Key Laboratory of Network Oriented Intelligent Computation, Harbin Institute of Technology Shenzhen Graduate School, Shenzhen, 518055, China.
Pharmacy Department, Shenzhen Second People's Hospital, First Affiliated Hospital of Shenzhen University, Shenzhen, 518035, China.
BMC Med Inform Decis Mak. 2017 Jul 5;17(Suppl 2):67. doi: 10.1186/s12911-017-0468-7.
Entity recognition is one of the most primary steps for text analysis and has long attracted considerable attention from researchers. In the clinical domain, various types of entities, such as clinical entities and protected health information (PHI), widely exist in clinical texts. Recognizing these entities has become a hot topic in clinical natural language processing (NLP), and a large number of traditional machine learning methods, such as support vector machine and conditional random field, have been deployed to recognize entities from clinical texts in the past few years. In recent years, recurrent neural network (RNN), one of deep learning methods that has shown great potential on many problems including named entity recognition, also has been gradually used for entity recognition from clinical texts.
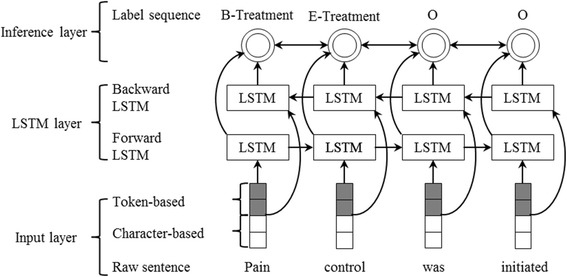
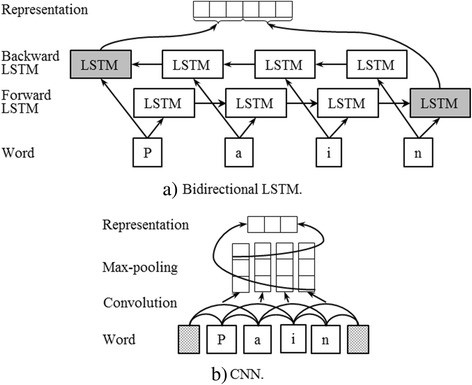
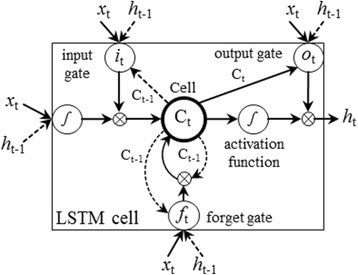
In this paper, we comprehensively investigate the performance of LSTM (long-short term memory), a representative variant of RNN, on clinical entity recognition and protected health information recognition. The LSTM model consists of three layers: input layer - generates representation of each word of a sentence; LSTM layer - outputs another word representation sequence that captures the context information of each word in this sentence; Inference layer - makes tagging decisions according to the output of LSTM layer, that is, outputting a label sequence.
Experiments conducted on corpora of the 2010, 2012 and 2014 i2b2 NLP challenges show that LSTM achieves highest micro-average F1-scores of 85.81% on the 2010 i2b2 medical concept extraction, 92.29% on the 2012 i2b2 clinical event detection, and 94.37% on the 2014 i2b2 de-identification, which is considerably competitive with other state-of-the-art systems.
LSTM that requires no hand-crafted feature has great potential on entity recognition from clinical texts. It outperforms traditional machine learning methods that suffer from fussy feature engineering. A possible future direction is how to integrate knowledge bases widely existing in the clinical domain into LSTM, which is a case of our future work. Moreover, how to use LSTM to recognize entities in specific formats is also another possible future direction.
实体识别是文本分析中最基本的步骤之一,长期以来一直受到研究人员的关注。在临床领域,各种类型的实体,如临床实体和受保护的健康信息(PHI),广泛存在于临床文本中。识别这些实体已成为临床自然语言处理(NLP)中的一个热门话题,近年来,已经有许多传统的机器学习方法,如支持向量机和条件随机场,被用于从临床文本中识别实体。近年来,深度学习方法中的一种——递归神经网络(RNN),在命名实体识别等问题上表现出了巨大的潜力,也逐渐被用于从临床文本中识别实体。
在本文中,我们全面研究了 LSTM(长短时记忆)作为 RNN 的一个代表变体在临床实体识别和保护健康信息识别方面的性能。LSTM 模型由三个层组成:输入层-生成句子中每个单词的表示;LSTM 层-输出另一个单词表示序列,捕获该句子中每个单词的上下文信息;推断层-根据 LSTM 层的输出做出标记决策,即输出标签序列。
在 2010、2012 和 2014 年 i2b2 NLP 挑战赛的语料库上进行的实验表明,LSTM 在 2010 年 i2b2 医学概念提取中获得了 85.81%的微平均 F1 分数,在 2012 年 i2b2 临床事件检测中获得了 92.29%的微平均 F1 分数,在 2014 年 i2b2 去识别中获得了 94.37%的微平均 F1 分数,这与其他最先进的系统相当具有竞争力。
不需要手工制作特征的 LSTM 在从临床文本中识别实体方面具有很大的潜力。它优于传统的机器学习方法,这些方法在特征工程方面存在繁琐的问题。一个可能的未来方向是如何将临床领域广泛存在的知识库集成到 LSTM 中,这是我们未来工作的一个方面。此外,如何使用 LSTM 识别特定格式的实体也是另一个可能的未来方向。