Brain-Mind-Institute, School of Life Sciences, École Polytechnique Fédérale de Lausanne, Lausanne, Switzerland.
School of Computer and Communication Sciences, École Polytechnique Fédérale de Lausanne, Lausanne, Switzerland.
Elife. 2019 Nov 11;8:e47463. doi: 10.7554/eLife.47463.
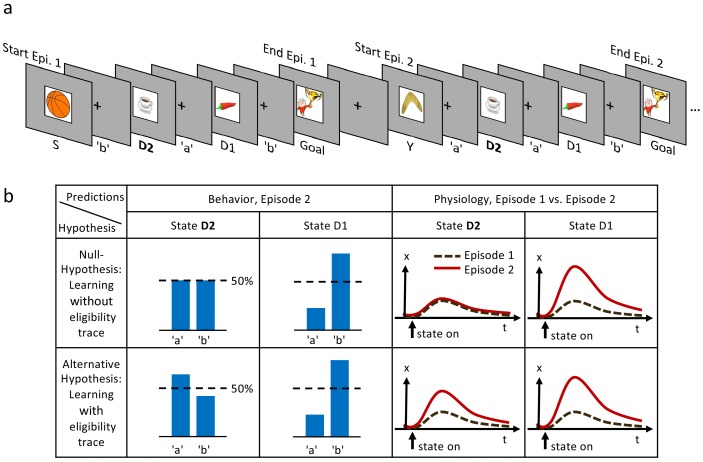
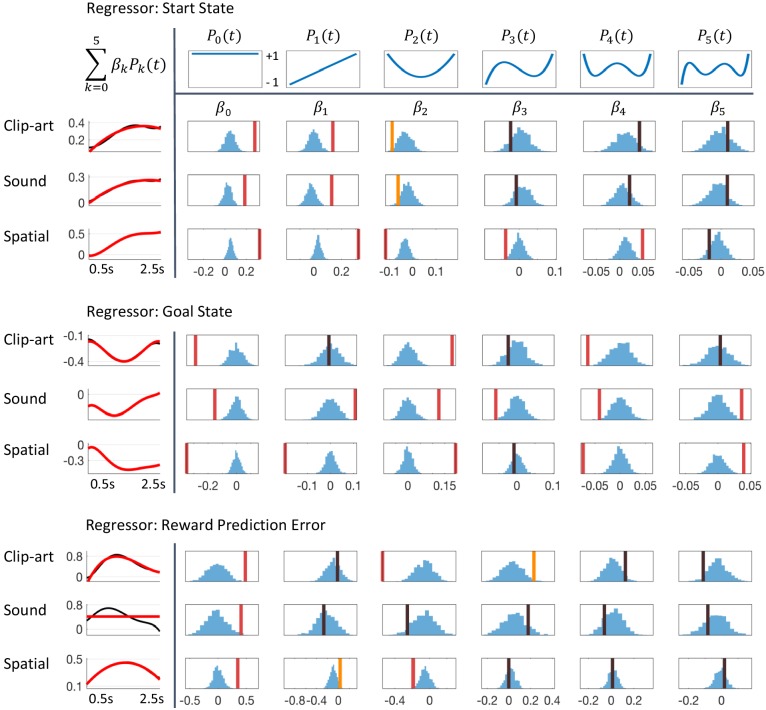
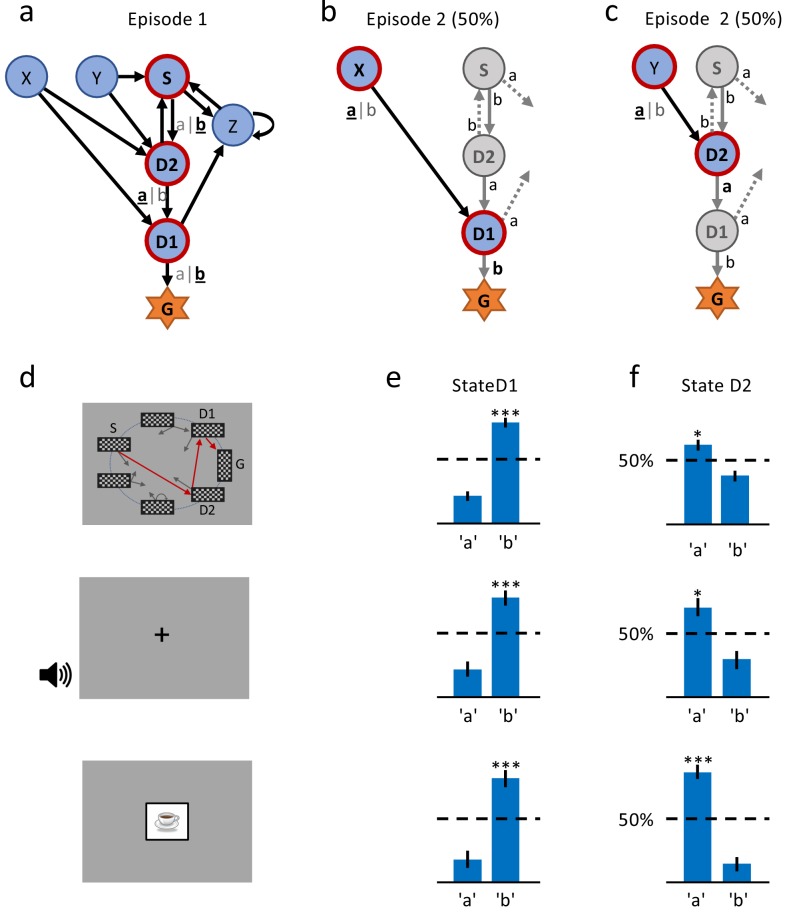
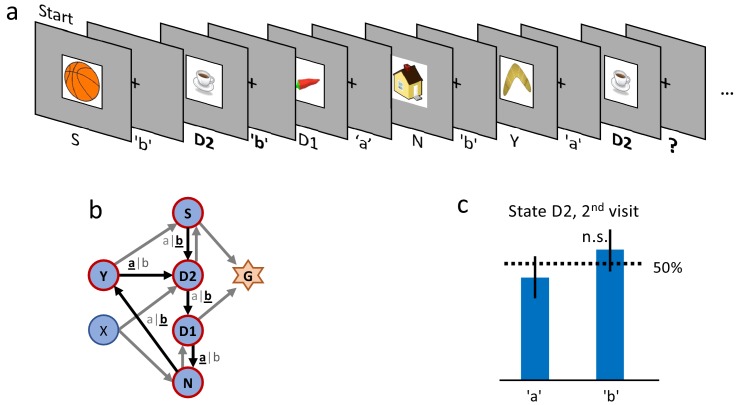
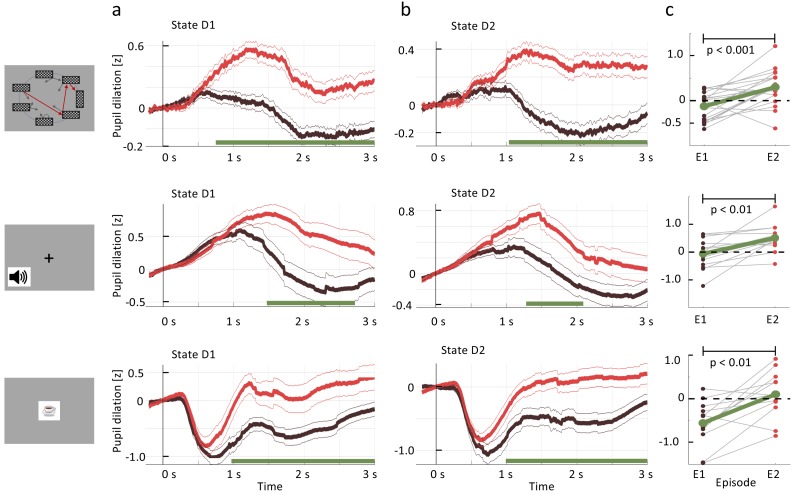
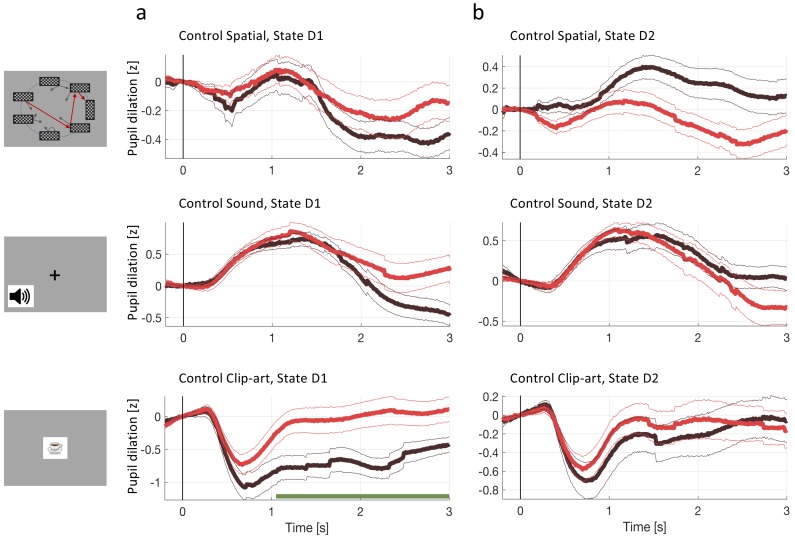
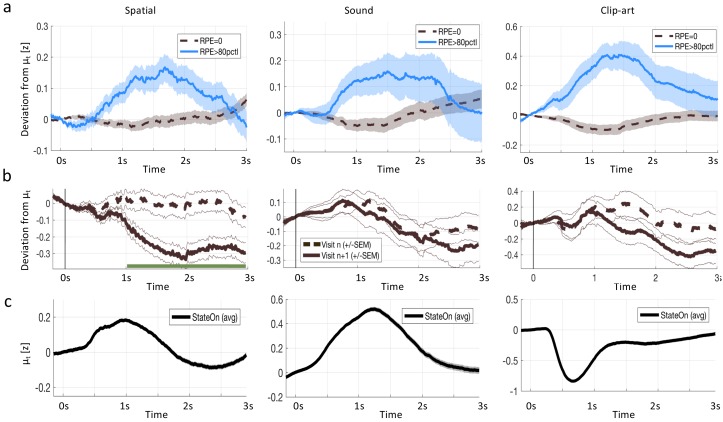
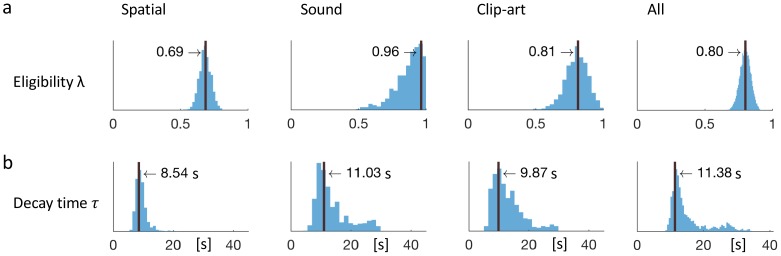
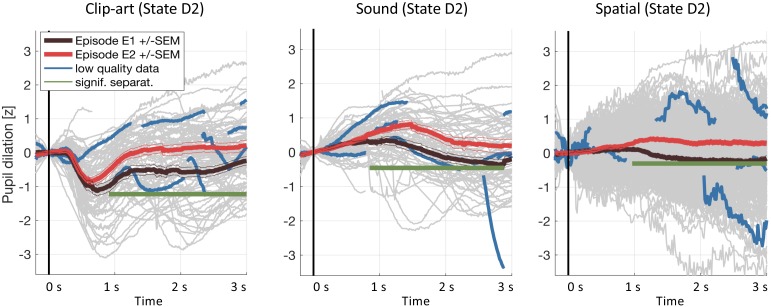
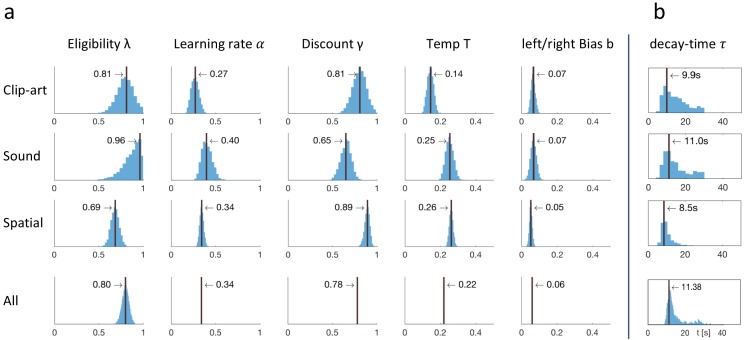
