Demidenko Eugene
Department of Biomedical Data Science and Department of Mathematics Dartmouth College Hanover New Hampshire.
Stat Anal Data Min. 2018 Aug;11(4):153-166. doi: 10.1002/sam.11379. Epub 2018 May 11.
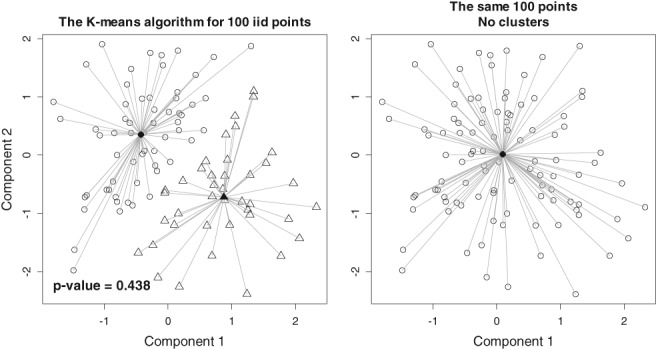
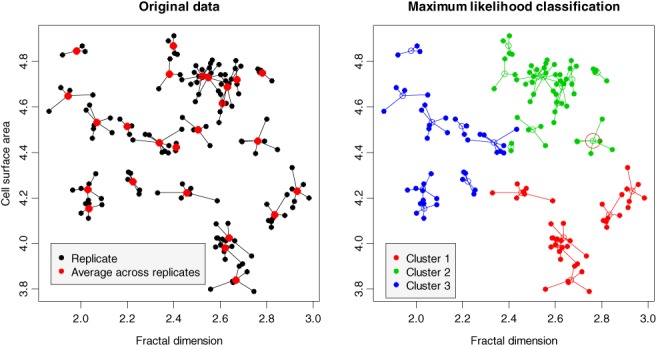
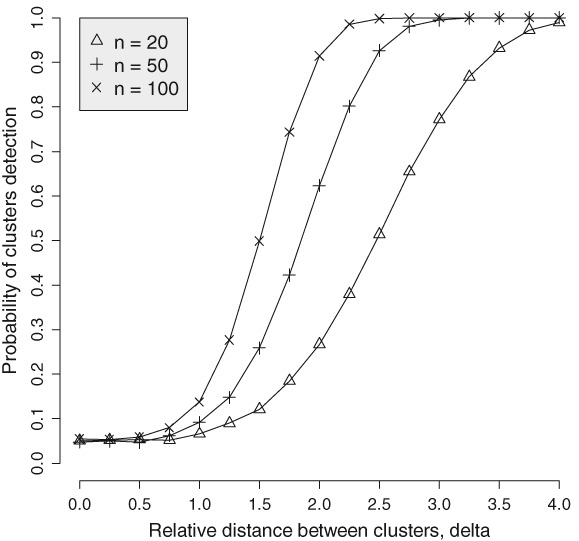
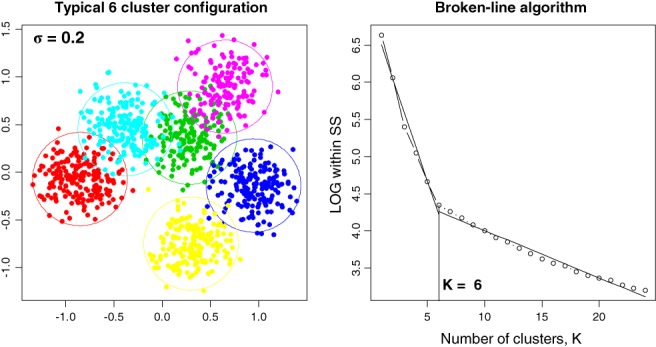
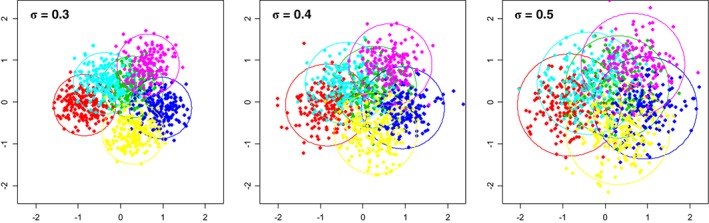
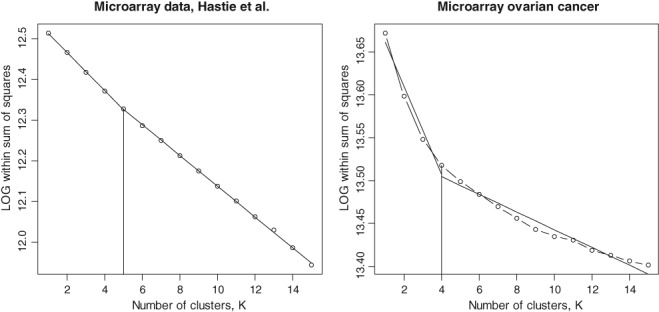
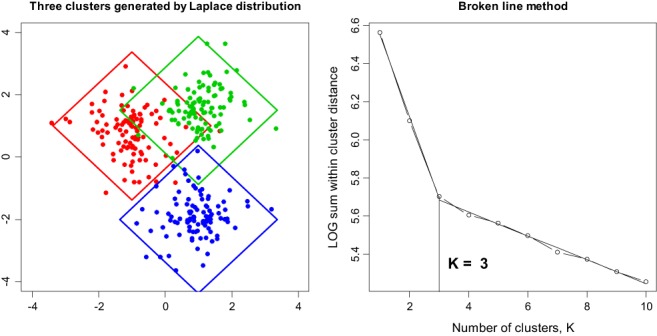
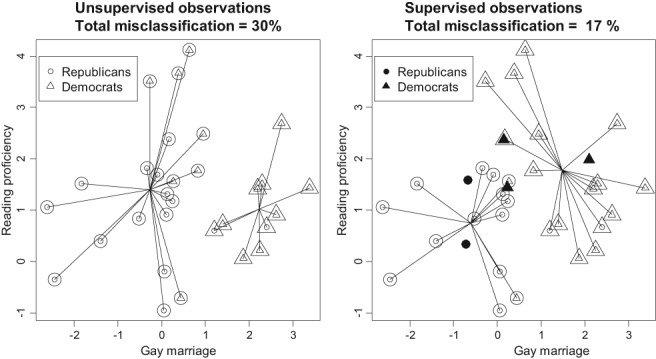
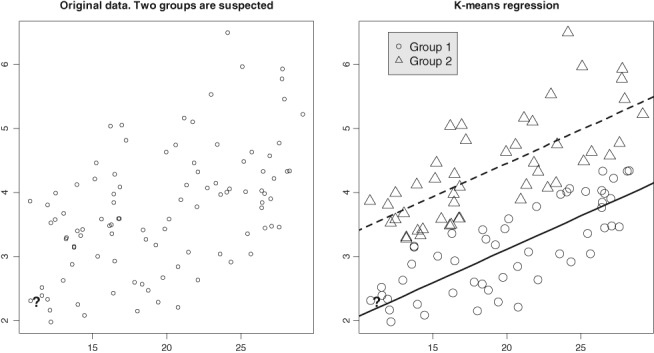
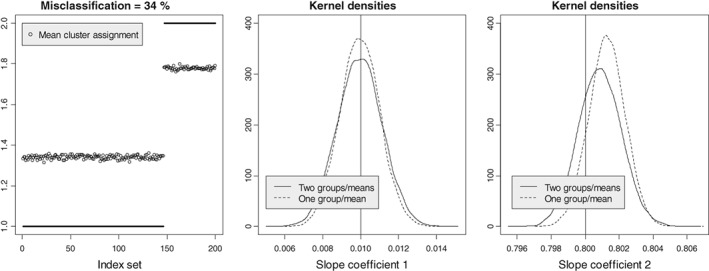
Typically, when referring to a model-based classification, the mixture distribution approach is understood. In contrast, we revive the hard-classification model-based approach developed by Banfield and Raftery (1993) for which K-means is equivalent to the maximum likelihood (ML) estimation. The next-generation K-means algorithm does not end after the classification is achieved, but moves forward to answer the following fundamental questions: Are there clusters, how many clusters are there, what