Shikder Rayhan, Thulasiraman Parimala, Irani Pourang, Hu Pingzhao
Department of Computer Science, University of Manitoba, Winnipeg, MB, Canada.
Department of Biochemistry and Medical Genetics and The George and Fay Yee Centre for Healthcare Innovation, University of Manitoba, Room 308-Basic Medical Sciences Building, 745 Bannatyne Avenue, Winnipeg, MB, R3E 0J9, Canada.
BMC Res Notes. 2019 Apr 11;12(1):220. doi: 10.1186/s13104-019-4256-6.
Finding the longest common subsequence (LCS) among sequences is NP-hard. This is an important problem in bioinformatics for DNA sequence alignment and pattern discovery. In this research, we propose new CPU-based parallel implementations that can provide significant advantages in terms of execution times, monetary cost, and pervasiveness in finding LCS of DNA sequences in an environment where Graphics Processing Units are not available. For general purpose use, we also make the OpenMP-based tool publicly available to end users.
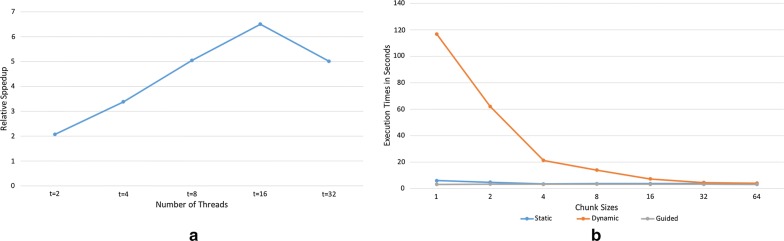
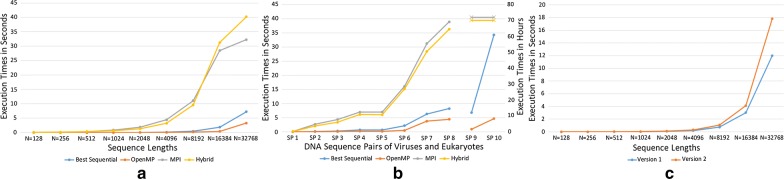
In this study, we develop three novel parallel versions of the LCS algorithm on: (i) distributed memory machine using message passing interface (MPI); (ii) shared memory machine using OpenMP, and (iii) hybrid platform that utilizes both distributed and shared memory using MPI-OpenMP. The experimental results with both simulated and real DNA sequence data show that the shared memory OpenMP implementation provides at least two-times absolute speedup than the best sequential version of the algorithm and a relative speedup of almost 7. We provide a detailed comparison of the execution times among the implementations on different platforms with different versions of the algorithm. We also show that removing branch conditions negatively affects the performance of the CPU-based parallel algorithm on OpenMP platform.
在序列中寻找最长公共子序列(LCS)是NP难问题。这是生物信息学中DNA序列比对和模式发现的一个重要问题。在本研究中,我们提出了基于CPU的新并行实现方法,在没有图形处理单元的环境下,这些方法在执行时间、成本和普及性方面具有显著优势,可用于寻找DNA序列的LCS。为了便于通用,我们还向终端用户公开了基于OpenMP的工具。
在本研究中,我们在以下平台上开发了LCS算法的三个新颖并行版本:(i)使用消息传递接口(MPI)的分布式内存机器;(ii)使用OpenMP的共享内存机器;(iii)利用MPI-OpenMP同时使用分布式和共享内存的混合平台。对模拟和真实DNA序列数据的实验结果表明,共享内存OpenMP实现比该算法的最佳顺序版本提供了至少两倍的绝对加速比,相对加速比接近7。我们详细比较了不同平台上不同版本算法实现之间的执行时间。我们还表明,去除分支条件会对基于CPU的并行算法在OpenMP平台上的性能产生负面影响。