Al-Jefri Majed, Evans Roger, Lee Joon, Ghezzi Pietro
Department of Medicine, Cumming School of Medicine, University of Calgary, Calgary, AB, Canada.
Data Intelligence for Health Lab, Cumming School of Medicine, University of Calgary, Calgary, AB, Canada.
Front Public Health. 2020 Dec 18;8:515347. doi: 10.3389/fpubh.2020.515347. eCollection 2020.
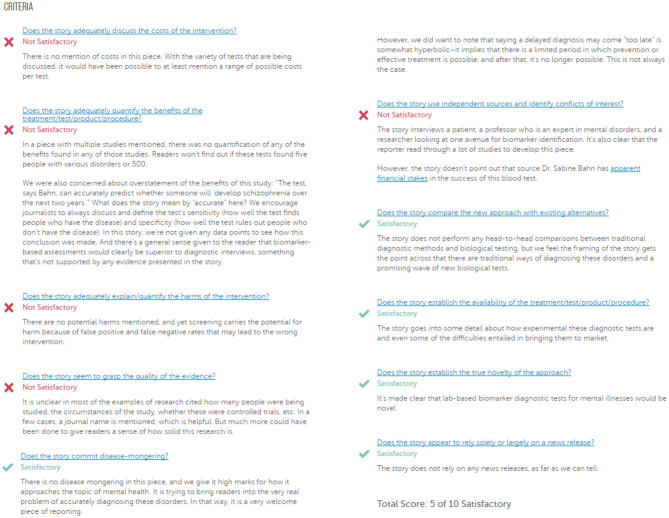
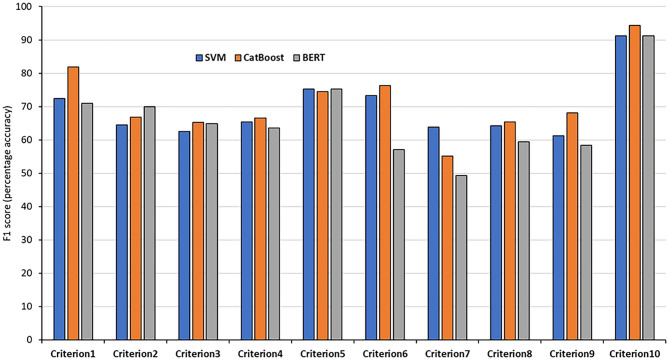
Many online and printed media publish health news of questionable trustworthiness and it may be difficult for laypersons to determine the information quality of such articles. The purpose of this work was to propose a methodology for the automatic assessment of the quality of health-related news stories using natural language processing and machine learning. We used a database from the website HealthNewsReview.org that aims to improve the public dialogue about health care. HealthNewsReview.org developed a set of criteria to critically analyze health care interventions' claims. In this work, we attempt to automate the evaluation process by identifying the indicators of those criteria using natural language processing-based machine learning on a corpus of more than 1,300 news stories. We explored features ranging from simple n-grams to more advanced linguistic features and optimized the feature selection for each task. Additionally, we experimented with the use of pre-trained natural language model BERT. For some criteria, such as mention of costs, benefits, harms, and "disease-mongering," the evaluation results were promising with an F measure reaching 81.94%, while for others the results were less satisfactory due to the dataset size, the need of external knowledge, or the subjectivity in the evaluation process. These used criteria are more challenging than those addressed by previous work, and our aim was to investigate how much more difficult the machine learning task was, and how and why it varied between criteria. For some criteria, the obtained results were promising; however, automated evaluation of the other criteria may not yet replace the manual evaluation process where human experts interpret text senses and make use of external knowledge in their assessment.
许多在线和印刷媒体都发布可信度存疑的健康新闻,外行人可能很难判断此类文章的信息质量。这项工作的目的是提出一种使用自然语言处理和机器学习自动评估健康相关新闻报道质量的方法。我们使用了来自HealthNewsReview.org网站的一个数据库,该网站旨在改善关于医疗保健的公众对话。HealthNewsReview.org制定了一套标准来批判性地分析医疗保健干预措施的声明。在这项工作中,我们试图通过在1300多篇新闻报道的语料库上使用基于自然语言处理的机器学习来识别这些标准的指标,从而使评估过程自动化。我们探索了从简单的n元语法到更高级的语言特征等各种特征,并针对每个任务优化了特征选择。此外,我们还试验了使用预训练的自然语言模型BERT。对于一些标准,如对成本、收益、危害和“疾病兜售”的提及,评估结果很有前景,F值达到81.94%,而对于其他标准,由于数据集大小、外部知识需求或评估过程中的主观性,结果不太令人满意。这些使用的标准比以前工作涉及的标准更具挑战性,我们的目的是研究机器学习任务有多困难,以及它在不同标准之间如何以及为何有所不同。对于一些标准,获得的结果很有前景;然而,对其他标准的自动评估可能还无法取代人工评估过程,在人工评估过程中,人类专家会解读文本含义并在评估中利用外部知识。