National Center for Computational Sciences, Oak Ridge National Laboratory, Oak Ridge, TN, United States of America.
Department of Computer Science, Virginia Tech, Blacksburg, VA, United States of America.
PLoS One. 2021 Apr 22;16(4):e0249410. doi: 10.1371/journal.pone.0249410. eCollection 2021.
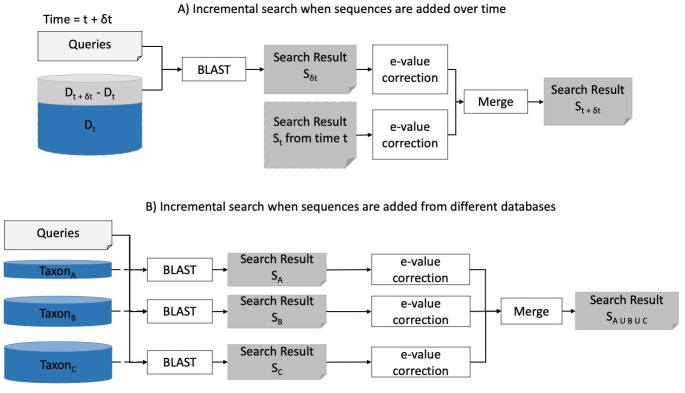
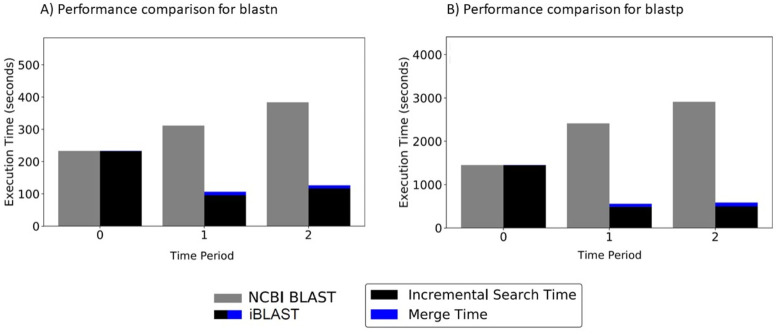
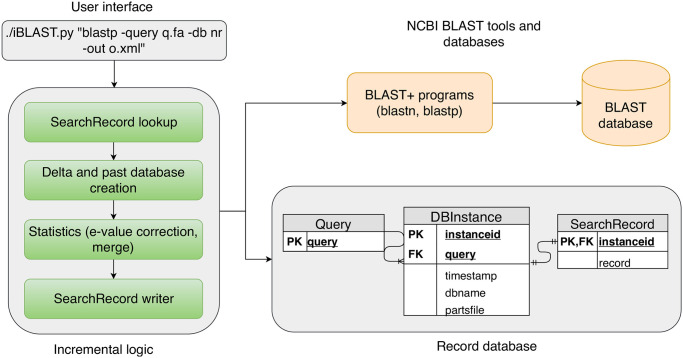
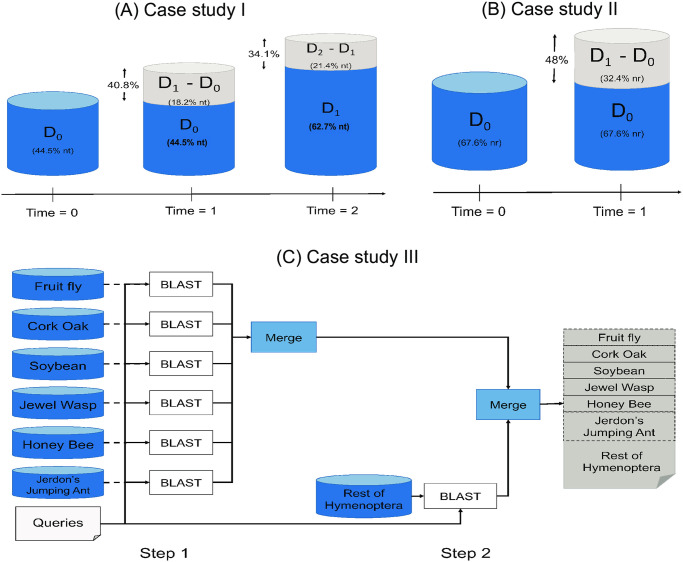
Search results from local alignment search tools use statistical scores that are sensitive to the size of the database to report the quality of the result. For example, NCBI BLAST reports the best matches using similarity scores and expect values (i.e., e-values) calculated against the database size. Given the astronomical growth in genomics data throughout a genomic research investigation, sequence databases grow as new sequences are continuously being added to these databases. As a consequence, the results (e.g., best hits) and associated statistics (e.g., e-values) for a specific set of queries may change over the course of a genomic investigation. Thus, to update the results of a previously conducted BLAST search to find the best matches on an updated database, scientists must currently rerun the BLAST search against the entire updated database, which translates into irrecoverable and, in turn, wasted execution time, money, and computational resources. To address this issue, we devise a novel and efficient method to redeem past BLAST searches by introducing iBLAST. iBLAST leverages previous BLAST search results to conduct the same query search but only on the incremental (i.e., newly added) part of the database, recomputes the associated critical statistics such as e-values, and combines these results to produce updated search results. Our experimental results and fidelity analyses show that iBLAST delivers search results that are identical to NCBI BLAST at a substantially reduced computational cost, i.e., iBLAST performs (1 + δ)/δ times faster than NCBI BLAST, where δ represents the fraction of database growth. We then present three different use cases to demonstrate that iBLAST can enable efficient biological discovery at a much faster speed with a substantially reduced computational cost.
搜索工具的局部比对搜索结果使用的统计分数对数据库的大小敏感,用于报告结果的质量。例如,NCBI BLAST 使用相似性分数和针对数据库大小计算的预期值(即 e 值)报告最佳匹配。由于基因组研究中基因组学数据的飞速增长,序列数据库随着新序列不断添加到这些数据库中而增长。因此,对于特定查询集的结果(例如最佳命中)和相关统计信息(例如 e 值)可能会在基因组研究过程中发生变化。因此,为了更新先前进行的 BLAST 搜索的结果,以在更新的数据库上找到最佳匹配,科学家目前必须针对整个更新的数据库重新运行 BLAST 搜索,这意味着不可恢复,并且反过来又浪费了执行时间、金钱和计算资源。为了解决这个问题,我们设计了一种新颖而有效的方法来通过引入 iBLAST 来赎回过去的 BLAST 搜索。iBLAST 利用以前的 BLAST 搜索结果来执行相同的查询搜索,但仅在数据库的增量(即新添加的部分)上进行,重新计算相关的关键统计信息,如 e 值,并将这些结果组合起来以生成更新的搜索结果。我们的实验结果和保真度分析表明,iBLAST 以大大降低的计算成本提供与 NCBI BLAST 相同的搜索结果,即 iBLAST 的执行速度比 NCBI BLAST 快 (1 + δ)/δ 倍,其中 δ 表示数据库增长的分数。然后,我们提出了三个不同的用例,以证明 iBLAST 可以以更低的计算成本实现更快的生物发现效率。