Computer Engineering Department, Boğaziçi University, Istanbul, Turkey.
PLoS One. 2020 Dec 30;15(12):e0244179. doi: 10.1371/journal.pone.0244179. eCollection 2020.
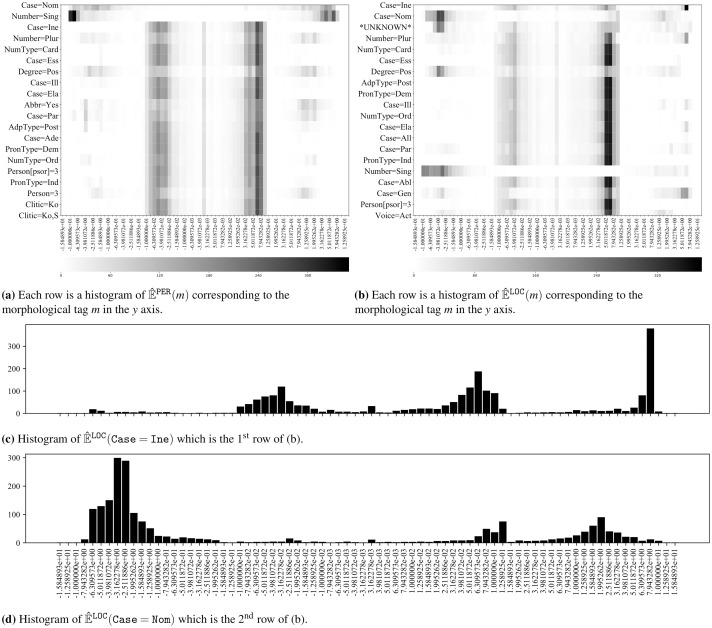
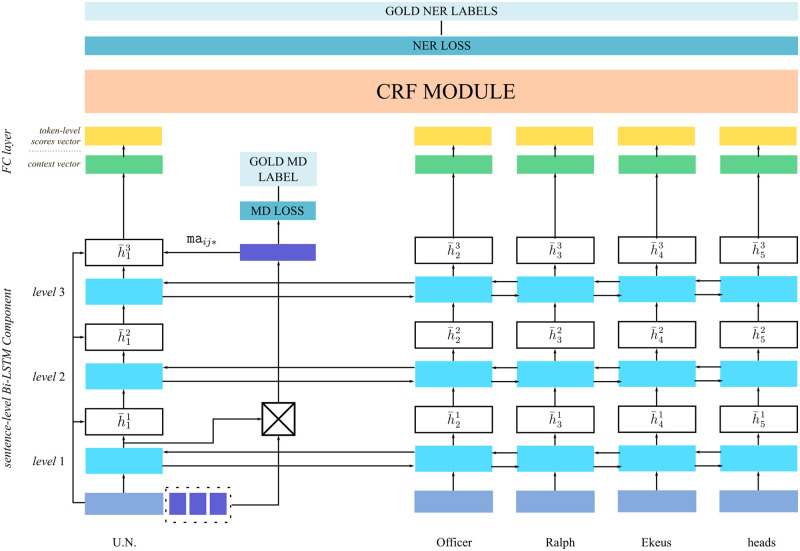
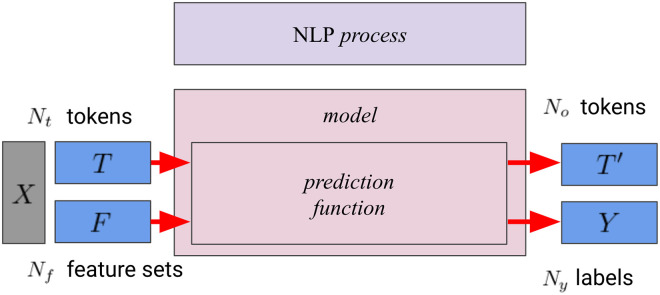
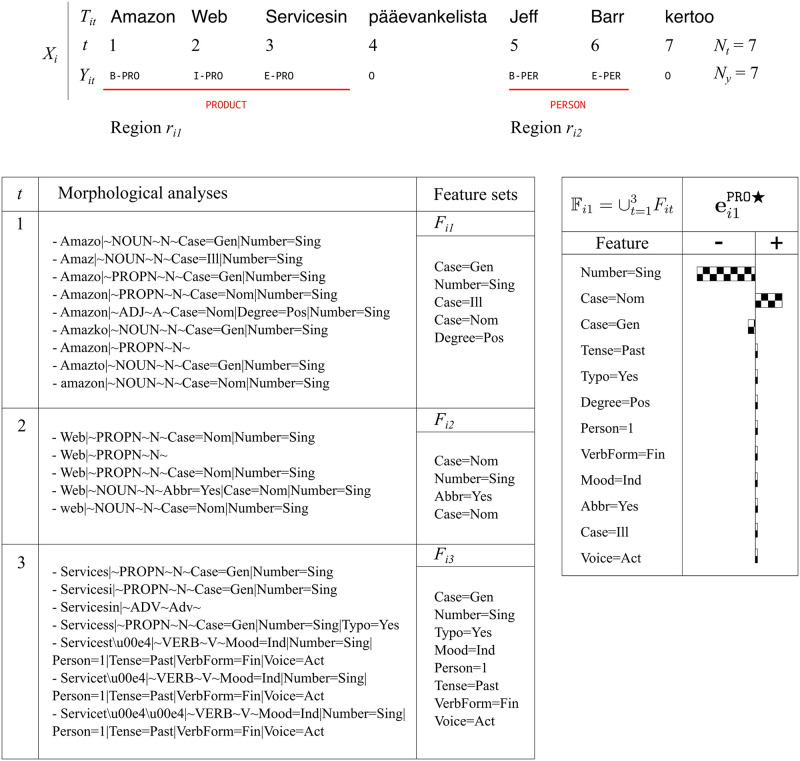
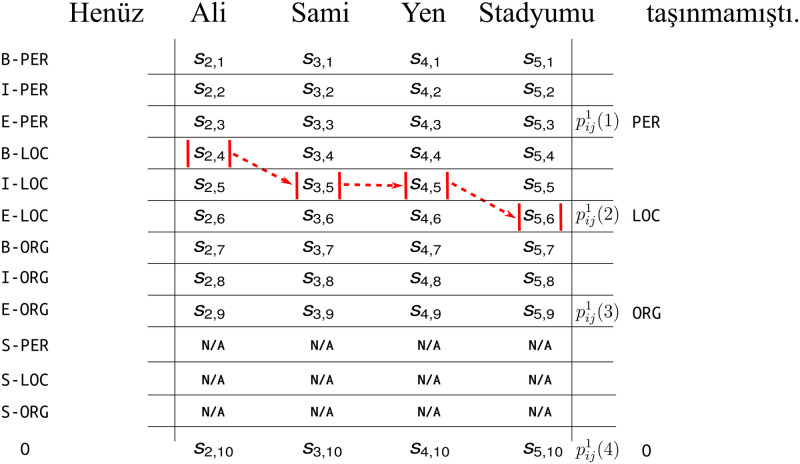
The state-of-the-art systems for most natural language engineering tasks employ machine learning methods. Despite the improved performances of these systems, there is a lack of established methods for assessing the quality of their predictions. This work introduces a method for explaining the predictions of any sequence-based natural language processing (NLP) task implemented with any model, neural or non-neural. Our method named EXSEQREG introduces the concept of region that links the prediction and features that are potentially important for the model. A region is a list of positions in the input sentence associated with a single prediction. Many NLP tasks are compatible with the proposed explanation method as regions can be formed according to the nature of the task. The method models the prediction probability differences that are induced