Liu Bingchun, Guo Xiaoling, Lai Mingzhao, Wang Qingshan
School of Management, Tianjin University of Technology, Tianjin 300384, China.
School of Humanities, Tianjin Agricultural University, Tianjin 300384, China.
Comput Intell Neurosci. 2020 Sep 30;2020:8834699. doi: 10.1155/2020/8834699. eCollection 2020.
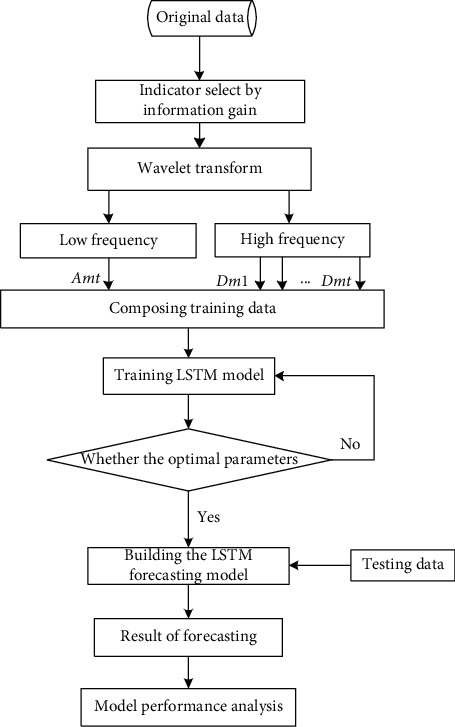
Air pollutant concentration forecasting is an effective way which protects health of the public by the warning of the harmful air contaminants. In this study, a hybrid prediction model has been established by using information gain, wavelet decomposition transform technique, and LSTM neural network, and applied to the daily concentration prediction of atmospheric pollutants (PM, PM, SO, NO, O, and CO) in Beijing. First, the collected raw data are selected by feature selection by information gain, and a set of factors having a strong correlation with the prediction is obtained. Then, the historical time series of the daily air pollutant concentration is decomposed into different frequencies by using a wavelet decomposition transform and recombined into a high-dimensional training data set. Finally, the LSTM prediction model is trained with high-dimensional data sets, and the parameters are adjusted by repeated tests to obtain the optimal prediction model. The data used in this study were derived from six air pollution concentration data in Beijing from 1/1/2014 to 31/12/2016, and the atmospheric pollutant concentration data of Beijing between 1/1/2017 and 31/12/2017 were used to test the predictive ability of the data set test model. The results show that the evaluation index MAPE of the model prediction is 7.45%. Therefore, the hybrid prediction model has a higher value of application for atmospheric pollutant concentration prediction, because this model has higher prediction accuracy and stability for future air pollutant concentration prediction.
空气污染物浓度预测是一种通过对有害空气污染物进行预警来保护公众健康的有效方式。在本研究中,利用信息增益、小波分解变换技术和长短期记忆(LSTM)神经网络建立了一种混合预测模型,并将其应用于北京大气污染物(PM、PM、SO、NO、O和CO)的日浓度预测。首先,通过信息增益进行特征选择,从收集到的原始数据中筛选出与预测具有强相关性的一组因素。然后,利用小波分解变换将每日空气污染物浓度的历史时间序列分解为不同频率,并重新组合成一个高维训练数据集。最后,用高维数据集训练LSTM预测模型,并通过反复试验调整参数,以获得最优预测模型。本研究使用的数据来源于2014年1月1日至2016年12月31日北京的六个空气污染浓度数据,并使用2017年1月1日至2017年12月31日北京的大气污染物浓度数据来测试数据集测试模型的预测能力。结果表明,该模型预测的评估指标平均绝对百分比误差(MAPE)为7.45%。因此,该混合预测模型在大气污染物浓度预测方面具有较高的应用价值,因为该模型对未来空气污染物浓度预测具有较高的预测精度和稳定性。