Department of Biochemistry, Université de Sherbrooke, Sherbrooke, Québec, Canada.
PROTEO, Quebec Network for Research on Protein Function, Structure, and Engineering, Université de Lille, F-59000 Lille, France.
Nucleic Acids Res. 2019 Jan 8;47(D1):D403-D410. doi: 10.1093/nar/gky936.
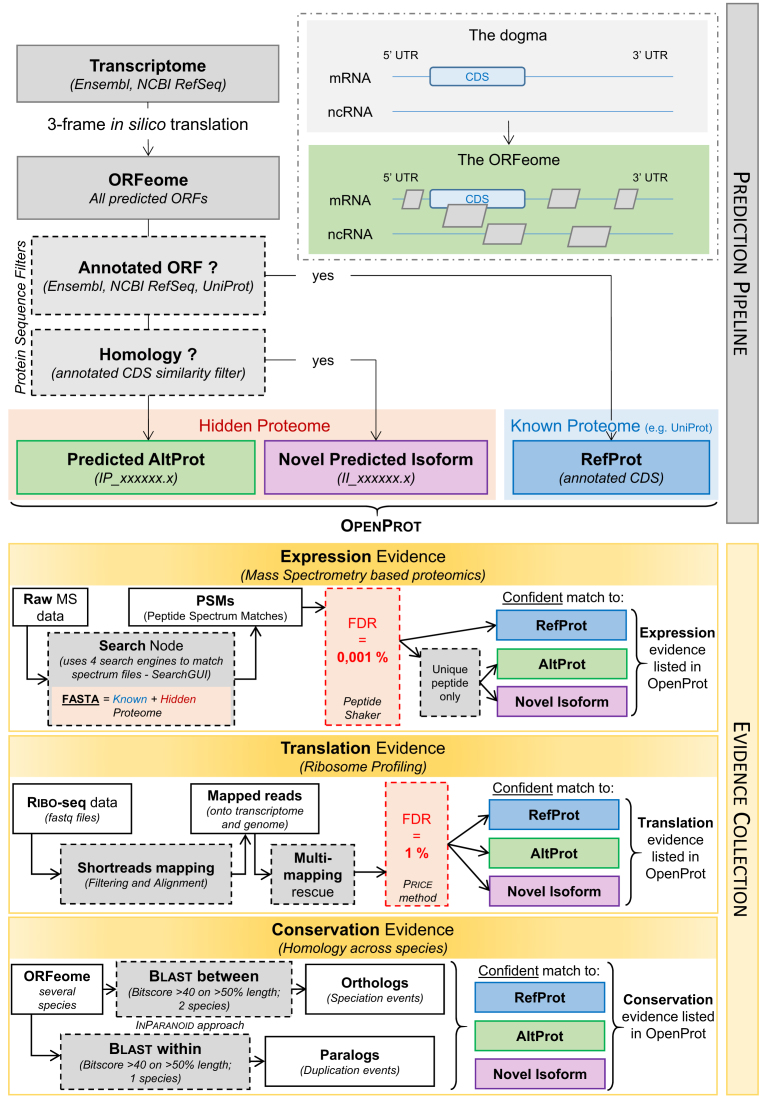
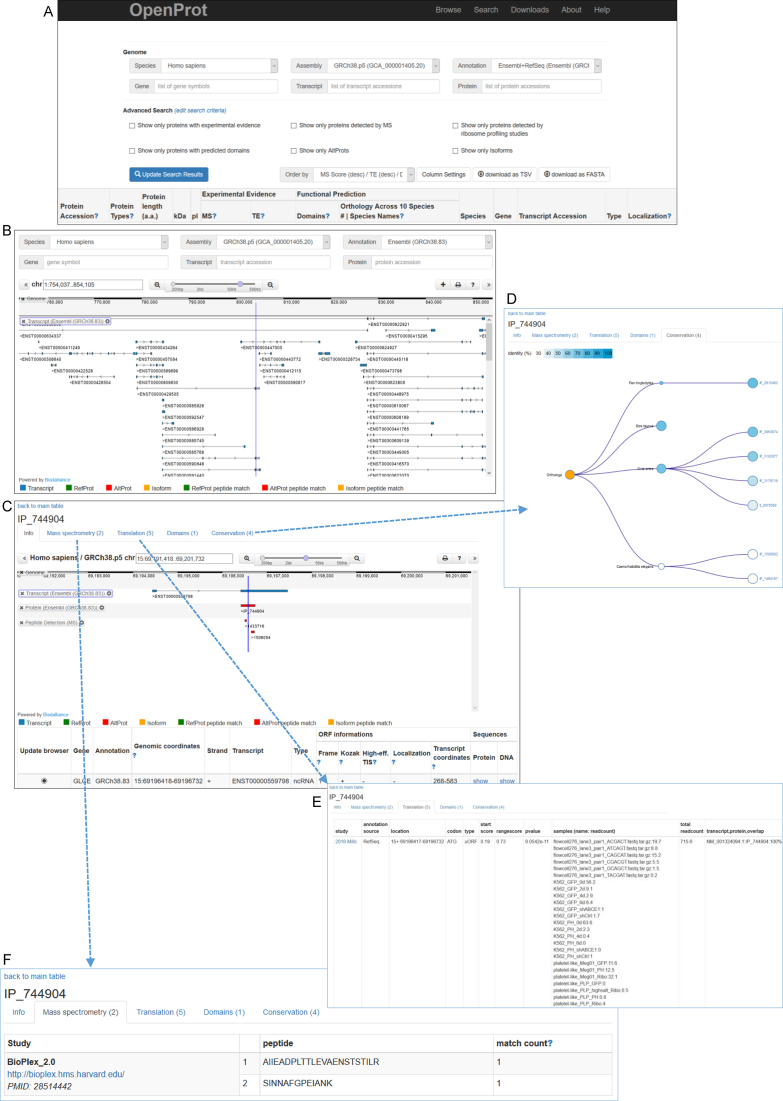
Advances in proteomics and sequencing have highlighted many non-annotated open reading frames (ORFs) in eukaryotic genomes. Genome annotations, cornerstones of today's research, mostly rely on protein prior knowledge and on ab initio prediction algorithms. Such algorithms notably enforce an arbitrary criterion of one coding sequence (CDS) per transcript, leading to a substantial underestimation of the coding potential of eukaryotes. Here, we present OpenProt, the first database fully endorsing a polycistronic model of eukaryotic genomes to date. OpenProt contains all possible ORFs longer than 30 codons across 10 species, and cumulates supporting evidence such as protein conservation, translation and expression. OpenProt annotates all known proteins (RefProts), novel predicted isoforms (Isoforms) and novel predicted