by careful removal of features used by the model. The output of the method is a list of importance values. Each value signifies the impact of the corresponding feature on the prediction. The proposed method is demonstrated with a neural network based named entity recognition (NER) tagger using Turkish and Finnish datasets. A qualitative analysis of the explanations is presented. The results are validated with a procedure based on the mutual information score of each feature. We show that this method produces reasonable explanations and may be used for i) assessing the degree of the contribution of features regarding a specific prediction of the model, ii) exploring the features that played a significant role for a trained model when analyzed across the corpus.
用于大多数自然语言工程任务的最先进系统采用机器学习方法。尽管这些系统的性能有所提高,但缺乏评估其预测质量的既定方法。这项工作介绍了一种用于解释任何基于序列的自然语言处理 (NLP) 任务的预测的方法,该方法可以使用任何模型(神经或非神经)来实现。我们的方法名为 EXSEQREG,它引入了与潜在对模型重要的特征相关联的预测的区域的概念。区域是与单个预测相关联的输入句子中位置的列表。许多 NLP 任务都与所提出的解释方法兼容,因为可以根据任务的性质形成区域。该方法对由模型使用的特征的仔细去除引起的预测概率差异进行建模。该方法的输出是重要值的列表。每个值表示相应特征对预测的影响。该方法使用基于神经网络的命名实体识别 (NER) 标记器和土耳其语及芬兰语数据集进行了演示。提出了一种定性分析解释的方法。结果通过基于每个特征的互信息得分的过程进行验证。我们表明,该方法产生了合理的解释,可用于:i)评估特征对于模型的特定预测的贡献程度,ii)探索在分析语料库时对经过训练的模型起重要作用的特征。