Department of Bioinformatics, College of Life Sciences, Zhejiang University, Hangzhou, China.
School of Medicine, Zhejiang University, Hangzhou, Zhejiang, China.
PLoS Comput Biol. 2020 Jul 20;16(7):e1007760. doi: 10.1371/journal.pcbi.1007760. eCollection 2020 Jul.
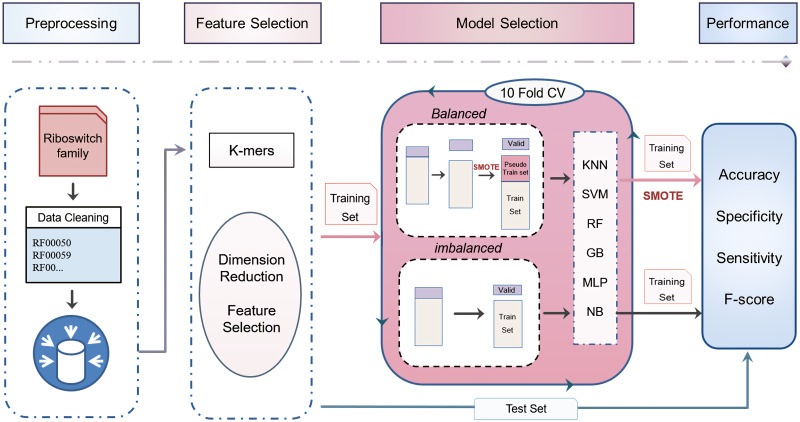
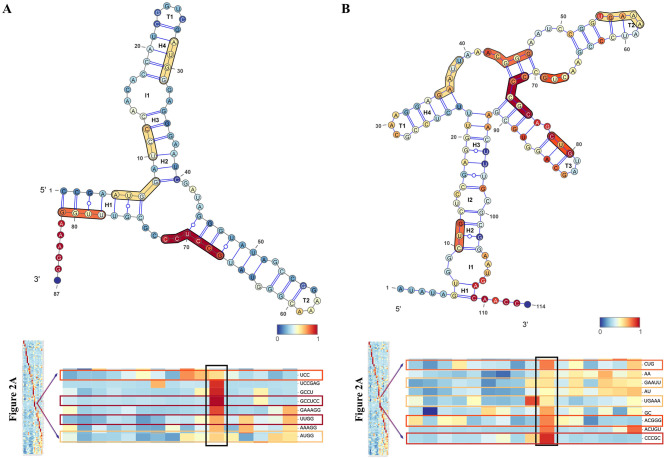
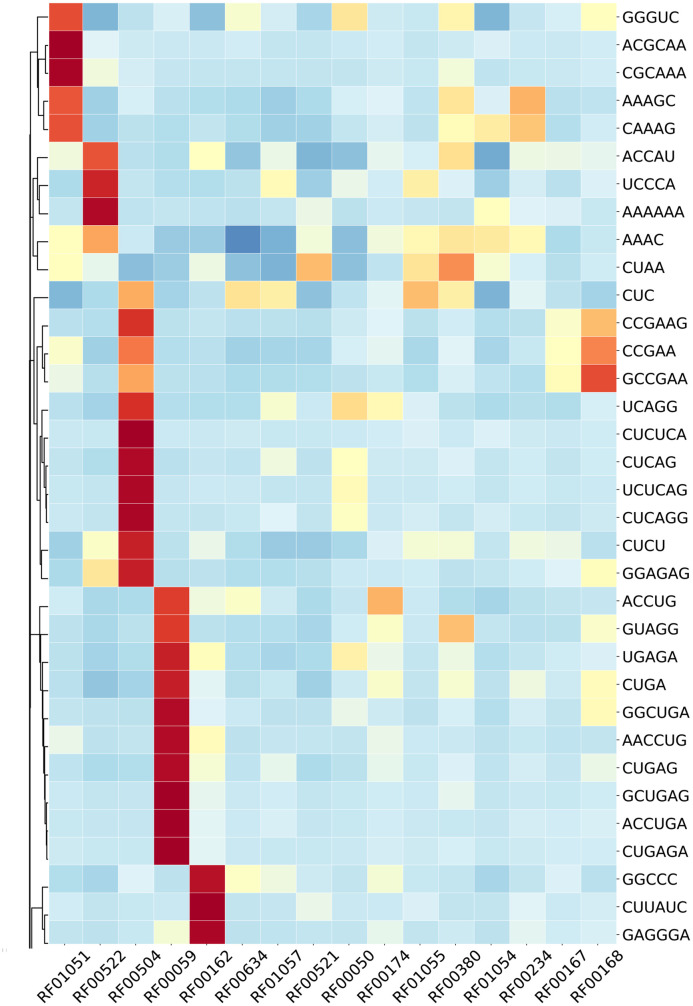
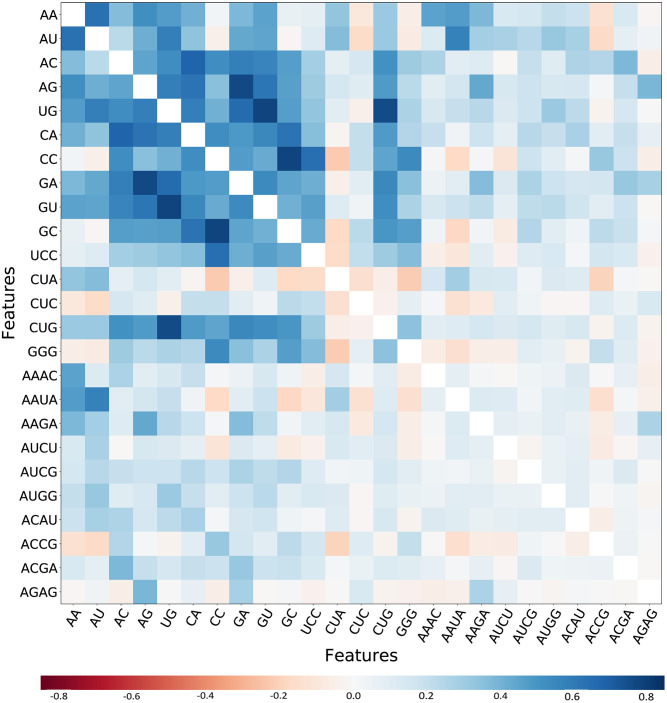
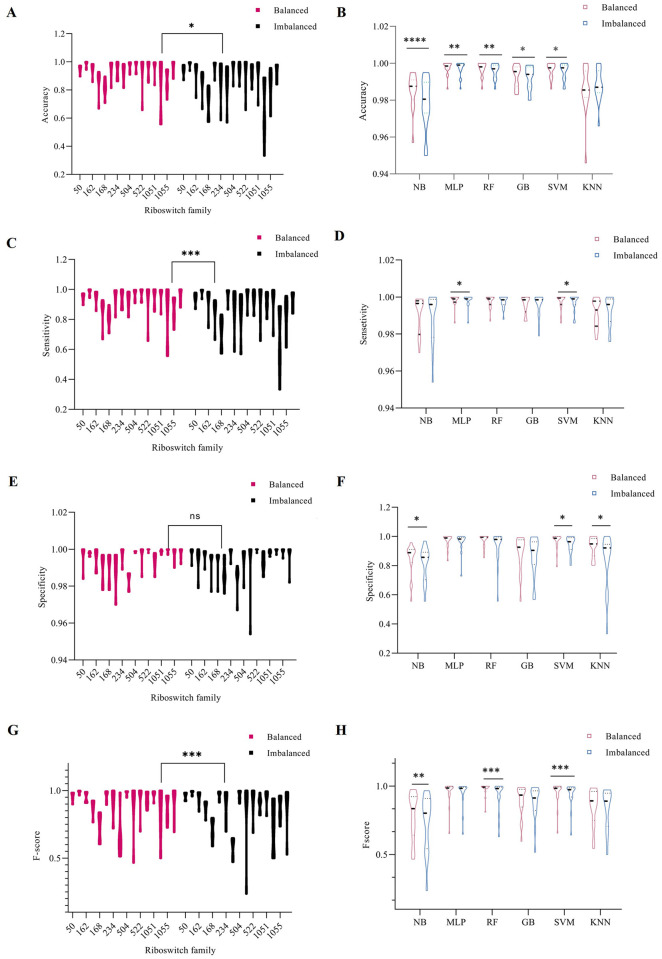
Riboswitch, a part of regulatory mRNA (50-250nt in length), has two main classes: aptamer and expression platform. One of the main challenges raised during the classification of riboswitch is imbalanced data. That is a circumstance in which the records of a sequences of one group are very small compared to the others. Such circumstances lead classifier to ignore minority group and emphasize on majority ones, which results in a skewed classification. We considered sixteen riboswitch families, to be in accord with recent riboswitch classification work, that contain imbalanced sequences. The sequences were split into training and test set using a newly developed pipeline. From 5460 k-mers (k value 1 to 6) produced, 156 features were calculated based on CfsSubsetEval and BestFirst function found in WEKA 3.8. Statistically tested result was significantly difference between balanced and