Division of Evolutionary Biology, Faculty of Biology, Ludwig Maximilian University of Munich, Grosshaderner Str. 2, 82152, Planegg-Martinsried, Germany.
Department of Behavioural Ecology and Evolutionary Genetics, Max Planck Institute for Ornithology, 82319, Seewiesen, Germany.
Behav Res Methods. 2021 Dec;53(6):2576-2590. doi: 10.3758/s13428-021-01587-5. Epub 2021 May 7.
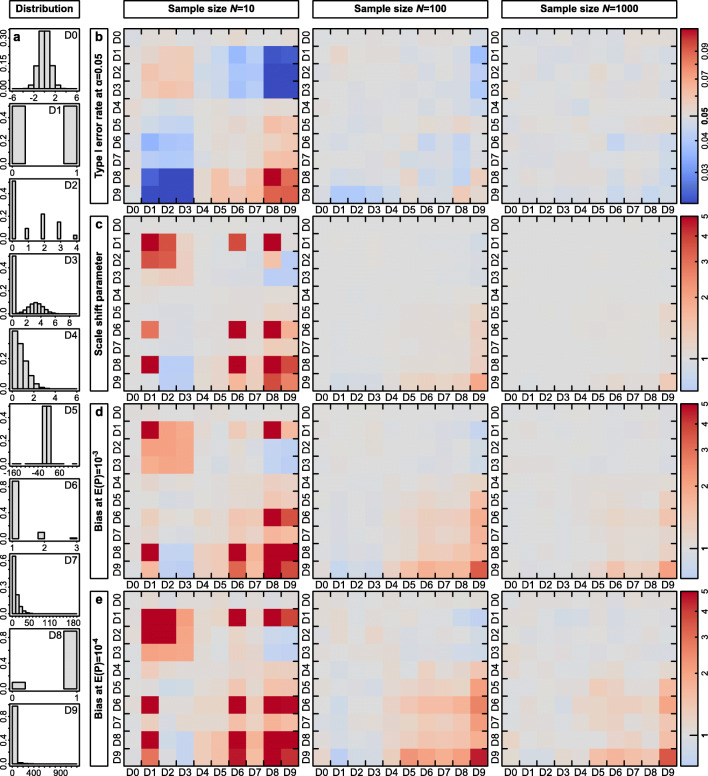
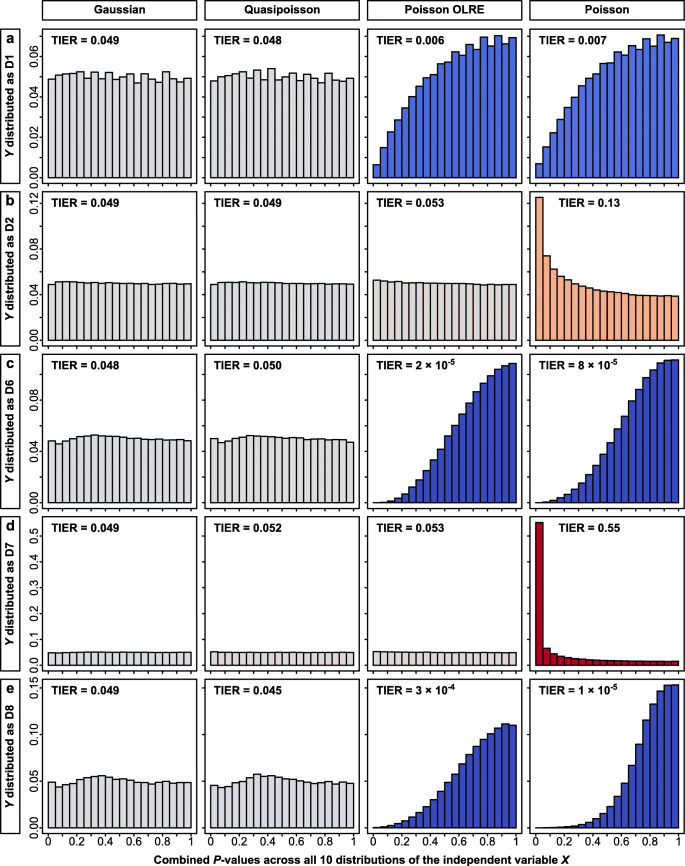
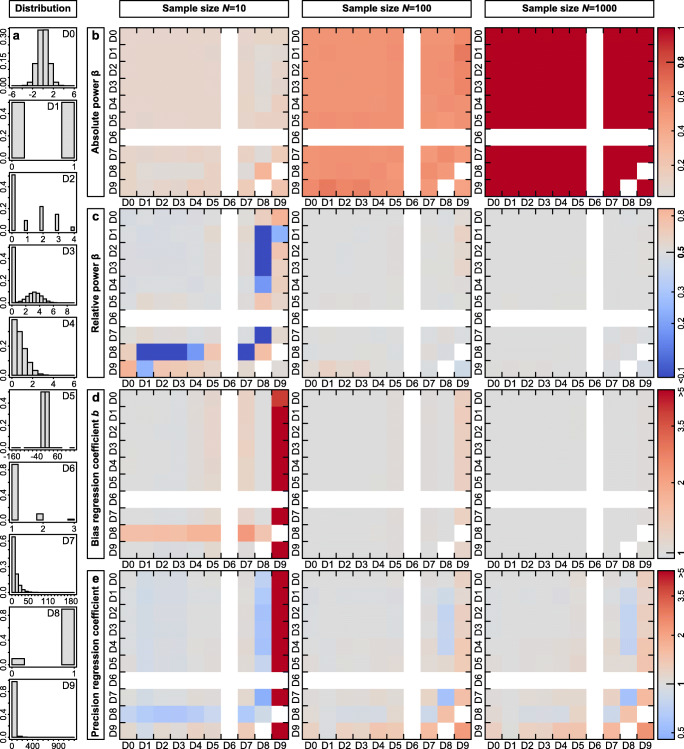
When data are not normally distributed, researchers are often uncertain whether it is legitimate to use tests that assume Gaussian errors, or whether one has to either model a more specific error structure or use randomization techniques. Here we use Monte Carlo simulations to explore the pros and cons of fitting Gaussian models to non-normal data in terms of risk of type I error, power and utility for parameter estimation. We find that Gaussian models are robust to non-normality over a wide range of conditions, meaning that p values remain fairly reliable except for data with influential outliers judged at strict alpha levels. Gaussian models also performed well in terms of power across all simulated scenarios. Parameter estimates were mostly unbiased and precise except if sample sizes were small or the distribution of the predictor was highly skewed. Transformation of data before analysis is often advisable and visual inspection for outliers and