Dawkins Bryan A, Le Trang T, McKinney Brett A
Genes and Human Disease, Oklahoma Medical Research Foundation, Oklahoma City, Oklahoma, United States of America.
Department of Biostatistics, Epidemiology and Informatics, University of Pennsylvania, Philadelphia, PA, United States of America.
PLoS One. 2021 Feb 8;16(2):e0246761. doi: 10.1371/journal.pone.0246761. eCollection 2021.
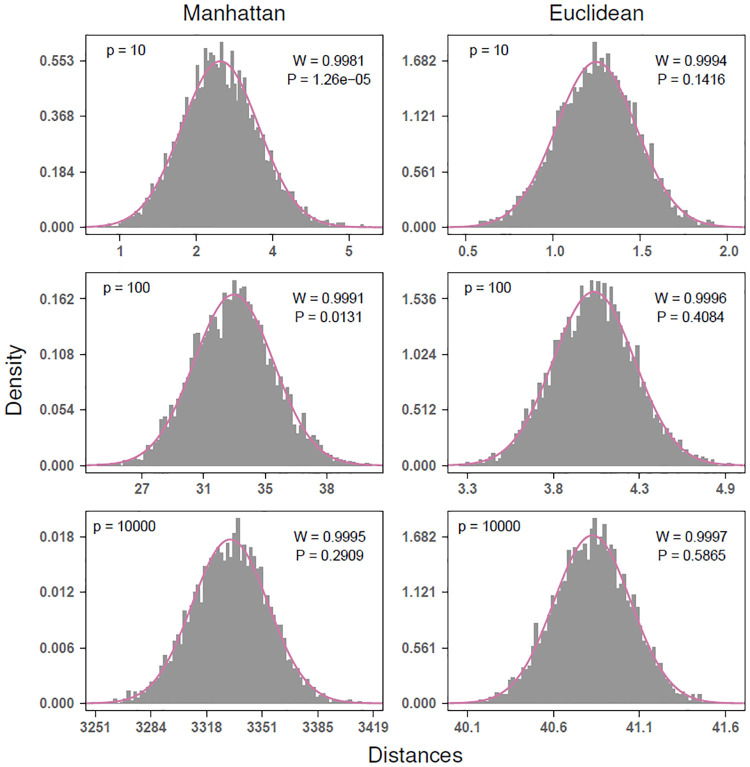
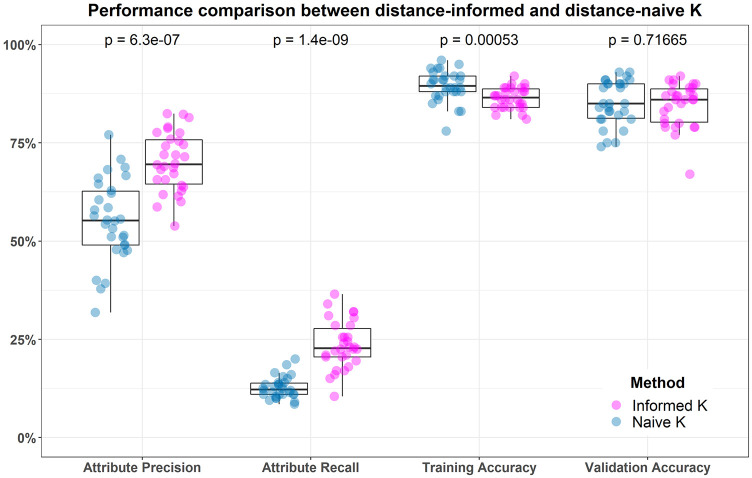
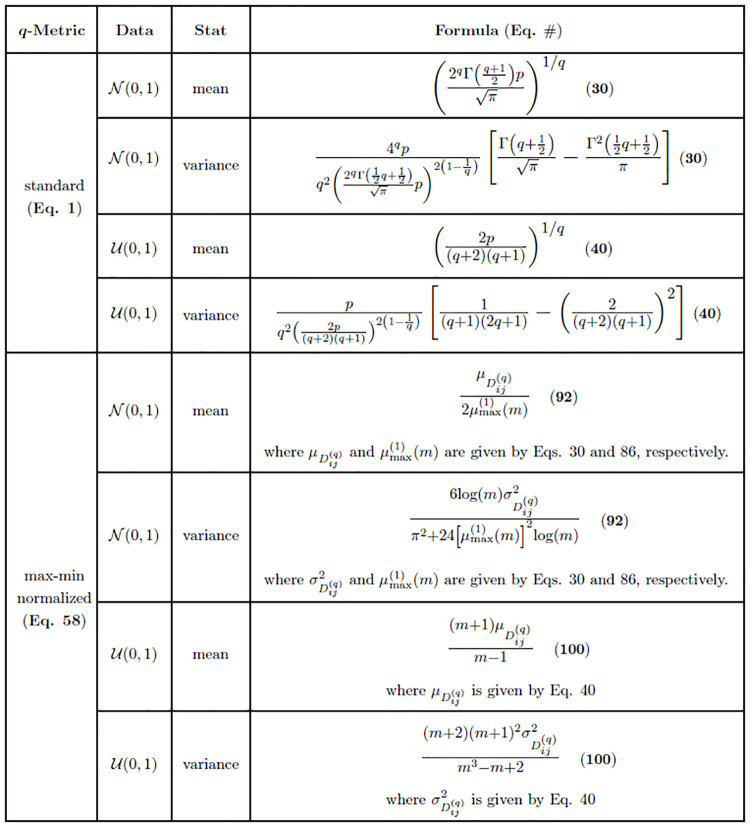
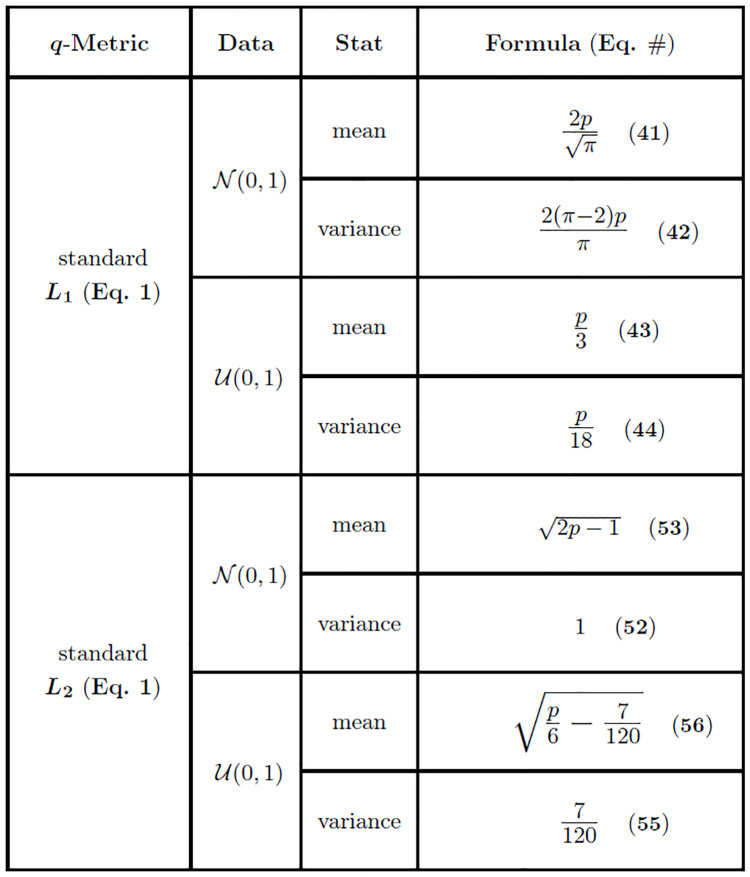
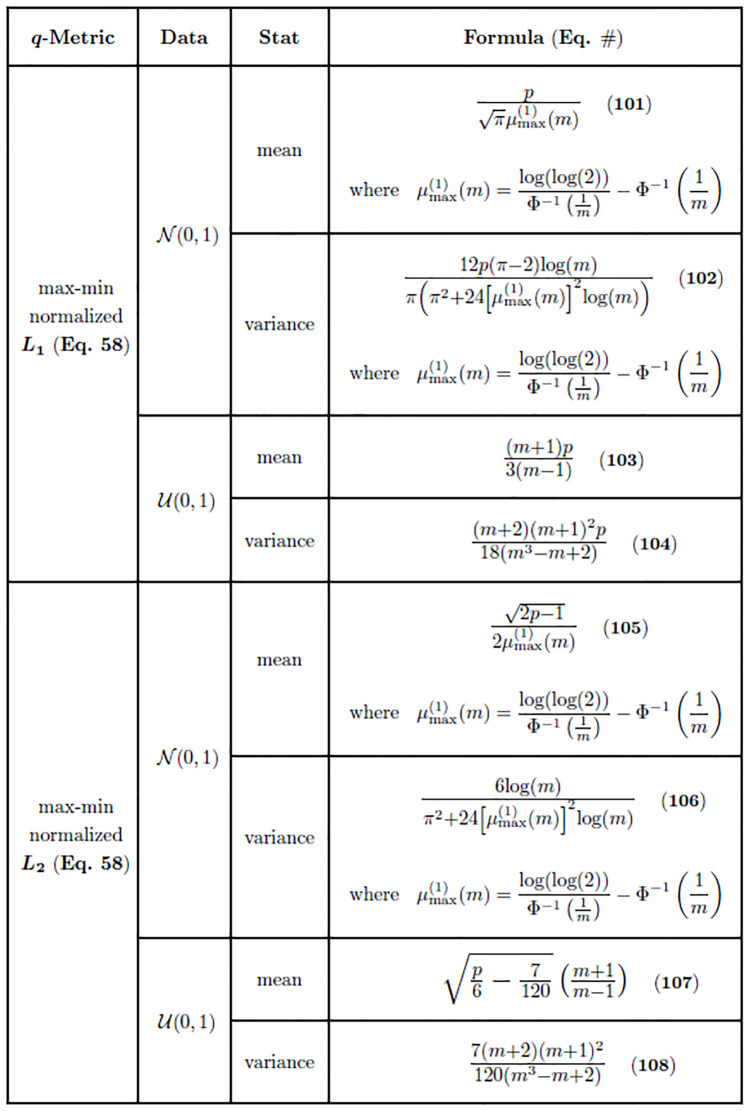
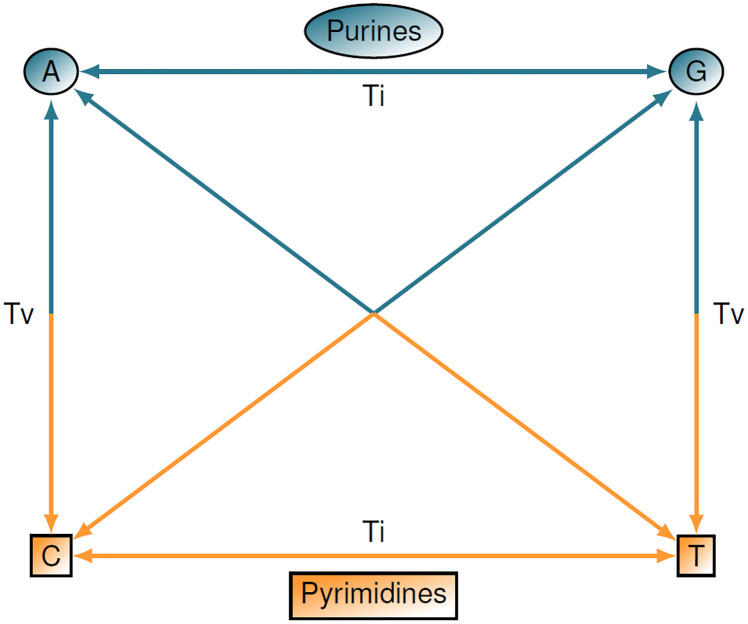
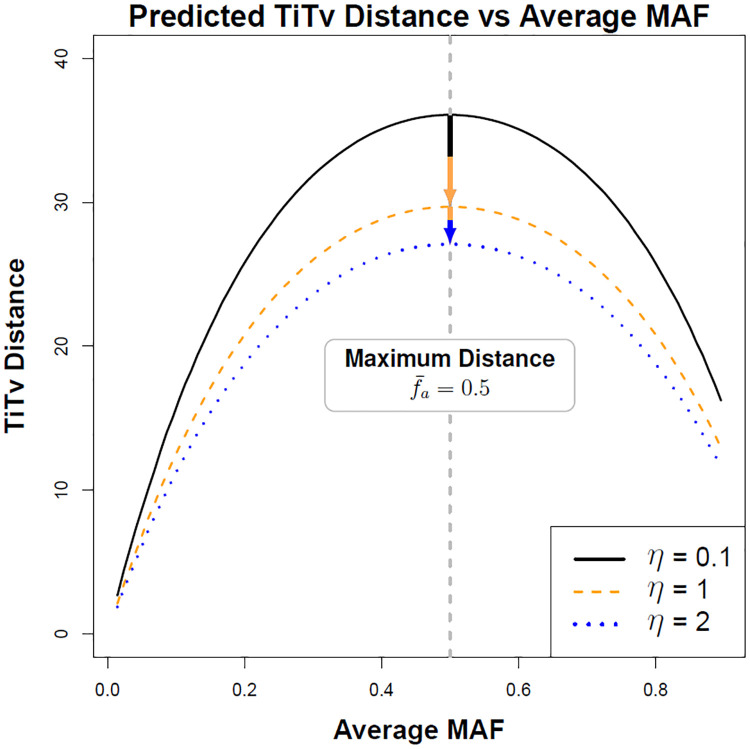
