Department of Anesthesiology, The University of Texas Medical Branch at Galveston, Galveston, Texas, United States of America.
Department of Biochemistry and Molecular Biology, The University of Texas Medical Branch at Galveston, Galveston, Texas, United States of America.
PLoS One. 2020 Jun 5;15(6):e0234185. doi: 10.1371/journal.pone.0234185. eCollection 2020.
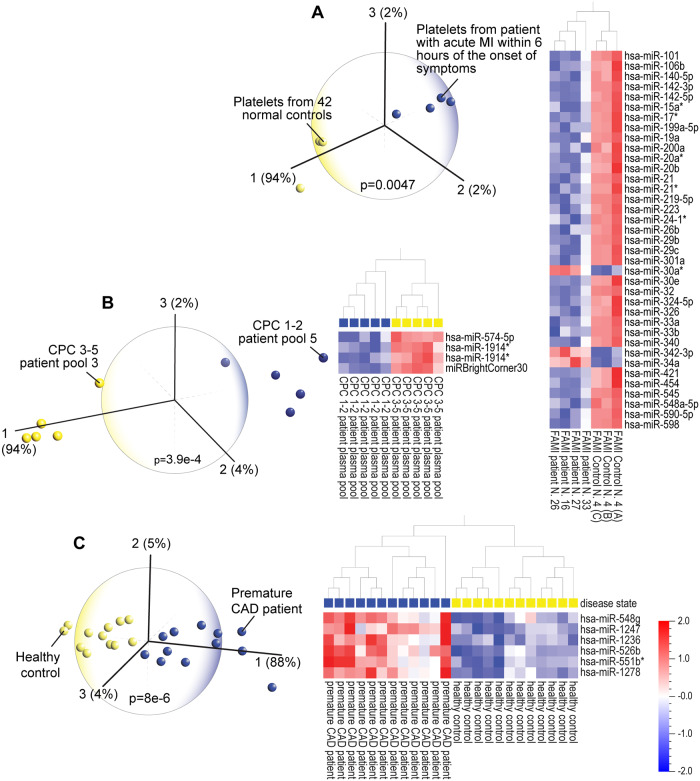
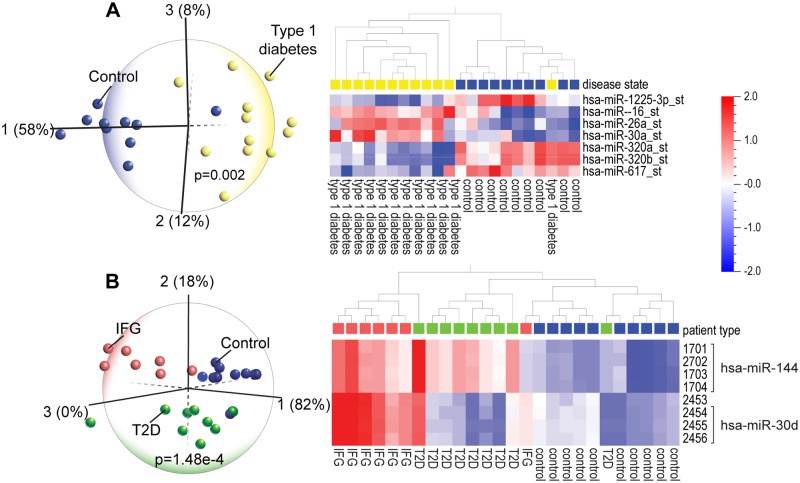
Early, ideally pre-symptomatic, recognition of common diseases (e.g., heart disease, cancer, diabetes, Alzheimer's disease) facilitates early treatment or lifestyle modifications, such as diet and exercise. Sensitive, specific identification of diseases using blood samples would facilitate early recognition. We explored the potential of disease identification in high dimensional blood microRNA (miRNA) datasets using a powerful data reduction method: principal component analysis (PCA). Using Qlucore Omics Explorer (QOE), a dynamic, interactive visualization-guided bioinformatics program with a built-in statistical platform, we analyzed publicly available blood miRNA datasets from the Gene Expression Omnibus (GEO) maintained at the National Center for Biotechnology Information at the National Institutes of Health (NIH). The miRNA expression profiles were generated from real time PCR arrays, microarrays or next generation sequencing of biologic materials (e.g., blood, serum or blood components such as platelets). PCA identified the top three principal components that distinguished cohorts of patients with specific diseases (e.g., heart disease, stroke, hypertension, sepsis, diabetes, specific types of cancer, HIV, hemophilia, subtypes of meningitis, multiple sclerosis, amyotrophic lateral sclerosis, Alzheimer's disease, mild cognitive impairment, aging, and autism), from healthy subjects. Literature searches verified the functional relevance of the discriminating miRNAs. Our goal is to assemble PCA and heatmap analyses of existing and future blood miRNA datasets into a clinical reference database to facilitate the diagnosis of diseases using routine blood draws.
早期,理想情况下是在出现症状之前,识别常见疾病(如心脏病、癌症、糖尿病、阿尔茨海默病)有助于早期治疗或生活方式改变,如饮食和运动。使用血液样本敏感、特异性地识别疾病将有助于早期识别。我们使用一种强大的数据降维方法:主成分分析(PCA),探索了在高维血液 microRNA(miRNA)数据集中识别疾病的潜力。我们使用 Qlucore Omics Explorer(QOE),这是一个具有内置统计平台的动态、交互式可视化引导的生物信息学程序,分析了美国国立卫生研究院(NIH)国家生物技术信息中心(NCBI)维护的基因表达综合数据库(GEO)中公开的血液 miRNA 数据集。miRNA 表达谱是通过实时 PCR 阵列、微阵列或下一代测序从生物材料(如血液、血清或血小板等血液成分)生成的。PCA 确定了区分特定疾病(如心脏病、中风、高血压、败血症、糖尿病、特定类型的癌症、HIV、血友病、脑膜炎亚型、多发性硬化症、肌萎缩侧索硬化症、阿尔茨海默病、轻度认知障碍、衰老和自闭症)患者队列的前三个主成分,以及健康受试者。文献检索验证了区分 miRNA 的功能相关性。我们的目标是将现有的和未来的血液 miRNA 数据集的 PCA 和热图分析组装成一个临床参考数据库,以便通过常规血液采集来诊断疾病。