Fan Zhun, Li Chong, Chen Ying, Wei Jiahong, Loprencipe Giuseppe, Chen Xiaopeng, Di Mascio Paola
Key Lab of Digital Signal and Image Processing of Guangdong Province, Department of Electronic and information Engineering, College of Engineering, Shantou University, Shan'tou 515063, China.
Department of Civil, Constructional and Environmental Engineering, Sapienza University of Rome, 00184 Rome, Italy.
Materials (Basel). 2020 Jul 2;13(13):2960. doi: 10.3390/ma13132960.
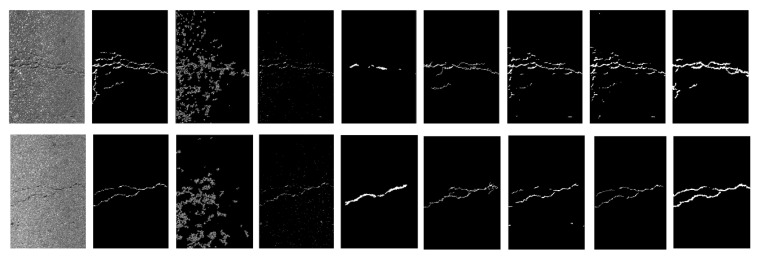
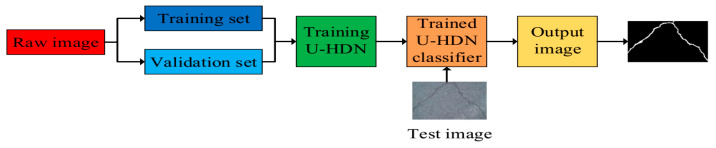
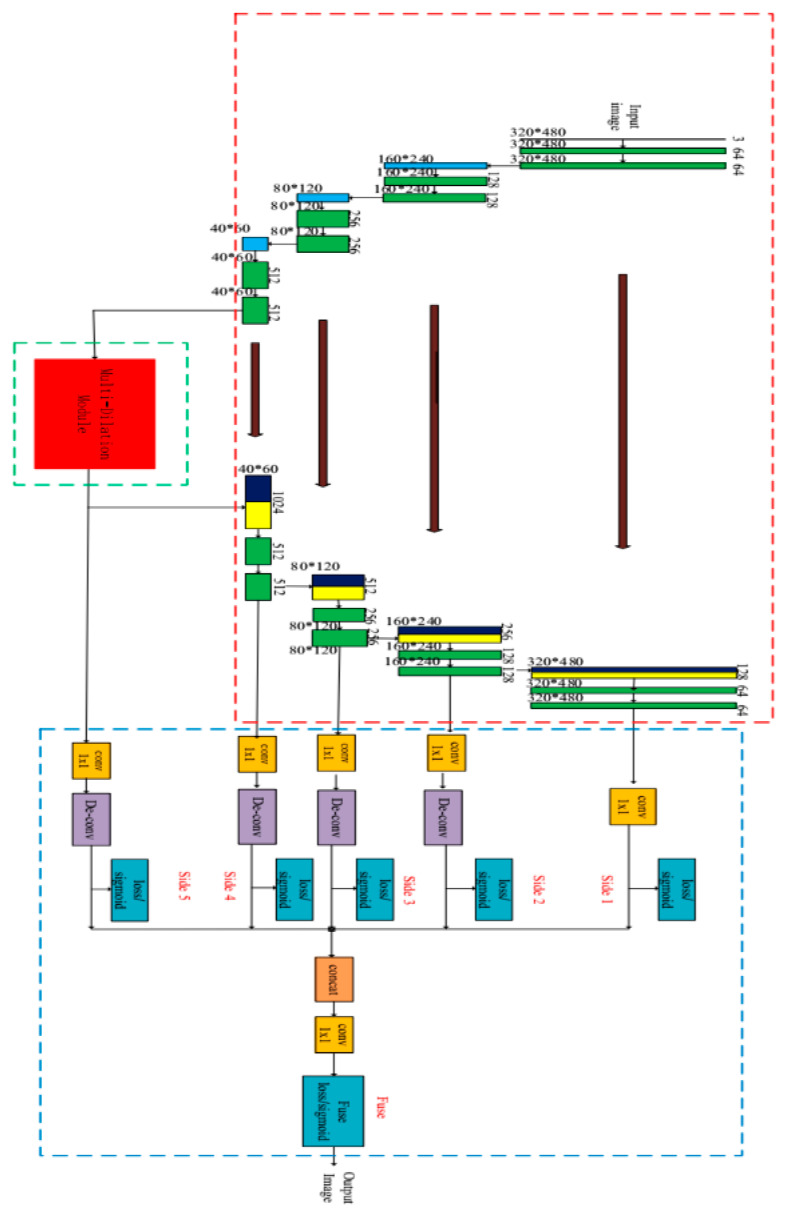
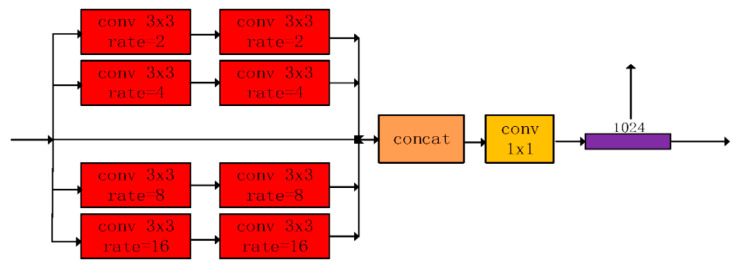
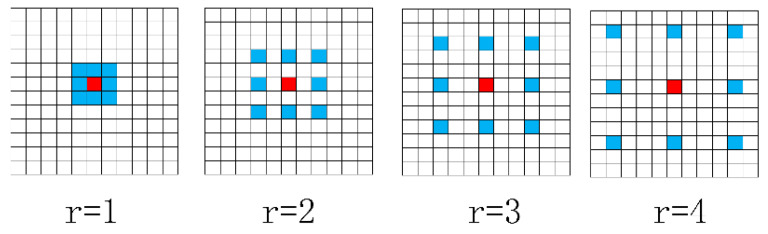
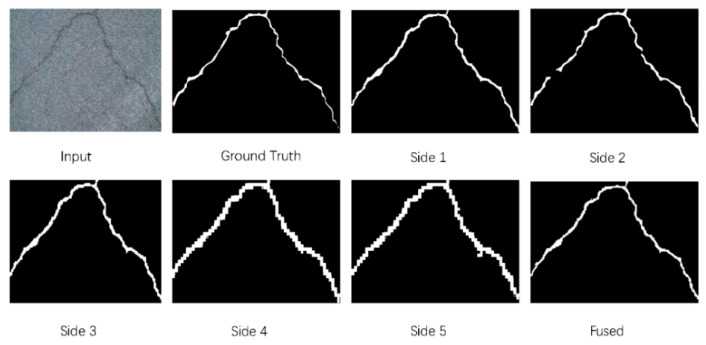
Automatic crack detection from images is an important task that is adopted to ensure road safety and durability for Portland cement concrete (PCC) and asphalt concrete (AC) pavement. Pavement failure depends on a number of causes including water intrusion, stress from heavy loads, and all the climate effects. Generally, cracks are the first distress that arises on road surfaces and proper monitoring and maintenance to prevent cracks from spreading or forming is important. Conventional algorithms to identify cracks on road pavements are extremely time-consuming and high cost. Many cracks show complicated topological structures, oil stains, poor continuity, and low contrast, which are difficult for defining crack features. Therefore, the automated crack detection algorithm is a key tool to improve the results. Inspired by the development of deep learning in computer vision and object detection, the proposed algorithm considers an encoder-decoder architecture with hierarchical