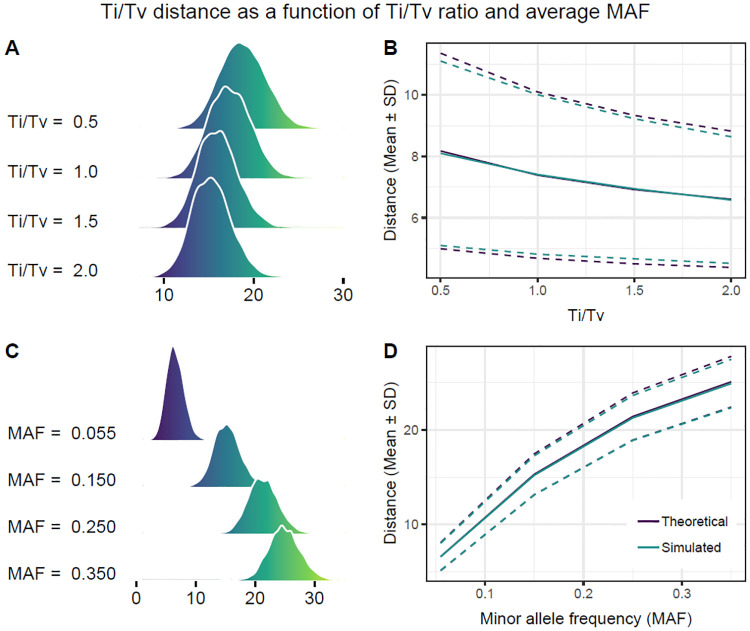
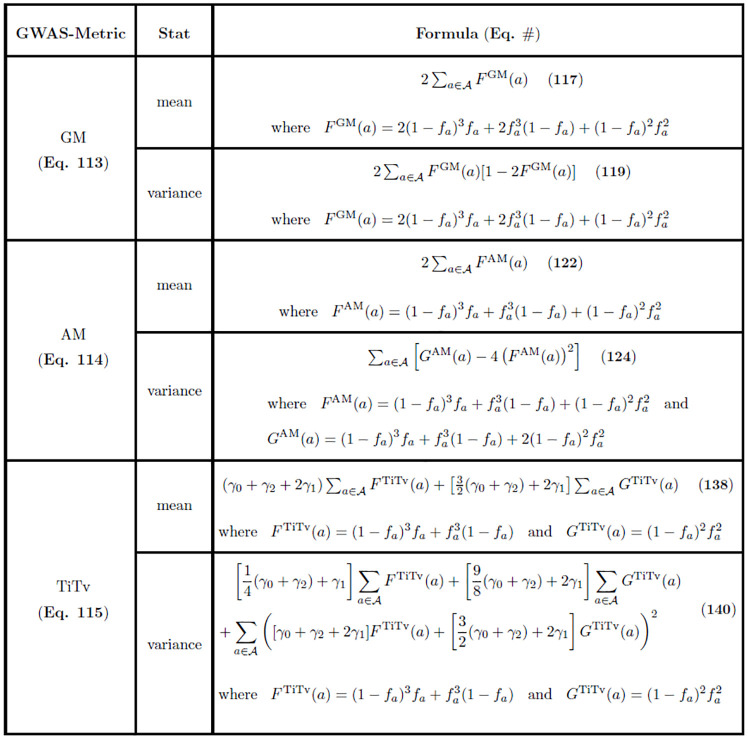
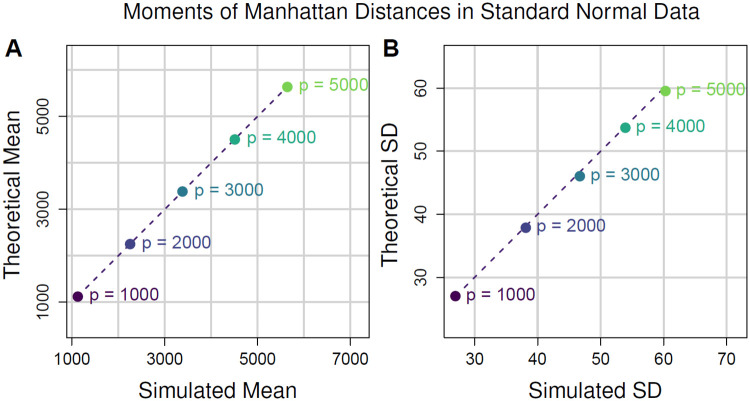
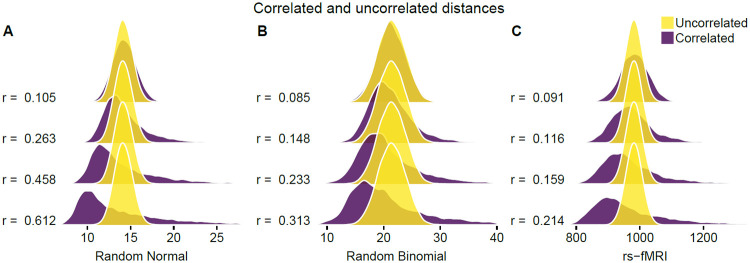
The performance of nearest-neighbor feature selection and prediction methods depends on the metric for computing neighborhoods and the distribution properties of the underlying data. Recent work to improve nearest-neighbor feature selection algorithms has focused on new neighborhood estimation methods and distance metrics. However, little attention has been given to the distributional properties of pairwise distances as a function of the metric or data type. Thus, we derive general analytical