heteroscedasticity is important for assessment. In strong contrast, some non-Gaussian models and randomization techniques bear a range of risks that are often insufficiently known. High rates of false-positive conclusions can arise for instance when overdispersion in count data is not controlled appropriately or when randomization procedures ignore existing non-independencies in the data. Hence, newly developed statistical methods not only bring new opportunities, but they can also pose new threats to reliability. We argue that violating the normality assumption bears risks that are limited and manageable, while several more sophisticated approaches are relatively error prone and particularly difficult to check during peer review. Scientists and reviewers who are not fully aware of the risks might benefit from preferentially trusting Gaussian mixed models in which random effects account for non-independencies in the data.
当数据不符合正态分布时,研究人员通常不确定是否可以使用假设正态误差的测试,或者是否必须构建更具体的误差结构或使用随机化技术。在这里,我们使用蒙特卡罗模拟来探讨将正态模型拟合到非正态数据的优缺点,包括对第一类错误风险、功效和参数估计的实用性。我们发现,在广泛的条件下,正态模型对非正态性具有很强的鲁棒性,这意味着 p 值除了在严格的 alpha 水平下判断有影响的异常值的数据外,仍然相当可靠。正态模型在所有模拟情况下的功效也表现良好。除了样本量较小或预测变量的分布高度偏斜外,参数估计大多是无偏且精确的。在分析之前对数据进行转换通常是明智的,并且对异常值和异方差的直观检查对于评估很重要。相比之下,一些非正态模型和随机化技术存在一系列风险,这些风险通常知之甚少。例如,当未适当控制计数数据中的过分散或随机化程序忽略数据中现有的非独立性时,可能会出现高假阳性结论的风险。因此,新开发的统计方法不仅带来了新的机遇,而且还可能对可靠性构成新的威胁。我们认为,违反正态性假设带来的风险是有限且可控的,而一些更复杂的方法则相对容易出错,尤其是在同行评审期间难以检查。如果不完全了解风险,科学家和审稿人可能会受益于优先信任可以解释数据中非独立性的正态混合模型。