University of South Dakota, Vermillion, SD, USA.
University of North Carolina at Greensboro, Greensboro, NC, USA.
Database (Oxford). 2018 Jan 1;2018:bay110. doi: 10.1093/database/bay110.
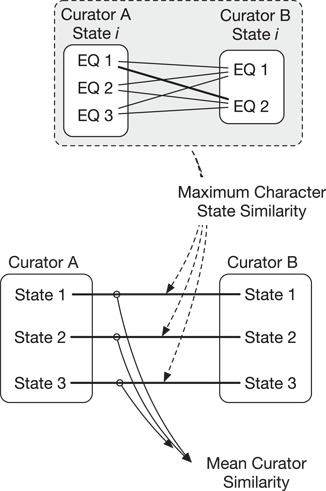
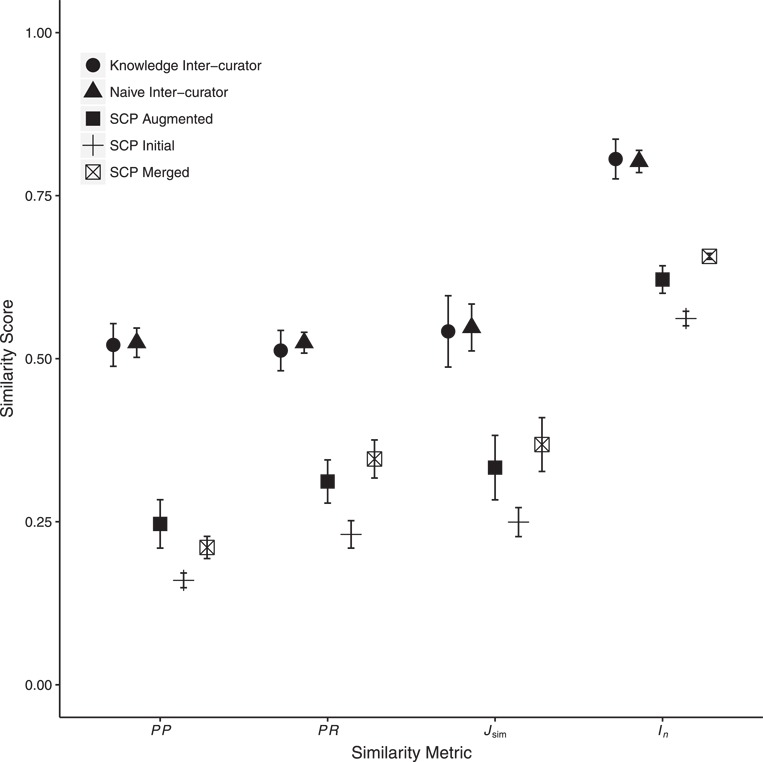
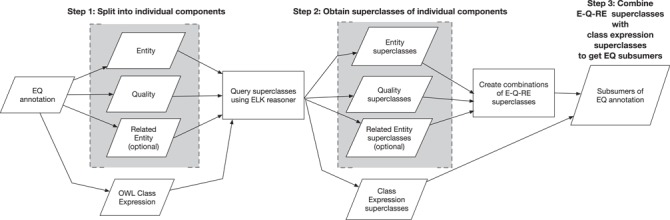
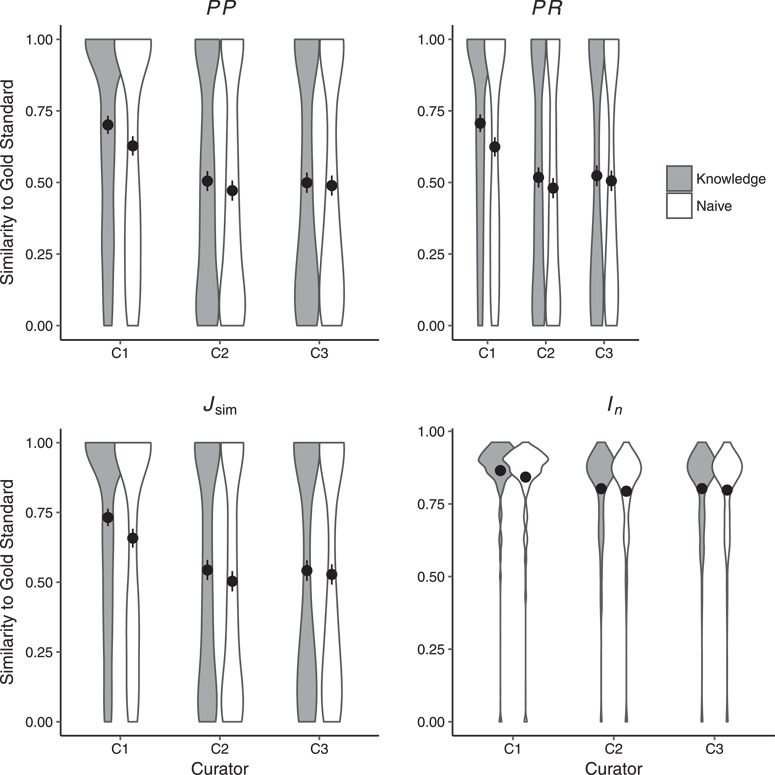
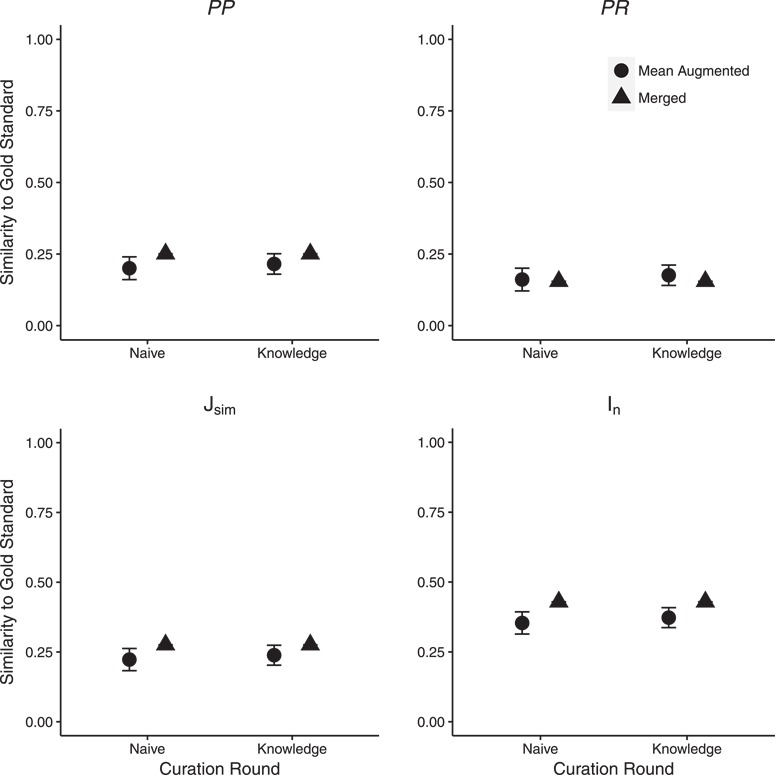
Natural language descriptions of organismal phenotypes, a principal object of study in biology, are abundant in the biological literature. Expressing these phenotypes as logical statements using ontologies would enable large-scale analysis on phenotypic information from diverse systems. However, considerable human effort is required to make these phenotype descriptions amenable to machine reasoning. Natural language processing tools have been developed to facilitate this task, and the training and evaluation of these tools depend on the availability of high quality, manually annotated gold standard data sets. We describe the development of an expert-curated gold standard data set of annotated phenotypes for evolutionary biology. The gold standard was developed for the curation of complex comparative phenotypes for the Phenoscape project. It was created by consensus among three curators and consists of entity-quality expressions of varying complexity. We use the gold standard to evaluate annotations created by human curators and those generated by the Semantic CharaParser tool. Using four annotation accuracy metrics that can account for any level of