Department of Engineering, Uninettuno International University, Corso Vittorio Emanuele II 39, Rome, 00186, Italy.
Institute of Systems Analysis and Computer Science "A. Ruberti", National Research Council, Via dei Taurini 19, Rome, 00185, Italy.
BMC Bioinformatics. 2018 Oct 15;19(Suppl 10):354. doi: 10.1186/s12859-018-2299-7.
The high growth of Next Generation Sequencing data currently demands new knowledge extraction methods. In particular, the RNA sequencing gene expression experimental technique stands out for case-control studies on cancer, which can be addressed with supervised machine learning techniques able to extract human interpretable models composed of genes, and their relation to the investigated disease. State of the art rule-based classifiers are designed to extract a single classification model, possibly composed of few relevant genes. Conversely, we aim to create a large knowledge base composed of many rule-based models, and thus determine which genes could be potentially involved in the analyzed tumor. This comprehensive and open access knowledge base is required to disseminate novel insights about cancer.
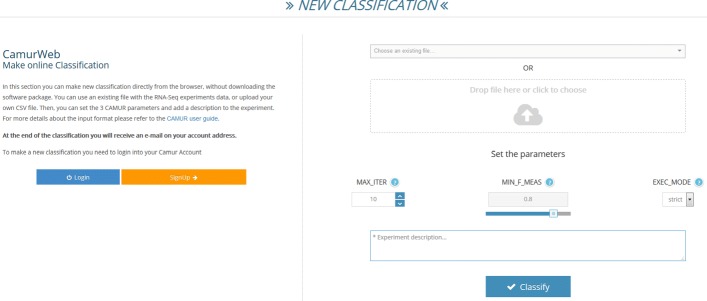
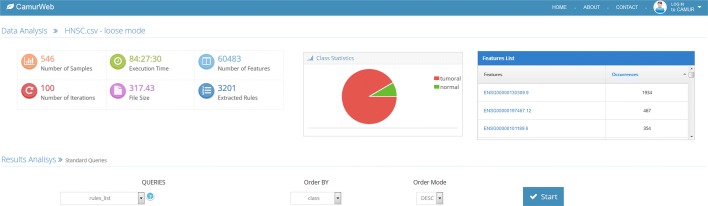
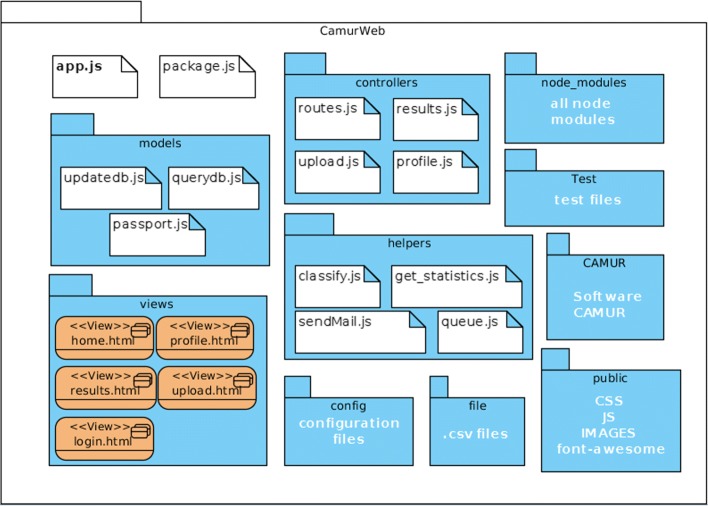
We propose CamurWeb, a new method and web-based software that is able to extract multiple and equivalent classification models in form of logic formulas ("if then" rules) and to create a knowledge base of these rules that can be queried and analyzed. The method is based on an iterative classification procedure and an adaptive feature elimination technique that enables the computation of many rule-based models related to the cancer under study. Additionally, CamurWeb includes a user friendly interface for running the software, querying the results, and managing the performed experiments. The user can create her profile, upload her gene expression data, run the classification analyses, and interpret the results with predefined queries. In order to validate the software we apply it to all public available RNA sequencing datasets from The Cancer Genome Atlas database obtaining a large open access knowledge base about cancer. CamurWeb is available at http://bioinformatics.iasi.cnr.it/camurweb .
The experiments prove the validity of CamurWeb, obtaining many classification models and thus several genes that are associated to 21 different cancer types. Finally, the comprehensive knowledge base about cancer and the software tool are released online; interested researchers have free access to them for further studies and to design biological experiments in cancer research.
下一代测序数据的高速增长目前需要新的知识提取方法。特别是 RNA 测序基因表达实验技术在癌症的病例对照研究中脱颖而出,可以采用监督机器学习技术来提取由基因及其与所研究疾病的关系组成的人类可解释模型。基于规则的最新分类器旨在提取单一的分类模型,该模型可能由少数相关基因组成。相反,我们旨在创建一个由许多基于规则的模型组成的大型知识库,并确定哪些基因可能潜在参与分析中的肿瘤。这个全面的、开放获取的知识库是传播有关癌症的新见解所必需的。
我们提出了 CamurWeb,这是一种新的方法和基于网络的软件,能够以逻辑公式(“如果那么”规则)的形式提取多个等效的分类模型,并创建这些规则的知识库,可对其进行查询和分析。该方法基于迭代分类过程和自适应特征消除技术,能够计算与所研究癌症相关的许多基于规则的模型。此外,CamurWeb 包括一个用户友好的界面,用于运行软件、查询结果和管理执行的实验。用户可以创建自己的个人资料,上传她的基因表达数据,运行分类分析,并使用预定义查询解释结果。为了验证软件,我们将其应用于来自癌症基因组图谱数据库的所有公开可用的 RNA 测序数据集,获得了一个关于癌症的大型开放获取知识库。CamurWeb 可在 http://bioinformatics.iasi.cnr.it/camurweb 上获得。
实验证明了 CamurWeb 的有效性,获得了许多分类模型,从而获得了与 21 种不同癌症类型相关的多个基因。最后,癌症的综合知识库和软件工具在线发布;感兴趣的研究人员可以免费访问它们,以进行进一步的研究和设计癌症研究中的生物学实验。