Podhoranyi Michal
IT4Innovations - VSB Technical University, 17.listopadu 15, 70833 Ostrava, Czech Republic.
Earth Sci Inform. 2021;14(2):913-929. doi: 10.1007/s12145-021-00601-w. Epub 2021 Mar 11.
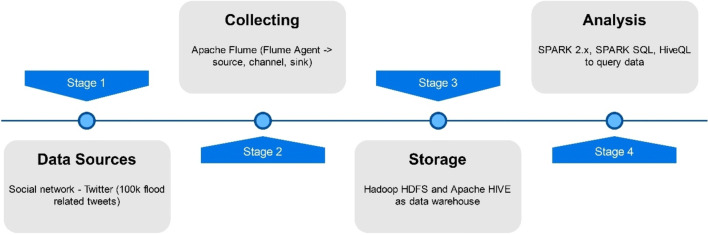
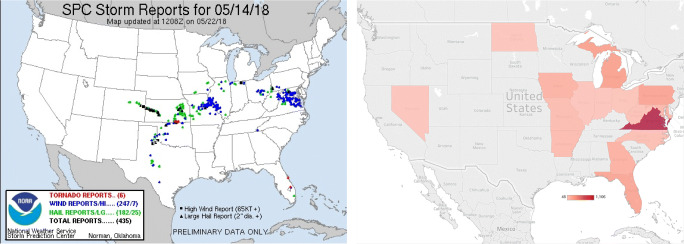
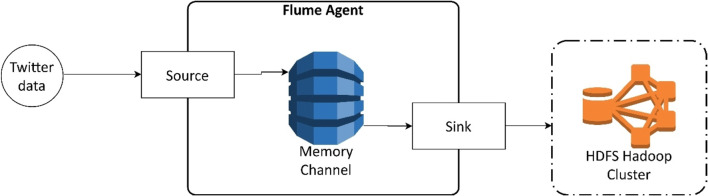
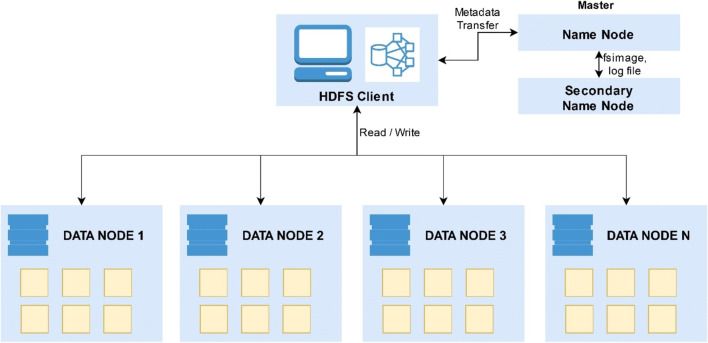
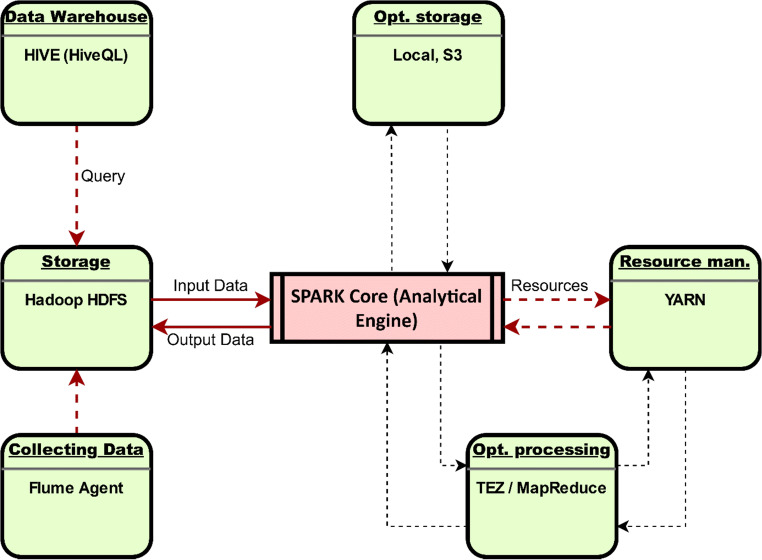
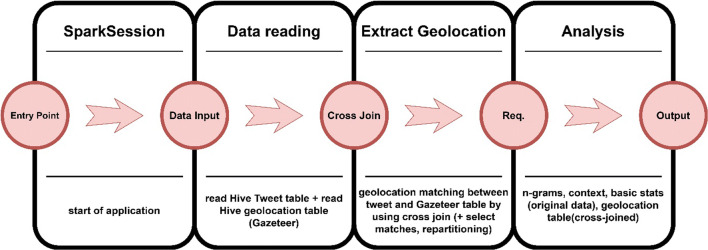
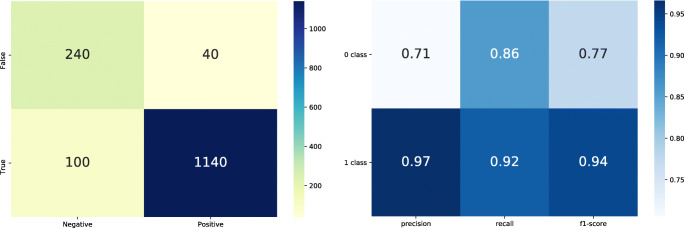
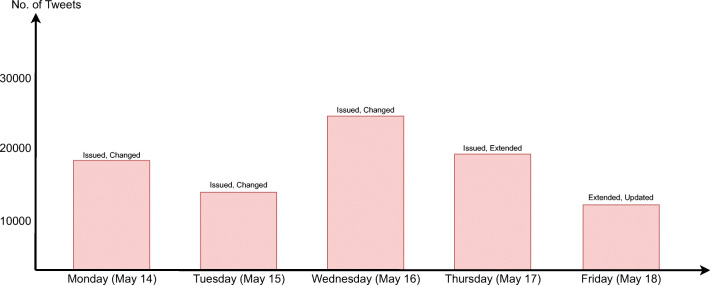
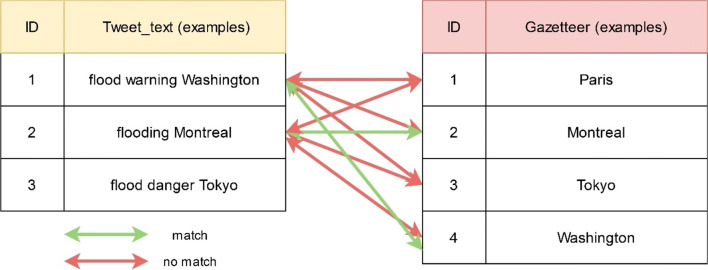
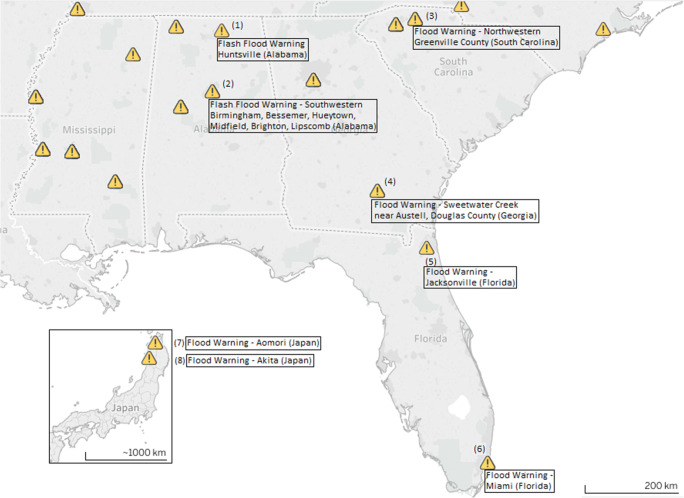
The main objective of the article is to propose an advanced architecture and workflow based on Apache Hadoop and Apache Spark big data platforms. The primary purpose of the presented architecture is collecting, storing, processing, and analysing intensive data from social media streams. This paper presents how the proposed architecture and data workflow can be applied to analyse Tweets with a specific flood topic. The secondary objective, trying to describe the flood alert situation by using only Tweet messages and exploring the informative potential of such data is demonstrated as well. The predictive machine learning approach based on Bayes Theorem was utilized to classify flood and no flood messages. For this