Griffiths R, Schlüter D K, Akbari A, Cosgriff R, Tucker D, Taylor-Robinson D
Swansea University Medical School, Swansea University.
Health Data Research UK.
Int J Popul Data Sci. 2020 Aug 11;5(1):1346. doi: 10.23889/ijpds.v5i1.1346.
The challenges in identifying a cohort of people with a rare condition can be addressed by routinely collected, population-scale electronic health record (EHR) data, which provide large volumes of data at a national level. This paper describes the challenges of accurately identifying a cohort of children with Cystic Fibrosis (CF) using EHR and their validation against the UK CF Registry.
To establish a proof of principle and provide insight into the merits of linked data in CF research; to identify the benefits of access to multiple data sources, in particular the UK CF Registry data, and to demonstrate the opportunity it represents as a resource for future CF research.
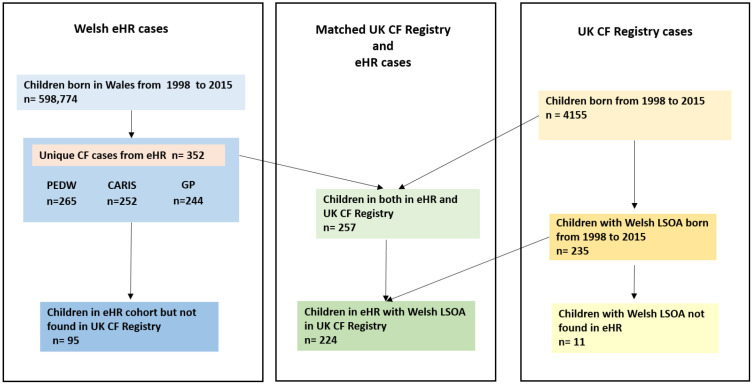
Three EHR data sources were used to identify children with CF born in Wales between 1 January 1998 and 31 August 2015 within the Secure Anonymised Information Linkage (SAIL) Databank. The UK CF Registry was later acquired by SAIL and linked to the EHR cohort to validate the cases and explore the reasons for misclassifications.
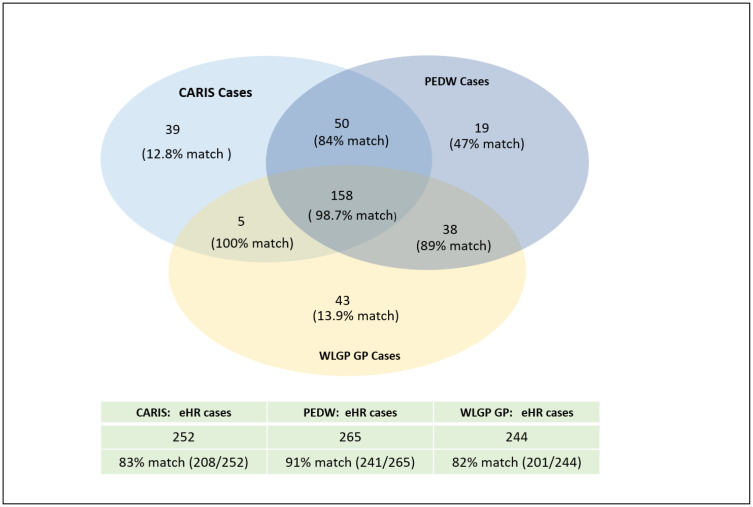
We identified 352 children with CF in the three EHR data sources. This was greater than expected based on historical incidence rates in Wales. Subsequent validation using the UK CF Registry found that 257 (73%) of these were true cases. Approximately 98.7% (156/158) of individuals identified as CF cases in all three EHR data sources were confirmed as true cases; but this was only the case for 19.8% (20/101) of all those identified in just a single data source.
Identifying health conditions in EHR data can be challenging, so data quality assurance and validation is important or the merit of the research is undermined. This retrospective review identifies some of the challenges in identifying CF cases and demonstrates the benefits of linking cases across multiple data sources to improve quality.
通过常规收集的、人口规模的电子健康记录(EHR)数据可以应对识别患有罕见疾病人群的挑战,这些数据在国家层面提供了大量数据。本文描述了使用电子健康记录准确识别一组囊性纤维化(CF)儿童的挑战,以及将他们与英国CF登记处进行验证的情况。
建立一个原理证明,并深入了解CF研究中关联数据的优点;确定访问多个数据源(特别是英国CF登记处数据)的好处,并展示其作为未来CF研究资源所代表的机会。
使用三个电子健康记录数据源来识别1998年1月1日至2015年8月31日在威尔士出生的患有CF的儿童,这些数据来自安全匿名信息链接(SAIL)数据库。英国CF登记处后来被SAIL收购,并与电子健康记录队列相链接,以验证病例并探究错误分类的原因。
我们在三个电子健康记录数据源中识别出352名患有CF的儿童。这比根据威尔士历史发病率预期的要多。随后使用英国CF登记处进行验证发现,其中257例(73%)为确诊病例。在所有三个电子健康记录数据源中被识别为CF病例的个体中,约98.7%(156/158)被确认为确诊病例;但在仅一个数据源中识别出的所有个体中,只有19.8%(20/101)是这种情况。
在电子健康记录数据中识别健康状况可能具有挑战性,因此数据质量保证和验证很重要,否则研究的价值将受到损害。这项回顾性研究确定了识别CF病例中的一些挑战,并展示了跨多个数据源链接病例以提高质量的好处。