Department of Biostatistics & Health Informatics, Institute of Psychiatry, Psychology and Neuroscience, King's College London, London, UK.
Population, Policy and Practice Research and Teaching Department, UCL Great Ormond Street Institute of Child Health, University College London, 30 Guilford Street, London, WC1N 1EH, UK.
Eur J Epidemiol. 2020 Mar;35(3):205-222. doi: 10.1007/s10654-020-00615-6. Epub 2020 Mar 5.
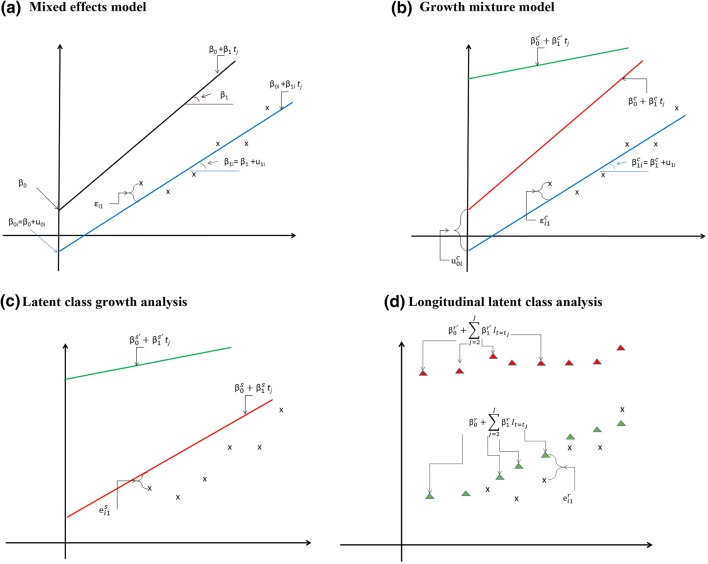
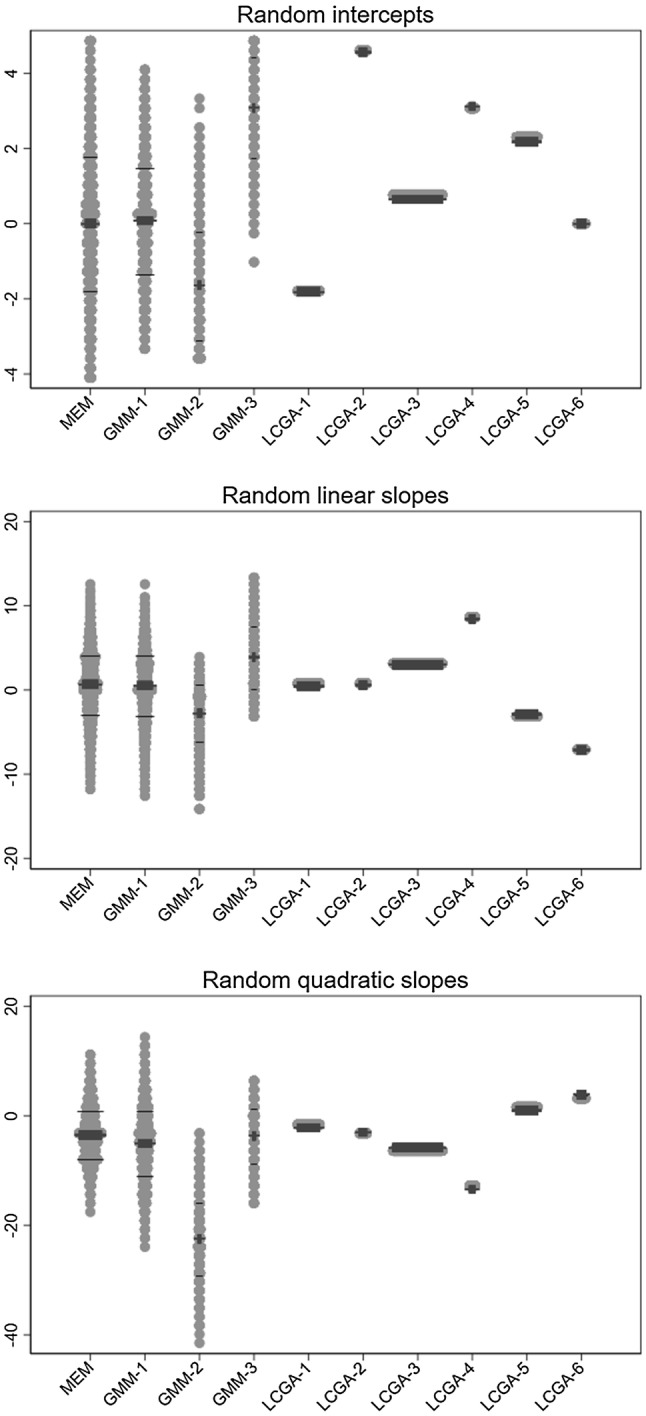
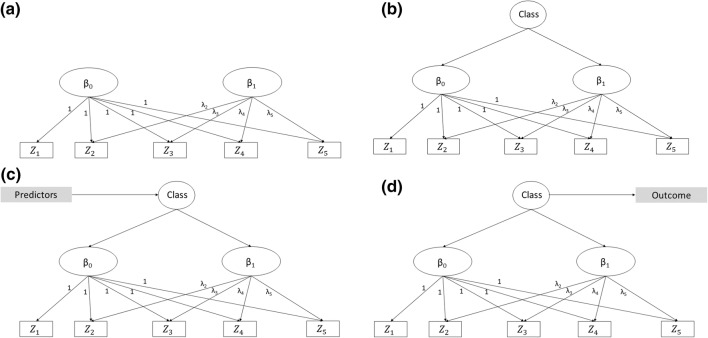
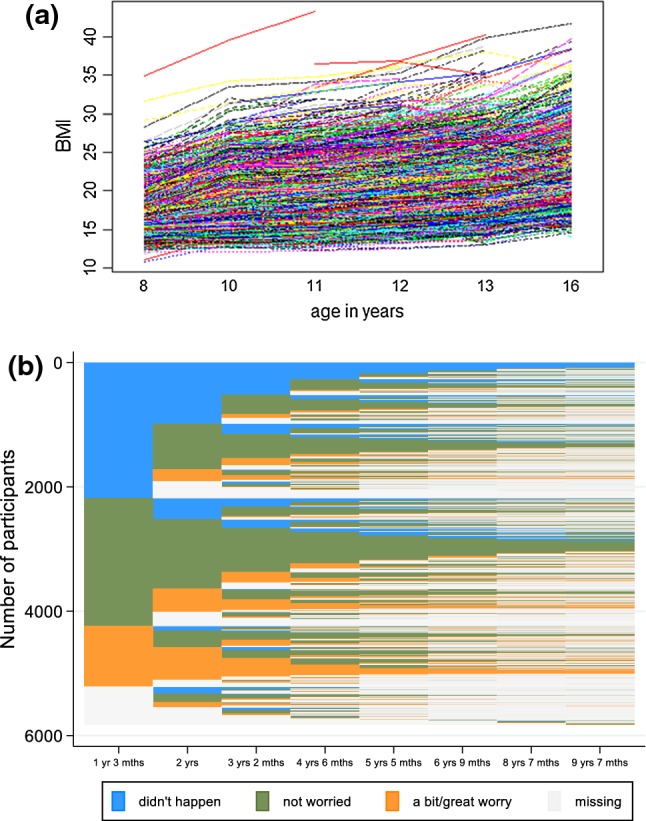
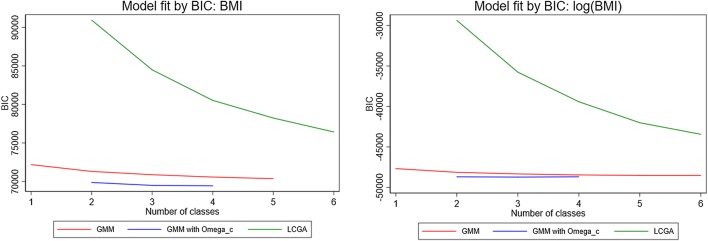
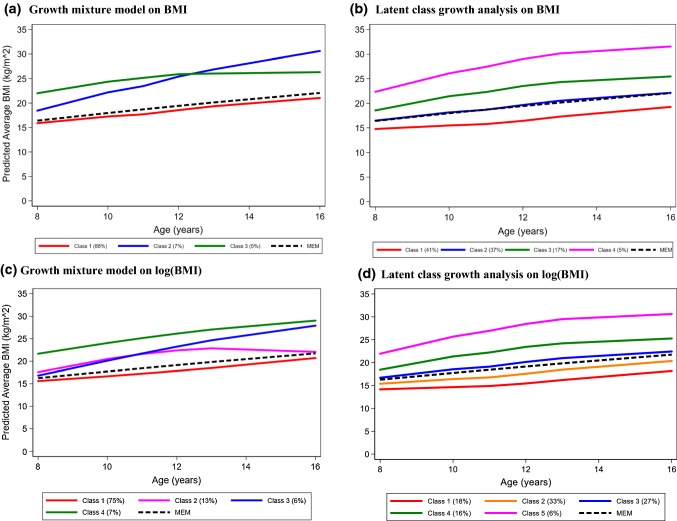