study, approximately 100,000 Twitter messages were processed and analysed. Messages were related to the flooding domain and collected over a period of 5 days (14 May - 18 May 2018). Spark application was developed to run data processing commands automatically and to generate the appropriate output data. Results confirmed the advantages of many well-known features of Spark and Hadoop in social media data processing. It was noted that such technologies are prepared to deal with social media data streams, but there are still challenges that one has to take into account. Based on the flood tweet analysis, it was observed that Twitter messages with some considerations are informative enough to be used to estimate general flood alert situations in particular regions. Text analysis techniques proved that Twitter messages contain valuable flood-spatial information.
本文的主要目标是基于Apache Hadoop和Apache Spark大数据平台提出一种先进的架构和工作流程。所呈现架构的主要目的是收集、存储、处理和分析来自社交媒体流的密集数据。本文展示了所提出的架构和数据工作流程如何应用于分析特定洪水主题的推文。次要目标是,尝试仅使用推文消息描述洪水警报情况并探索此类数据的信息潜力,这一点也得到了证明。基于贝叶斯定理的预测性机器学习方法被用于对洪水和非洪水消息进行分类。在本研究中,大约处理和分析了100,000条Twitter消息。这些消息与洪水领域相关,是在5天(2018年5月14日至18日)的时间段内收集的。开发了Spark应用程序来自动运行数据处理命令并生成适当的输出数据。结果证实了Spark和Hadoop在社交媒体数据处理中许多知名特性的优势。值得注意的是,此类技术已准备好处理社交媒体数据流,但仍有一些挑战需要考虑。基于对洪水推文的分析,观察到经过一些考量的Twitter消息具有足够的信息量,可用于估计特定地区的一般洪水警报情况。文本分析技术证明Twitter消息包含有价值的洪水空间信息。