proteins from alternative ORFs (AltProts). It incorporates cutting-edge algorithms to evaluate protein orthology and re-interrogate publicly available ribosome profiling and mass spectrometry datasets, supporting the annotation of thousands of predicted ORFs. The constantly growing database currently cumulates evidence from 87 ribosome profiling and 114 mass spectrometry studies from several species, tissues and cell lines. All data is freely available and downloadable from a web platform (www.openprot.org) supporting a genome browser and advanced queries for each species. Thus, OpenProt enables a more comprehensive landscape of eukaryotic genomes' coding potential.
蛋白质组学和测序技术的进步突显了真核生物基因组中许多未注释的开放阅读框(ORFs)。基因组注释是当今研究的基石,主要依赖于蛋白质先验知识和从头预测算法。这些算法特别强调每个转录本只有一个编码序列(CDS)的任意标准,导致真核生物的编码潜力被严重低估。在这里,我们介绍了 OpenProt,这是迄今为止第一个完全支持真核生物基因组多顺反子模型的数据库。OpenProt 包含了 10 个物种中所有长度超过 30 个密码子的可能的 ORFs,并累积了支持证据,如蛋白质保守性、翻译和表达。OpenProt 注释了所有已知的蛋白质(RefProts)、新预测的同工型(Isoforms)和来自替代 ORFs 的新预测蛋白质(AltProts)。它整合了最新的算法来评估蛋白质的同源性,并重新分析公共核糖体图谱和质谱数据集,支持对数千个预测 ORFs 的注释。这个不断增长的数据库目前从多个物种、组织和细胞系的 87 个核糖体图谱和 114 个质谱研究中累积了证据。所有数据均可从一个支持基因组浏览器和每个物种高级查询的网络平台(www.openprot.org)上免费获取和下载。因此,OpenProt 能够更全面地了解真核生物基因组的编码潜力。