La Liga Nacional Contra el Cáncer de Guatemala y El Instituto de Cancerología y Hospital Dr. Bernardo del Valle, Guatemala, Guatemala.
Department of Pathology, Stanford University School of Medicine, Stanford, CA.
Blood Adv. 2021 May 25;5(10):2447-2455. doi: 10.1182/bloodadvances.2021004347.
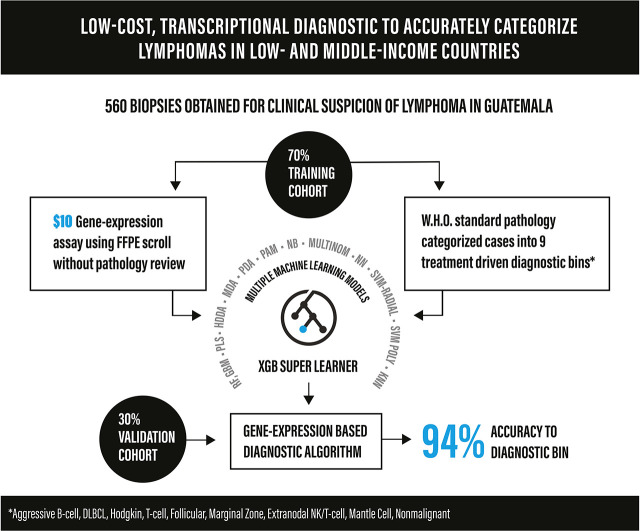
Inadequate diagnostics compromise cancer care across lower- and middle-income countries (LMICs). We hypothesized that an inexpensive gene expression assay using paraffin-embedded biopsy specimens from LMICs could distinguish lymphoma subtypes without pathologist input. We reviewed all biopsy specimens obtained at the Instituto de Cancerología y Hospital Dr. Bernardo Del Valle in Guatemala City between 2006 and 2018 for suspicion of lymphoma. Diagnoses were established based on the World Health Organization classification and then binned into 9 categories: nonmalignant, aggressive B-cell, diffuse large B-cell, follicular, Hodgkin, mantle cell, marginal zone, natural killer/T-cell, or mature T-cell lymphoma. We established a chemical ligation probe-based assay (CLPA) that quantifies expression of 37 genes by capillary electrophoresis with reagent/consumable cost of approximately $10/sample. To assign bins based on gene expression, 13 models were evaluated as candidate base learners, and class probabilities from each model were then used as predictors in an extreme gradient boosting super learner. Cases with call probabilities < 60% were classified as indeterminate. Four (2%) of 194 biopsy specimens in storage <3 years experienced assay failure. Diagnostic samples were divided into 70% (n = 397) training and 30% (n = 163) validation cohorts. Overall accuracy for the validation cohort was 86% (95% confidence interval [CI]: 80%-91%). After excluding 28 (17%) indeterminate calls, accuracy increased to 94% (95% CI: 89%-97%). Concordance was 97% for a set of high-probability calls (n = 37) assayed by CLPA in both the United States and Guatemala. Accuracy for a cohort of relapsed/refractory biopsy specimens (n = 39) was 79% and 88%, respectively, after excluding indeterminate cases. Machine-learning analysis of gene expression accurately classifies paraffin-embedded lymphoma biopsy specimens and could transform diagnosis in LMICs.
在中低收入国家(LMICs),诊断不足会影响癌症治疗。我们假设,使用来自 LMICs 的石蜡包埋活检标本进行廉价的基因表达分析,可以在没有病理学家输入的情况下区分淋巴瘤亚型。我们回顾了 2006 年至 2018 年期间在危地马拉城的癌症研究所和 Bernardo Del Valle 医院获得的所有疑似淋巴瘤的活检标本。根据世界卫生组织分类建立诊断,然后将其分为 9 类:非恶性、侵袭性 B 细胞、弥漫性大 B 细胞、滤泡性、霍奇金、套细胞、边缘区、自然杀伤/T 细胞或成熟 T 细胞淋巴瘤。我们建立了一种基于化学连接探针的检测方法(CLPA),通过毛细管电泳定量检测 37 个基因的表达,每个样本的试剂/耗材成本约为 10 美元。为了根据基因表达分配类别,我们评估了 13 个模型作为候选基本学习器,然后将每个模型的类别概率用作极端梯度增强超级学习者的预测因子。分类概率<60%的病例被归类为不确定。在存储时间<3 年的 194 个活检标本中,有 4 个(2%)检测失败。诊断样本分为 70%(n=397)训练集和 30%(n=163)验证集。验证集的总准确率为 86%(95%置信区间[CI]:80%-91%)。排除 28 例(17%)不确定分类后,准确率提高到 94%(95%CI:89%-97%)。在对美国和危地马拉的一组高概率病例(n=37)进行 CLPA 检测时,结果的一致性为 97%。排除不确定病例后,复发/难治性活检标本队列(n=39)的准确率分别为 79%和 88%。基因表达的机器学习分析可以准确地对石蜡包埋的淋巴瘤活检标本进行分类,并可能改变中低收入国家的诊断方式。