National Center for Biotechnology Information (NCBI), National Library of Medicine (NLM), National Institutes of Health (NIH), Bethesda, Maryland, United States of America.
Swiss-Prot Group, SIB Swiss Institute of Bioinformatics, Geneva, Switzerland.
PLoS Comput Biol. 2018 Aug 13;14(8):e1006390. doi: 10.1371/journal.pcbi.1006390. eCollection 2018 Aug.
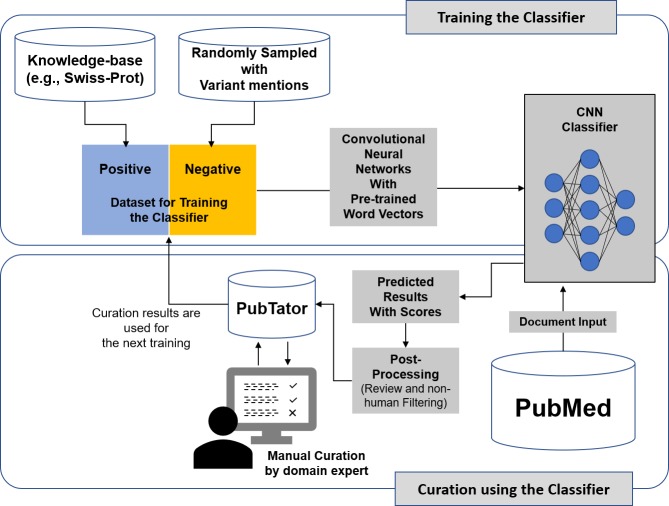
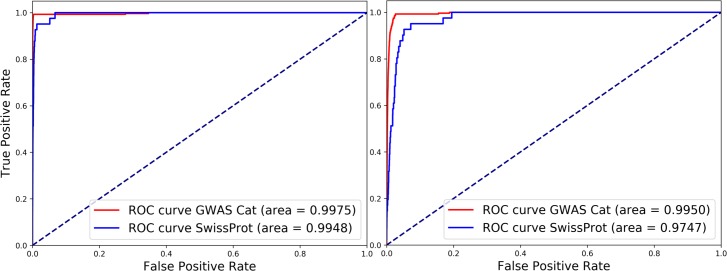
Manually curating biomedical knowledge from publications is necessary to build a knowledge based service that provides highly precise and organized information to users. The process of retrieving relevant publications for curation, which is also known as document triage, is usually carried out by querying and reading articles in PubMed. However, this query-based method often obtains unsatisfactory precision and recall on the retrieved results, and it is difficult to manually generate optimal queries. To address this, we propose a machine-learning assisted triage method. We collect previously curated publications from two databases UniProtKB/Swiss-Prot and the NHGRI-EBI GWAS Catalog, and used them as a gold-standard dataset for training deep learning models based on convolutional neural networks. We then use the trained models to classify and rank new publications for curation. For evaluation, we apply our method to the real-world manual curation process of UniProtKB/Swiss-Prot and the GWAS Catalog. We demonstrate that our machine-assisted triage method outperforms the current query-based triage methods, improves efficiency, and enriches curated content. Our method achieves a precision 1.81 and 2.99 times higher than that obtained by the current query-based triage methods of UniProtKB/Swiss-Prot and the GWAS Catalog, respectively, without compromising recall. In fact, our method retrieves many additional relevant publications that the query-based method of UniProtKB/Swiss-Prot could not find. As these results show, our machine learning-based method can make the triage process more efficient and is being implemented in production so that human curators can focus on more challenging tasks to improve the quality of knowledge bases.
从文献中人工整理生物医学知识对于构建基于知识的服务以向用户提供高度精确和有条理的信息是必要的。用于整理相关文献的检索过程(也称为文档分类)通常通过在 PubMed 中查询和阅读文章来完成。然而,这种基于查询的方法通常在检索结果上获得不理想的精度和召回率,并且很难手动生成最佳查询。为了解决这个问题,我们提出了一种机器学习辅助分类方法。我们从 UniProtKB/Swiss-Prot 和 NHGRI-EBI GWAS Catalog 两个数据库中收集了先前经过整理的出版物,并将它们用作基于卷积神经网络的深度学习模型的训练金标准数据集。然后,我们使用训练好的模型对新出版物进行分类和排序,以进行整理。在评估中,我们将我们的方法应用于 UniProtKB/Swiss-Prot 和 GWAS Catalog 的实际手动整理过程。我们证明,我们的机器辅助分类方法优于当前基于查询的分类方法,提高了效率,并丰富了整理后的内容。我们的方法实现了比 UniProtKB/Swiss-Prot 和 GWAS Catalog 中当前基于查询的分类方法分别高 1.81 倍和 2.99 倍的精度,而不会影响召回率。事实上,我们的方法检索到了许多基于查询的 UniProtKB/Swiss-Prot 方法无法找到的相关出版物。正如这些结果所示,我们的基于机器学习的方法可以使分类过程更高效,并正在生产中实施,以便人类整理者可以专注于更具挑战性的任务,从而提高知识库的质量。