relationship between terms from two phenotype annotations, we found that machine-human consistency, or similarity, was significantly lower than inter-curator (human-human) consistency. Surprisingly, allowing curatorsaccess to external information did not significantly increase the similarity of their annotations to the gold standard or have a significant effect on inter-curator consistency. We found that the similarity of machine annotations to the gold standard increased after new relevant ontology terms had been added. Evaluation by the original authors of the character descriptions indicated that the gold standard annotations came closer to representing their intended meaning than did either the curator or machine annotations. These findings point toward ways to better design software to augment human curators and the use of the gold standard corpus will allow training and assessment of new tools to improve phenotype annotation accuracy at scale.
生物学术文献中大量存在对生物体表型的自然语言描述,这是生物学研究的主要对象。使用本体将这些表型表达为逻辑语句,将使来自不同系统的表型信息能够进行大规模分析。然而,要使这些表型描述能够适应机器推理,需要大量的人力。已经开发了自然语言处理工具来促进这项任务,这些工具的培训和评估依赖于高质量的、手动注释的黄金标准数据集的可用性。我们描述了一个用于进化生物学的专家编纂的注释表型黄金标准数据集的开发。该黄金标准是为 Phenoscape 项目中复杂的比较表型的编纂而开发的。它是由三位编纂者达成共识创建的,由不同复杂程度的实体质量表达式组成。我们使用黄金标准来评估由人类编纂者创建的注释和由 Semantic CharaParser 工具生成的注释。使用四个可以考虑两个表型注释中术语之间任何关系程度的注释准确性度量标准,我们发现机器与人类的一致性,或相似性,明显低于编纂者(人类对人类)之间的一致性。令人惊讶的是,允许编纂者访问外部信息并没有显著提高他们的注释与黄金标准的相似性,也没有对编纂者之间的一致性产生显著影响。我们发现,在添加新的相关本体术语后,机器注释与黄金标准的相似性增加了。对特征描述的原始作者进行评估表明,黄金标准注释比编纂者或机器注释更能代表他们的意图。这些发现为更好地设计软件以增强人类编纂者提供了方向,并且黄金标准语料库的使用将允许培训和评估新工具,以提高大规模表型注释的准确性。