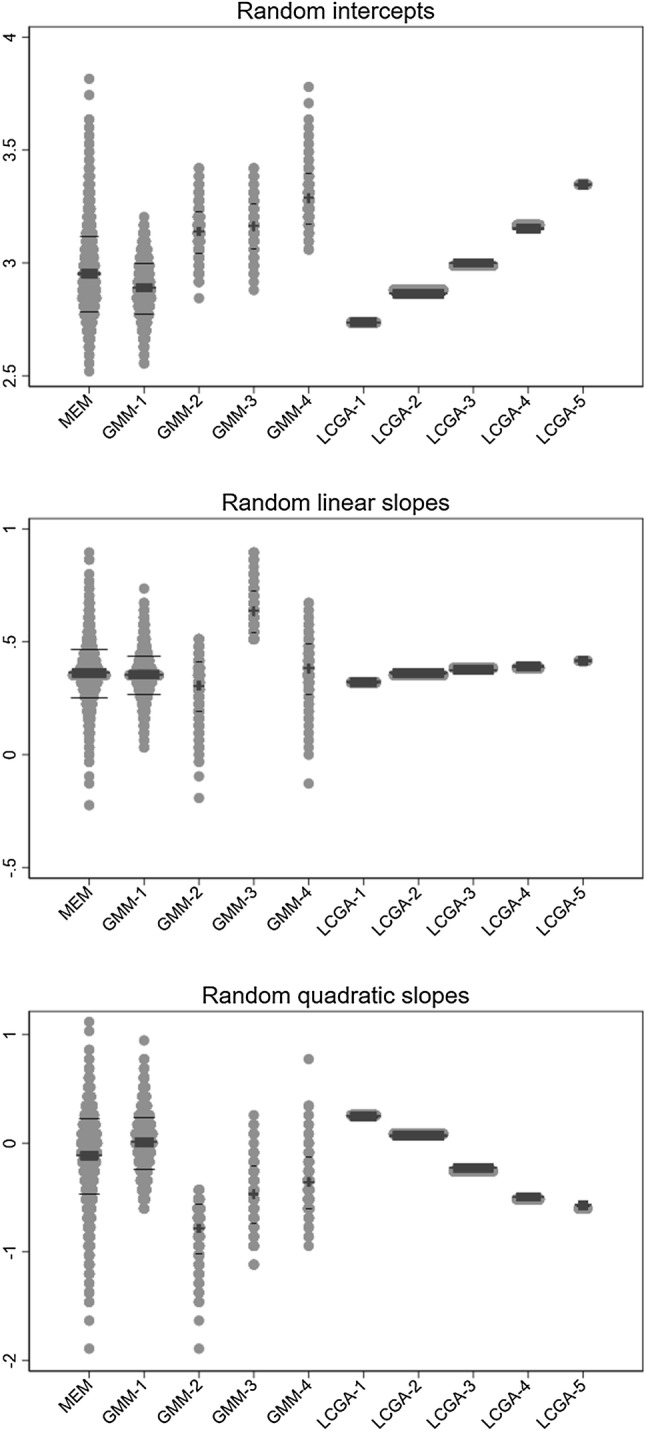
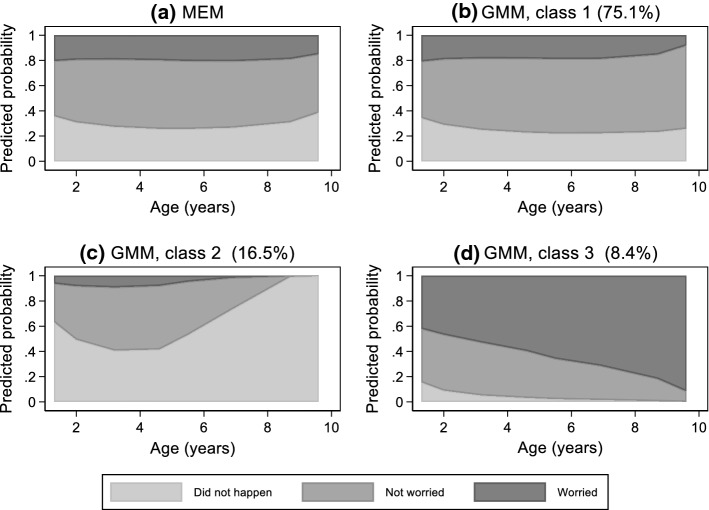
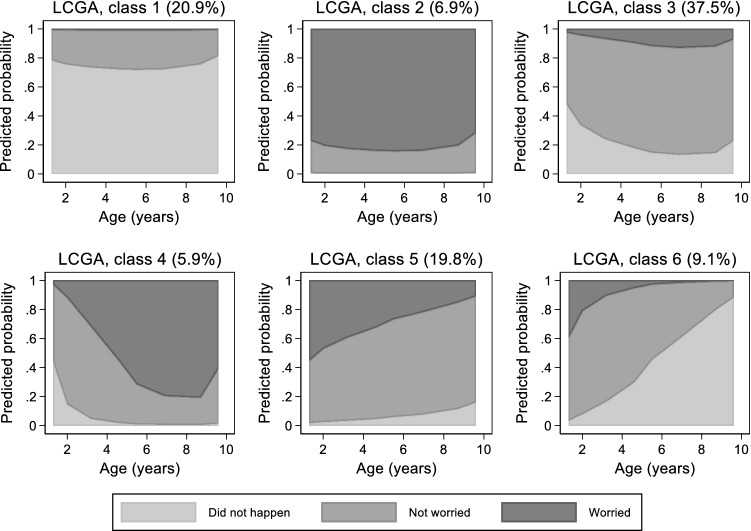
Individual-level longitudinal data on biological, behavioural, and social dimensions are becoming increasingly available. Typically, these data are analysed using mixed effects models, with the result summarised in terms of an average trajectory plus measures of the individual variations around this average. However, public health investigations would benefit from finer modelling of these individual variations which identify not just one average trajectory, but several typical trajectories. If evidence of heterogeneity in the development of these variables is