expressions for the mean and variance of pairwise distances for Lq metrics for normal and uniform random data with p attributes and m instances. The distribution moment formulas and detailed derivations provide a resource for understanding the distance properties for metrics and data types commonly used with nearest-neighbor methods, and the derivations provide the starting point for the following novel results. We use extreme value theory to derive the mean and variance for metrics that are normalized by the range of each attribute (difference of max and min). We derive analytical formulas for a new metric for genetic variants, which are categorical variables that occur in genome-wide association studies (GWAS). The genetic distance distributions account for minor allele frequency and the transition/transversion ratio. We introduce a new metric for resting-state functional MRI data (rs-fMRI) and derive its distance distribution properties. This metric is applicable to correlation-based predictors derived from time-series data. The analytical means and variances are in strong agreement with simulation results. We also use simulations to explore the sensitivity of the expected means and variances in the presence of correlation and interactions in the data. These analytical results and new metrics can be used to inform the optimization of nearest neighbor methods for a broad range of studies, including gene expression, GWAS, and fMRI data.
最近邻特征选择和预测方法的性能取决于用于计算邻域的度量以及基础数据的分布特性。近期改进最近邻特征选择算法的工作主要集中在新的邻域估计方法和距离度量上。然而,对于成对距离作为度量或数据类型函数的分布特性关注甚少。因此,我们推导了具有(p)个属性和(m)个实例的正态和均匀随机数据的(L_q)度量的成对距离均值和方差的一般解析表达式。分布矩公式和详细推导为理解最近邻方法常用的度量和数据类型的距离特性提供了资源,并且这些推导为以下新结果提供了起点。我们使用极值理论来推导通过每个属性的范围(最大值与最小值之差)进行归一化的度量的均值和方差。我们推导了一种用于遗传变异的新度量的解析公式,遗传变异是全基因组关联研究(GWAS)中出现的分类变量。遗传距离分布考虑了次要等位基因频率和转换/颠换比。我们为静息态功能磁共振成像数据(rs - fMRI)引入了一种新度量,并推导了其距离分布特性。此度量适用于从时间序列数据导出的基于相关性的预测器。解析均值和方差与模拟结果高度一致。我们还使用模拟来探索数据中存在相关性和相互作用时预期均值和方差的敏感性。这些解析结果和新度量可用于为广泛的研究(包括基因表达、GWAS和fMRI数据)优化最近邻方法提供参考。