School of Electrical and Computer Engineering, UNIST, Ulsan, Republic of Korea.
Department of Biomedical Engineering, School of Life Sciences, UNIST, Ulsan, Republic of Korea.
Sci Rep. 2019 Nov 15;9(1):16927. doi: 10.1038/s41598-019-53034-3.
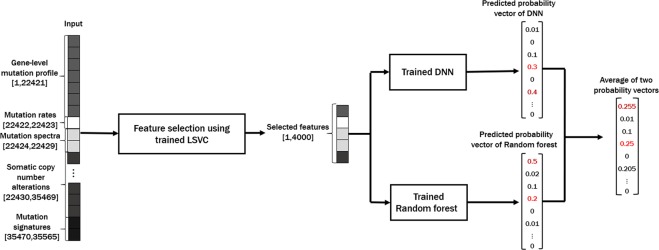
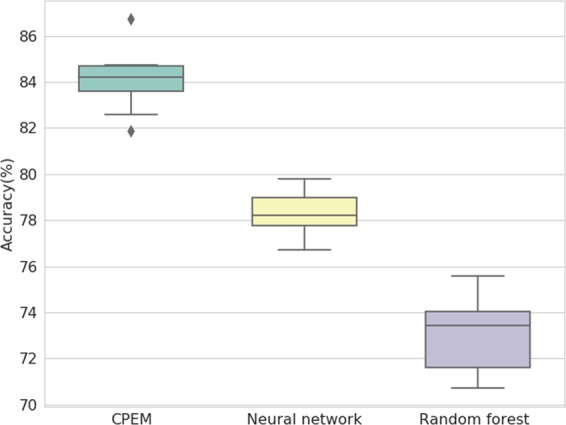
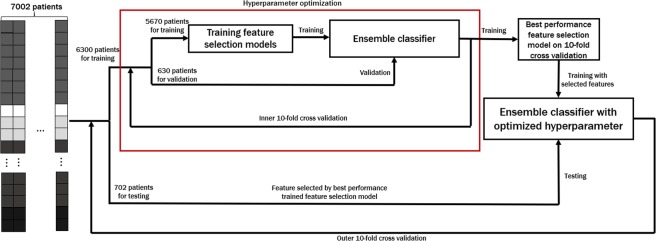
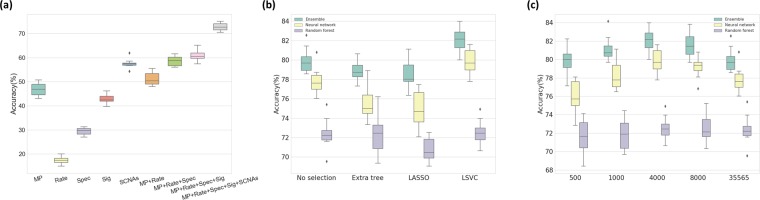
With recent advances in DNA sequencing technologies, fast acquisition of large-scale genomic data has become commonplace. For cancer studies, in particular, there is an increasing need for the classification of cancer type based on somatic alterations detected from sequencing analyses. However, the ever-increasing size and complexity of the data make the classification task extremely challenging. In this study, we evaluate the contributions of various input features, such as mutation profiles, mutation rates, mutation spectra and signatures, and somatic copy number alterations that can be derived from genomic data, and further utilize them for accurate cancer type classification. We introduce a novel ensemble of machine learning classifiers, called CPEM (Cancer Predictor using an Ensemble Model), which is tested on 7,002 samples representing over 31 different cancer types collected from The Cancer Genome Atlas (TCGA) database. We first systematically examined the impact of the input features. Features known to be associated with specific cancers had relatively high importance in our initial prediction model. We further investigated various machine learning classifiers and feature selection methods to derive the ensemble-based cancer type prediction model achieving up to 84% classification accuracy in the nested 10-fold cross-validation. Finally, we narrowed down the target cancers to the six most common types and achieved up to 94% accuracy.
随着 DNA 测序技术的最新进展,大规模基因组数据的快速获取已变得司空见惯。特别是对于癌症研究,基于测序分析中检测到的体细胞改变对癌症类型进行分类的需求日益增加。然而,数据的规模和复杂性不断增加,使得分类任务极具挑战性。在这项研究中,我们评估了各种输入特征(如突变谱、突变率、突变特征和体细胞拷贝数改变等)的贡献,这些特征可以从基因组数据中得出,并进一步利用它们进行准确的癌症类型分类。我们引入了一种名为 CPEM(使用集成模型的癌症预测器)的新型机器学习分类器集成,该分类器在来自癌症基因组图谱(TCGA)数据库的 7002 个样本上进行了测试,这些样本代表了 31 种不同的癌症类型。我们首先系统地研究了输入特征的影响。在我们的初始预测模型中,与特定癌症相关的特征具有相对较高的重要性。我们进一步研究了各种机器学习分类器和特征选择方法,以得出基于集成的癌症类型预测模型,在嵌套的 10 倍交叉验证中达到了高达 84%的分类准确性。最后,我们将目标癌症缩小到六种最常见的类型,并达到了高达 94%的准确性。