Cognitive Systems Lab, University of Bremen, Bremen, Germany.
J Neural Eng. 2019 Jun;16(3):036019. doi: 10.1088/1741-2552/ab0c59. Epub 2019 Mar 4.
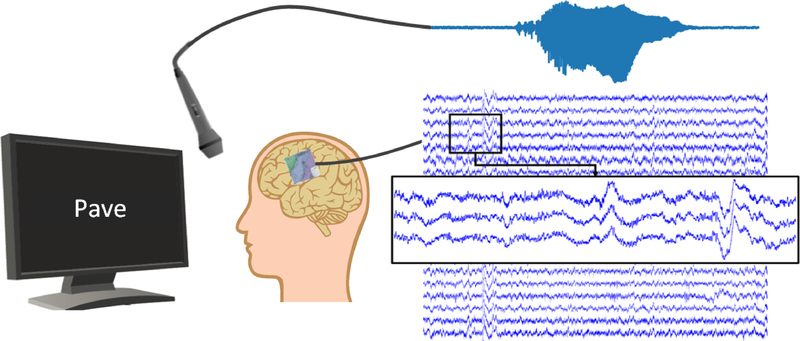
Direct synthesis of speech from neural signals could provide a fast and natural way of communication to people with neurological diseases. Invasively-measured brain activity (electrocorticography; ECoG) supplies the necessary temporal and spatial resolution to decode fast and complex processes such as speech production. A number of impressive advances in speech decoding using neural signals have been achieved in recent years, but the complex dynamics are still not fully understood. However, it is unlikely that simple linear models can capture the relation between neural activity and continuous spoken speech.
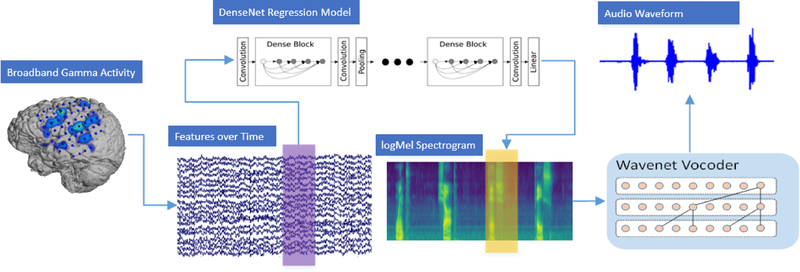
Here we show that deep neural networks can be used to map ECoG from speech production areas onto an intermediate representation of speech (logMel spectrogram). The proposed method uses a densely connected convolutional neural network topology which is well-suited to work with the small amount of data available from each participant.