feature learning and dilated convolution, named U-Hierarchical Dilated Network (U-HDN), to perform crack detection in an end-to-end method. Crack characteristics with multiple context information are automatically able to learn and perform end-to-end crack detection. Then, a multi-dilation module embedded in an encoder-decoder architecture is proposed. The crack features of multiple context sizes can be integrated into the multi-dilation module by dilation convolution with different dilatation rates, which can obtain much more cracks information. Finally, the hierarchical feature learning module is designed to obtain a multi-scale features from the high to low- level convolutional layers, which are integrated to predict pixel-wise crack detection. Some experiments on public crack databases using 118 images were performed and the results were compared with those obtained with other methods on the same images. The results show that the proposed U-HDN method achieves high performance because it can extract and fuse different context sizes and different levels of feature maps than other algorithms.
从图像中自动检测裂缝是一项重要任务,用于确保波特兰水泥混凝土(PCC)和沥青混凝土(AC)路面的道路安全和耐久性。路面损坏取决于多种原因,包括水侵入、重载应力以及所有气候影响。一般来说,裂缝是路面出现的首要病害,对其进行适当监测和维护以防止裂缝扩展或形成非常重要。传统的路面裂缝识别算法极其耗时且成本高昂。许多裂缝呈现出复杂的拓扑结构、油污、连续性差和对比度低等特点,难以定义裂缝特征。因此,自动裂缝检测算法是提高检测结果的关键工具。受计算机视觉和目标检测中深度学习发展的启发,所提出的算法考虑了一种具有分层特征学习和空洞卷积的编码器 - 解码器架构,名为U - 分层空洞网络(U - HDN),以端到端的方式进行裂缝检测。能够自动学习具有多上下文信息的裂缝特征并执行端到端的裂缝检测。然后,提出了一种嵌入在编码器 - 解码器架构中的多空洞模块。通过不同扩张率的空洞卷积,可以将多种上下文大小的裂缝特征集成到多空洞模块中,从而获得更多的裂缝信息。最后,设计了分层特征学习模块,从高到低层次的卷积层获取多尺度特征,并将其集成以预测逐像素的裂缝检测。使用118张图像在公共裂缝数据库上进行了一些实验,并将结果与在相同图像上使用其他方法获得的结果进行了比较。结果表明,所提出的U - HDN方法具有高性能,因为它比其他算法能够提取和融合不同上下文大小和不同层次的特征图。