Skolkovo Institute of Science and Technology, Center for Computational and Data-Intensive Science and Engineering, Moscow, 143026, Russia.
Institute of Numerical Mathematics of the Russian Academy of Sciences, Moscow, 119991, Russia.
Sci Rep. 2018 Nov 19;8(1):17053. doi: 10.1038/s41598-018-35399-z.
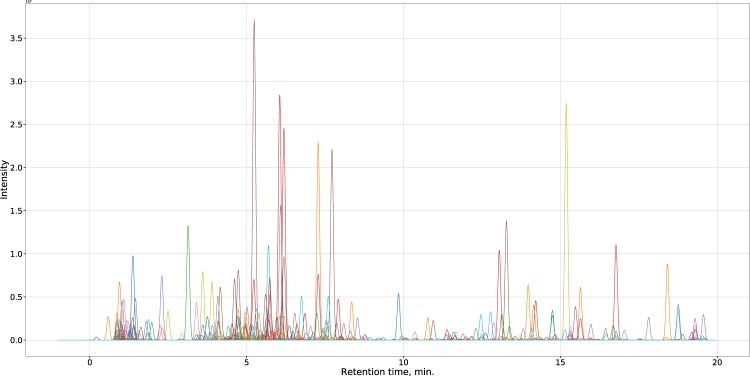
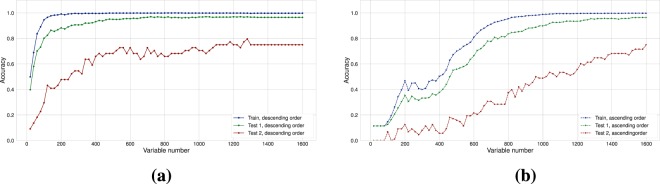
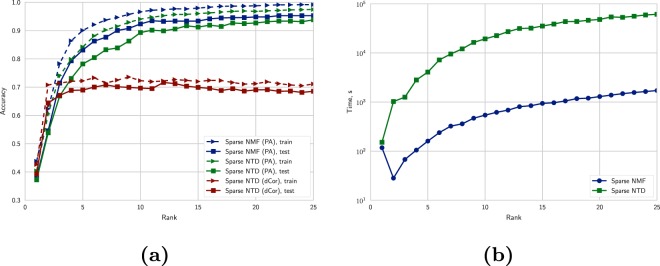
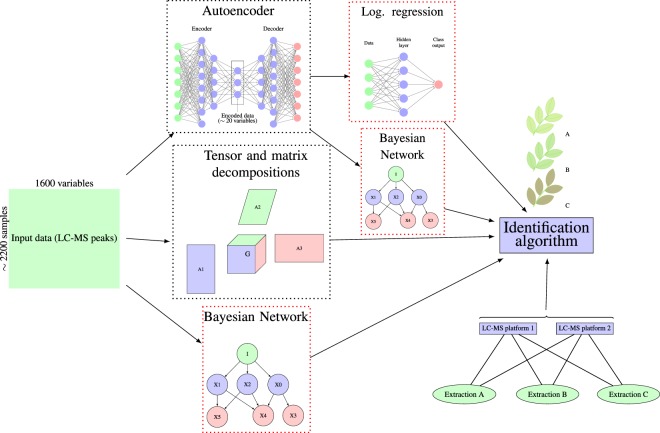
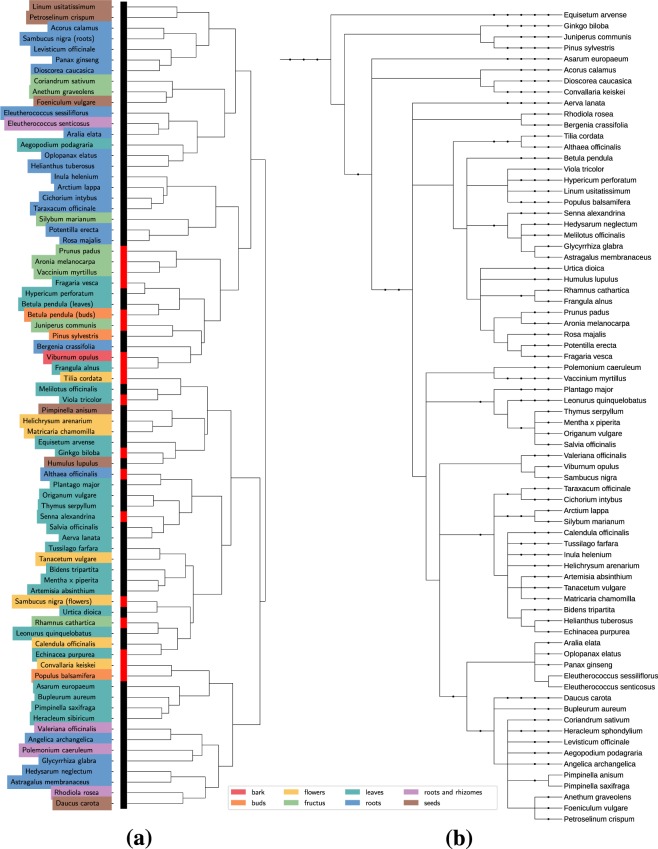
A dataset of liquid chromatography-mass spectrometry measurements of medicinal plant extracts from 74 species was generated and used for training and validating plant species identification algorithms. Various strategies for data handling and feature space extraction were tested. Constrained Tucker decomposition, large-scale (more than 1500 variables) discrete Bayesian Networks and autoencoder based dimensionality reduction coupled with continuous Bayes classifier and logistic regression were optimized to achieve the best accuracy. Even with elimination of all retention time values accuracies of up to 96% and 92% were achieved on validation set for plant species and plant organ identification respectively. Benefits and drawbacks of used algortihms were discussed. Preliminary test showed that developed approaches exhibit tolerance to changes in data created by using different extraction methods and/or equipment. Dataset with more than 2200 chromatograms was published in an open repository.
生成了一个包含 74 种药用植物提取物的液相色谱-质谱测量数据集,并用于训练和验证植物物种识别算法。测试了各种数据处理和特征空间提取策略。优化了约束 Tucker 分解、大规模(超过 1500 个变量)离散贝叶斯网络和基于自动编码器的降维,以及连续贝叶斯分类器和逻辑回归,以获得最佳准确性。即使消除了所有保留时间值,在验证集上,植物物种和植物器官识别的准确率仍分别高达 96%和 92%。讨论了所使用算法的优缺点。初步测试表明,开发的方法对使用不同提取方法和/或设备创建的数据变化具有耐受性。包含超过 2200 个色谱图的数据集已在开放存储库中发布。