Division of Drug Discovery & Safety, Leiden Academic Centre for Drug Research, Leiden University, Einsteinweg 55, 2333 CC, Leiden, The Netherlands.
Janssen Research & Development, Turnhoutseweg 30, 2340 Beerse, Belgium.
J Chem Inf Model. 2020 Oct 26;60(10):4664-4672. doi: 10.1021/acs.jcim.0c00695. Epub 2020 Oct 5.
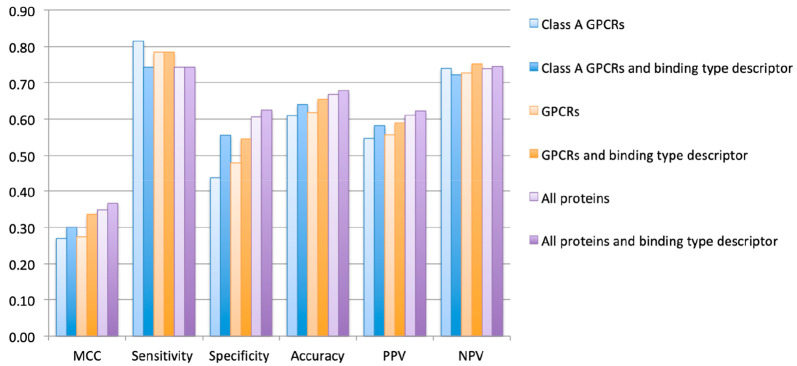
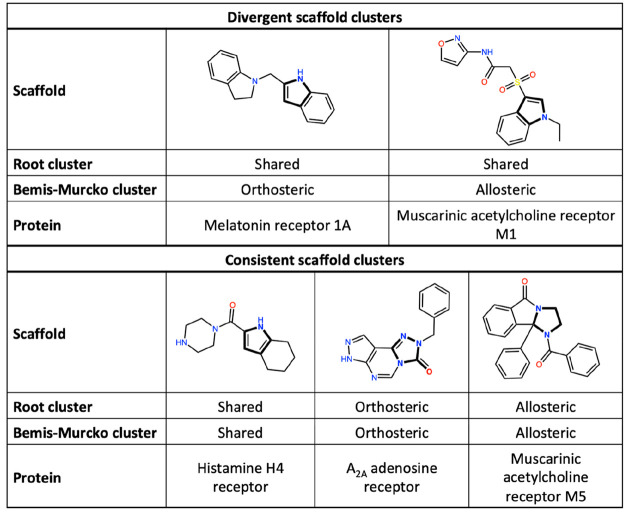
Proteins often have both orthosteric and allosteric binding sites. Endogenous ligands, such as hormones and neurotransmitters, bind to the orthosteric site, while synthetic ligands may bind to orthosteric or allosteric sites, which has become a focal point in drug discovery. Usually, such allosteric modulators bind to a protein noncompetitively with its endogenous ligand or substrate. The growing interest in allosteric modulators has resulted in a substantial increase of these entities and their features such as binding data in chemical libraries and databases. Although this data surge fuels research focused on allosteric modulators, binding data is unfortunately not always clearly indicated as being allosteric or orthosteric. Therefore, allosteric binding data is difficult to retrieve from databases that contain a mixture of allosteric and orthosteric compounds. This decreases model performance when statistical methods, such as machine learning models, are applied. In previous work we generated an allosteric data subset of ChEMBL release 14. In the current study an improved text mining approach is used to retrieve the allosteric and orthosteric binding types from the literature in ChEMBL release 22. Moreover, convolutional deep neural networks were constructed to predict the binding types of compounds for class A G protein-coupled receptors (GPCRs). Temporal split validation showed the model predictiveness with Matthews correlation coefficient (MCC) = 0.54, sensitivity allosteric = 0.54, and sensitivity orthosteric = 0.94. Finally, this study shows that the inclusion of accurate binding types increases binding predictions by including them as descriptor (MCC = 0.27 improved to MCC = 0.34; validated for class A GPCRs, trained on all GPCRs). Although the focus of this study is mainly on class A GPCRs, binding types for all protein classes in ChEMBL were obtained and explored. The data set is included as a supplement to this study, allowing the reader to select the compounds and binding types of interest.
蛋白质通常具有正位和变构结合位点。内源性配体,如激素和神经递质,与正位位点结合,而合成配体可能与正位或变构位点结合,这已成为药物发现的焦点。通常,这种变构调节剂与内源性配体或底物非竞争性地结合到蛋白质上。对变构调节剂的日益关注导致这些实体及其特征(如化学库和数据库中的结合数据)的数量显著增加。尽管这些数据的激增推动了变构调节剂的研究,但遗憾的是,绑定数据并不总是明确表示为变构或正位。因此,变构结合数据很难从包含变构和正位化合物混合物的数据库中检索。当应用统计方法(如机器学习模型)时,这会降低模型性能。在之前的工作中,我们生成了 ChEMBL 版本 14 的变构数据集。在当前的研究中,使用改进的文本挖掘方法从 ChEMBL 版本 22 的文献中检索变构和正位结合类型。此外,构建了卷积深度神经网络来预测 A 类 G 蛋白偶联受体 (GPCR) 的化合物结合类型。时间分割验证显示模型的预测能力,马修斯相关系数 (MCC) = 0.54,变构灵敏度 = 0.54,正位灵敏度 = 0.94。最后,这项研究表明,通过将准确的结合类型包含在描述符中,可以提高结合预测(MCC 从 0.27 提高到 0.34;对 A 类 GPCR 进行验证,在所有 GPCR 上进行训练)。虽然本研究的重点主要是 A 类 GPCR,但获得并探索了 ChEMBL 中所有蛋白质类别的结合类型。该数据集作为本研究的补充包含在内,允许读者选择感兴趣的化合物和结合类型。