Dudbridge Frank
Department of Health Sciences, University of Leicester, Leicester, UK.
Stat Methods Med Res. 2020 Dec;29(12):3492-3510. doi: 10.1177/0962280220929039. Epub 2020 Jun 29.
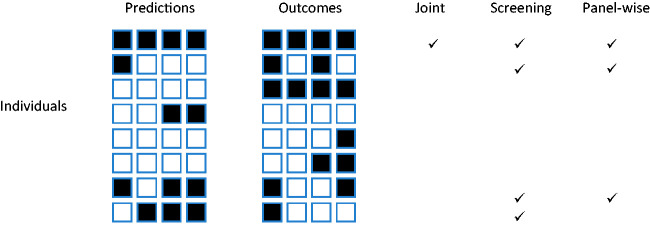
Risk prediction models have been developed in many contexts to classify individuals according to a single outcome, such as risk of a disease. Emerging "-omic" biomarkers provide panels of features that can simultaneously predict multiple outcomes from a single biological sample, creating issues of multiplicity reminiscent of exploratory hypothesis testing. Here I propose definitions of some basic criteria for evaluating prediction models of multiple outcomes. I define calibration in the multivariate setting and then distinguish between outcome-wise and individual-wise prediction, and within the latter between joint and panel-wise prediction. I give examples such as screening and early detection in which different senses of prediction may be more appropriate. In each case I propose definitions of sensitivity, specificity, concordance, positive and negative predictive value and relative utility. I link the definitions through a multivariate probit model, showing that the accuracy of a multivariate prediction model can be summarised by its covariance with a liability vector. I illustrate the concepts on a biomarker panel for early detection of eight cancers, and on polygenic risk scores for six common diseases.
风险预测模型已在许多情况下得到开发,用于根据单一结果对个体进行分类,例如疾病风险。新兴的“组学”生物标志物提供了一系列特征,这些特征可以从单个生物样本中同时预测多个结果,从而产生了类似于探索性假设检验中的多重性问题。在此,我提出了一些用于评估多结果预测模型的基本标准的定义。我定义了多变量环境下的校准,然后区分了按结果预测和按个体预测,并在后者中区分了联合预测和面板预测。我给出了一些例子,如筛查和早期检测,其中不同的预测意义可能更合适。在每种情况下,我都提出了灵敏度、特异性、一致性、阳性和阴性预测值以及相对效用的定义。我通过多变量概率模型将这些定义联系起来,表明多变量预测模型的准确性可以通过其与责任向量的协方差来概括。我在用于早期检测八种癌症的生物标志物面板以及六种常见疾病的多基因风险评分上说明了这些概念。