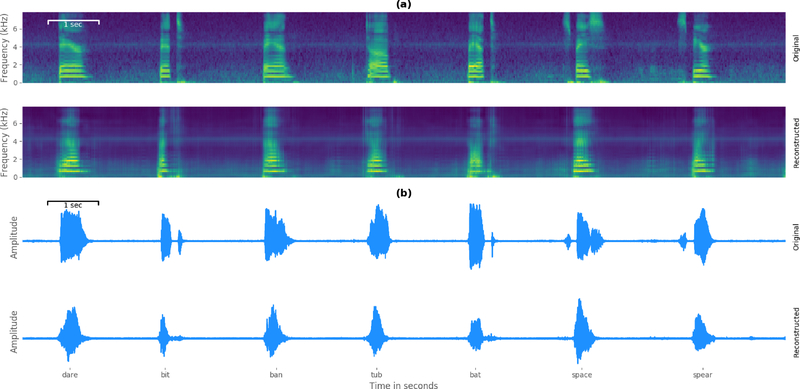
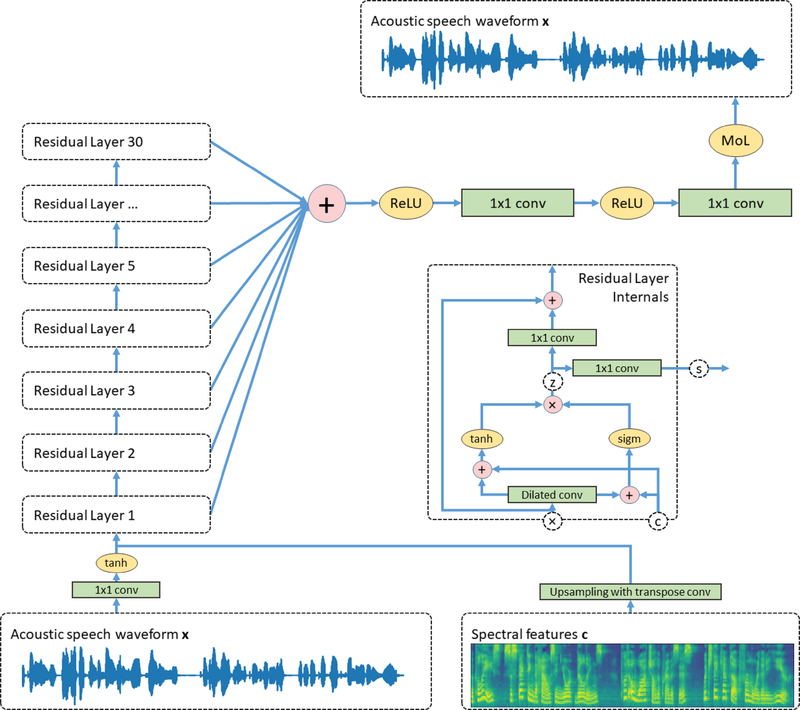
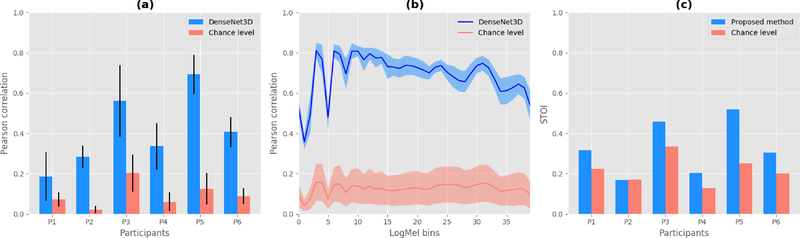
In a study with six participants, we achieved correlations up to r = 0.69 between the reconstructed and original logMel spectrograms. We transfered our prediction back into an audible waveform by applying a Wavenet vocoder. The vocoder was conditioned on logMel features that harnessed a much larger, pre-existing data corpus to provide the most natural acoustic output.
To the best of our knowledge, this is the first time that high-quality speech has been reconstructed from neural recordings during speech production using deep neural networks.
通过神经信号直接合成语音,可以为患有神经疾病的人提供一种快速自然的交流方式。侵入性测量的大脑活动(脑电图;ECoG)提供了必要的时间和空间分辨率,以解码快速和复杂的过程,如语音产生。近年来,使用神经信号进行语音解码方面取得了许多令人印象深刻的进展,但复杂的动态仍然没有被完全理解。然而,简单的线性模型不太可能捕捉到神经活动与连续语音之间的关系。
在这里,我们展示了深度神经网络可以用于将语音产生区域的 ECoG 映射到语音的中间表示(对数梅尔频谱图)上。所提出的方法使用密集连接的卷积神经网络拓扑结构,非常适合使用每个参与者可用的少量数据进行工作。
在一项有六名参与者的研究中,我们实现了重建和原始对数梅尔频谱图之间高达 r=0.69 的相关性。我们通过应用 Wavenet 声码器将我们的预测转换回可听见的波形。声码器的条件是对数梅尔特征,利用了更大的、预先存在的数据语料库,以提供最自然的声学输出。
据我们所知,这是第一次使用深度神经网络从语音产生期间的神经记录中重建高质量的语音。