Faculty of Social Sciences and Humanities, Digital Humanities Ariel Lab, Ariel University, Ariel, Israel.
School of Computer Sciences, Tel Aviv University, Tel Aviv, Israel.
PLoS One. 2020 Oct 28;15(10):e0240511. doi: 10.1371/journal.pone.0240511. eCollection 2020.
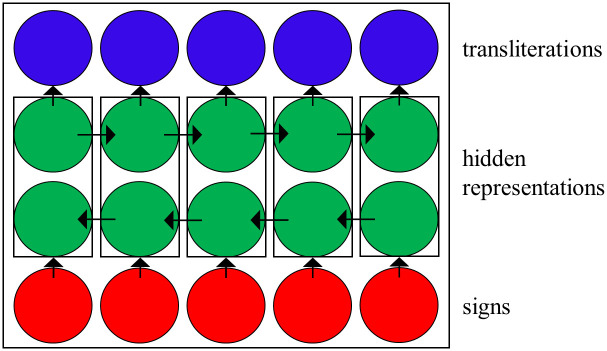
In this paper we present a new method for automatic transliteration and segmentation of Unicode cuneiform glyphs using Natural Language Processing (NLP) techniques. Cuneiform is one of the earliest known writing system in the world, which documents millennia of human civilizations in the ancient Near East. Hundreds of thousands of cuneiform texts were found in the nineteenth and twentieth centuries CE, most of which are written in Akkadian. However, there are still tens of thousands of texts to be published. We use models based on machine learning algorithms such as recurrent neural networks (RNN) with an accuracy reaching up to 97% for automatically transliterating and segmenting standard Unicode cuneiform glyphs into words. Therefore, our method and results form a major step towards creating a human-machine interface for creating digitized editions. Our code, Akkademia, is made publicly available for use via a web application, a python package, and a github repository.
本文提出了一种新的方法,利用自然语言处理 (NLP) 技术自动音译和分割 Unicode 楔形文字。楔形文字是世界上已知最早的书写系统之一,记录了古代近东地区几千年的人类文明。在 19 世纪和 20 世纪,人们发现了数十万份楔形文字文本,其中大部分用阿卡德语书写。然而,仍有数万份文本有待出版。我们使用基于机器学习算法的模型,例如具有循环神经网络 (RNN) 的模型,其自动音译和分割标准 Unicode 楔形文字的准确率高达 97%,从而将标准 Unicode 楔形文字音译和分割成单词。因此,我们的方法和结果是朝着为创建数字化版本创建人机界面迈出的重要一步。我们的代码 Akkademia 通过一个网络应用程序、一个 Python 包和一个 GitHub 存储库公开提供使用。