are the statistical properties of the estimated means and index sets, what is the distribution of the coefficients in the clusterwise regression, and how to classify multilevel data? The statistical model-based approach for the K-means algorithm is the key, because it allows statistical simulations and studying the properties of classification following the track of the classical statistics. This paper illustrates the application of the ML classification to testing the no-clusters hypothesis, to studying various methods for selection of the number of clusters using simulations, robust clustering using Laplace distribution, studying properties of the coefficients in clusterwise regression, and finally to multilevel data by marrying the variance components model with K-means.
通常,当提及基于模型的分类时,人们理解的是混合分布方法。相比之下,我们复兴了由班菲尔德和拉夫蒂(1993年)开发的基于硬分类模型的方法,对于该方法,K均值等同于最大似然(ML)估计。下一代K均值算法在完成分类后并不会结束,而是继续前进以回答以下基本问题:是否存在聚类,有多少个聚类,估计均值和索引集的统计属性是什么,聚类回归中系数的分布是什么,以及如何对多级数据进行分类?基于统计模型的K均值算法方法是关键,因为它允许进行统计模拟并按照经典统计学的思路研究分类的属性。本文阐述了ML分类在检验无聚类假设、使用模拟研究选择聚类数量的各种方法、使用拉普拉斯分布进行稳健聚类、研究聚类回归中系数的属性,以及最终通过将方差分量模型与K均值相结合来处理多级数据方面的应用。