imbalanced sequences (p < 0.05). Besides, each algorithm also showed a significant difference in sensitivity, specificity, accuracy, and macro F-score when used in both groups (p < 0.05). Several k-mers clustered from heat map were discovered to have biological functions and motifs at the different positions like interior loops, terminal loops and helices. They were validated to have a biological function and some are riboswitch motifs. The analysis has discovered the importance of solving the challenges of majority bias analysis and overfitting. Presented results were generalized evaluation of both balanced and imbalanced models, which implies their ability of classifying, to classify novel riboswitches. The Python source code is available at https://github.com/Seasonsling/riboswitch.
核糖开关是调节 mRNA(50-250nt 长)的一部分,主要有两个类别:适体和表达平台。在核糖开关分类过程中面临的主要挑战之一是数据不平衡。这种情况是指与其他组相比,一个组的序列记录非常小。这种情况会导致分类器忽略少数群体并强调多数群体,从而导致分类倾斜。我们考虑了十六个核糖开关家族,这些家族与最近的核糖开关分类工作一致,包含不平衡的序列。使用新开发的管道将序列分为训练集和测试集。从生成的 5460 个 k-mer(k 值为 1 到 6)中,根据 WEKA 3.8 中的 CfsSubsetEval 和 BestFirst 函数计算了 156 个特征。经过统计检验,平衡和不平衡序列之间的结果有显著差异(p<0.05)。此外,当在这两组中使用时,每种算法在敏感性、特异性、准确性和宏 F 分数方面也显示出显著差异(p<0.05)。从热图聚类的几个 k-mer 被发现具有不同位置的生物学功能和基序,如内部环、末端环和螺旋。它们被验证具有生物学功能,有些是核糖开关基序。该分析发现了解决多数偏见分析和过拟合挑战的重要性。所呈现的结果是对平衡和不平衡模型的综合评估,这意味着它们具有分类的能力,可以对新型核糖开关进行分类。Python 源代码可在 https://github.com/Seasonsling/riboswitch 上获得。