found, the role played by temporally preceding (explanatory) variables as well as the potential impact of differential trajectories may have on later outcomes is often of interest. A wide choice of methods for uncovering typical trajectories and relating them to precursors and later outcomes exists. However, despite their increasing use, no practical overview of these methods targeted at epidemiological applications exists. Hence we provide: (a) a review of the three most commonly used methods for the identification of latent trajectories (growth mixture models, latent class growth analysis, and longitudinal latent class analysis); and (b) recommendations for the identification and interpretation of these trajectories and of their relationship with other variables. For illustration, we use longitudinal data on childhood body mass index and parental reports of fussy eating, collected in the Avon Longitudinal Study of Parents and Children.
个体层面的生物、行为和社会维度的纵向数据越来越多。通常,这些数据使用混合效应模型进行分析,结果以平均轨迹加上围绕该平均轨迹的个体变异的度量来表示。然而,公共卫生调查将受益于对这些个体变异进行更精细的建模,这些建模不仅可以识别一个平均轨迹,还可以识别几个典型轨迹。如果发现这些变量发展存在异质性的证据,那么先前(解释性)变量所起的作用以及不同轨迹对后期结果的潜在影响通常是人们感兴趣的。存在广泛的方法用于揭示典型轨迹,并将其与前驱变量和后期结果相关联。然而,尽管这些方法的使用越来越多,但针对流行病学应用的这些方法并没有实用的概述。因此,我们提供了:(a)对用于识别潜在轨迹的三种最常用方法(增长混合物模型、潜在类别增长分析和纵向潜在类别分析)的回顾;以及(b)用于识别和解释这些轨迹及其与其他变量的关系的建议。为了说明这一点,我们使用了在雅芳父母和孩子纵向研究中收集的儿童体重指数和父母报告的挑剔饮食的纵向数据。