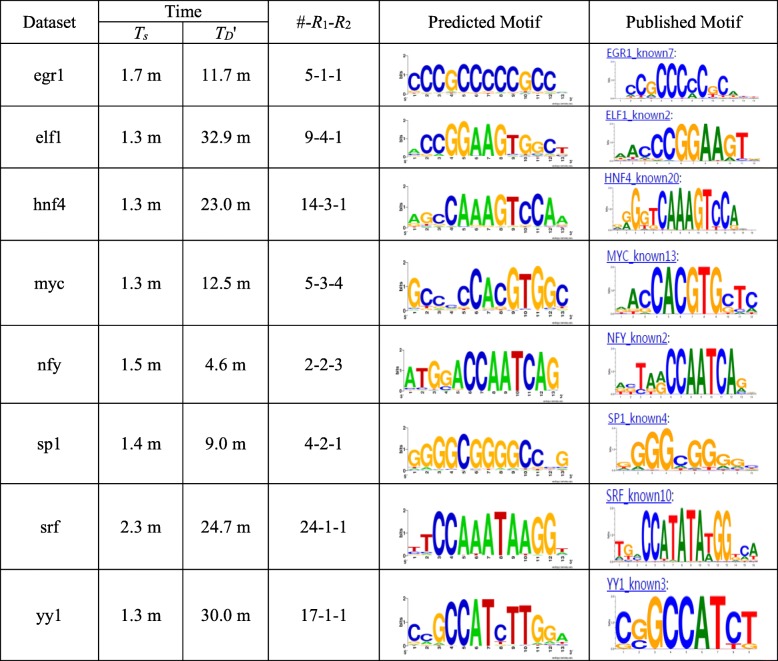
We analyze the effects of t and q on the time performance of qPMS algorithms and find that a large t or a small q causes a longer computation time. Based on this information, we improve the time performance of existing qPMS algorithms by selecting a sample sequence set D' with a small t and a large q from the large input dataset D and then executing qPMS algorithms on D'. A sample sequence selection algorithm named SamSelect is proposed. The experimental results on both simulated and real data show (1) that SamSelect can select D' efficiently and (2) that the qPMS algorithms executed on D' can find implanted or real motifs in a significantly shorter time than when executed on D.
We improve the ability of existing qPMS algorithms to process large DNA datasets from the perspective of selecting high-quality sample sequence sets so that the qPMS algorithms can find motifs in a short time in the selected sample sequence set D', rather than take an unfeasibly long time to search the original sequence set D. Our motif discovery method is an approximate algorithm.
给定一组 t 个 n 长度的 DNA 序列、满足 0<q≤1 的 q 和满足 0≤d<l<n 的 l 和 d,众数种植 motif 搜索(qPMS)查找至少在 qt 个输入序列中出现的 l 长度字符串,这些序列最多有 d 个错配,主要用于在 DNA 序列中定位转录因子结合位点。现有的 qPMS 算法已经能够有效地处理小的标准数据集(例如,t=20 和 n=600),但处理大型 DNA 数据集(如包含数千个或更多序列的 ChIP-seq 数据集)的时间开销太大。
我们分析了 t 和 q 对 qPMS 算法时间性能的影响,发现大的 t 或小的 q 会导致更长的计算时间。基于此信息,我们通过从小的输入数据集 D 中选择一个具有小 t 和大 q 的样本序列集 D',然后在 D'上执行 qPMS 算法,从而改进了现有 qPMS 算法的时间性能。提出了一种名为 SamSelect 的样本序列选择算法。在模拟和真实数据上的实验结果表明:(1)SamSelect 可以有效地选择 D';(2)在 D'上执行的 qPMS 算法可以比在 D 上执行的算法更快地找到植入或真实的 motif。
我们从选择高质量样本序列集的角度改进了现有 qPMS 算法处理大型 DNA 数据集的能力,以便 qPMS 算法能够在所选样本序列集 D'中快速找到 motif,而不是在原始序列集 D 中花费不切实际的长时间搜索。我们的 motif 发现方法是一种近似算法。