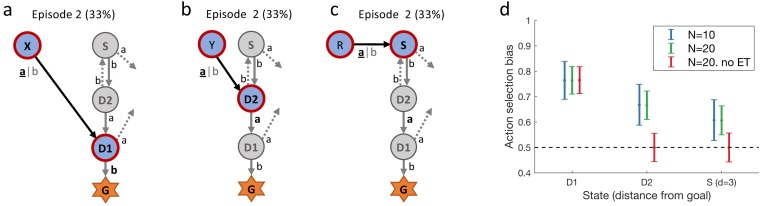
In many daily tasks, we make multiple decisions before reaching a goal. In order to learn such sequences of decisions, a mechanism to link earlier actions to later reward is necessary. Reinforcement learning (RL) theory suggests two classes of algorithms solving this credit assignment problem: In classic temporal-difference learning, earlier actions receive reward information only after multiple repetitions of the task, whereas models with eligibility traces reinforce entire sequences of actions from a single experience (one-shot). Here, we show one-shot learning of sequences. We developed a novel paradigm to observe which actions and states along a multi-step sequence are reinforced after a single reward. By focusing our analysis on those states for which RL with and without eligibility trace make qualitatively distinct predictions, we find direct behavioral (choice probability) and physiological (pupil dilation) signatures of reinforcement learning with eligibility trace across multiple sensory modalities.
在许多日常任务中,我们在达到目标之前会做出多次决策。为了学习这种决策序列,需要有一种将早期行动与后期奖励联系起来的机制。强化学习(RL)理论提出了两类解决这种信用分配问题的算法:在经典的时间差分学习中,早期的行动只有在多次重复任务后才会收到奖励信息,而具有资格痕迹的模型则会从单次体验(单次)中强化整个动作序列。在这里,我们展示了序列的单次学习。我们开发了一种新的范例,观察在单次奖励后,沿着多步骤序列的哪些动作和状态得到了强化。通过将我们的分析集中在那些具有和不具有资格痕迹的 RL 做出定性不同预测的状态上,我们发现了具有资格痕迹的强化学习在多个感觉模态中的直接行为(选择概率)和生理(瞳孔扩张)特征。