Department of Industrial Engineering and Management Systems, University of Central Florida, Orlando, Florida, United States of America.
PLoS One. 2021 Jul 6;16(7):e0253925. doi: 10.1371/journal.pone.0253925. eCollection 2021.
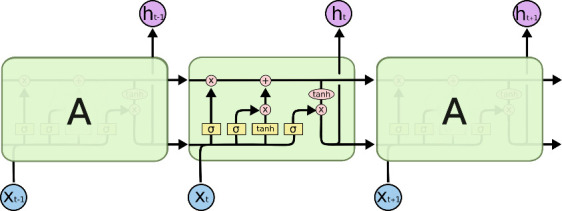
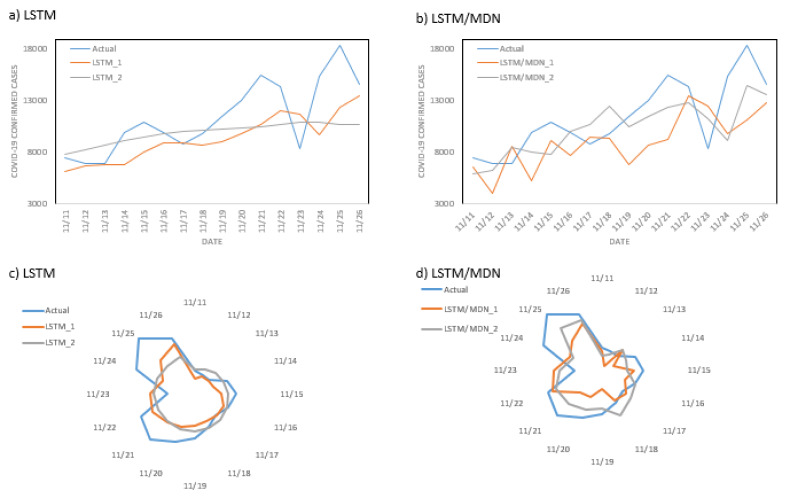
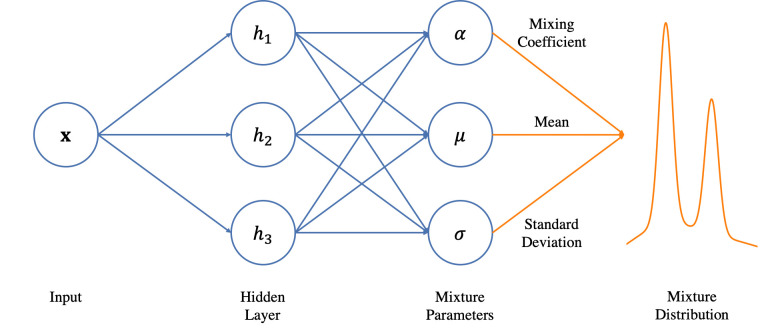
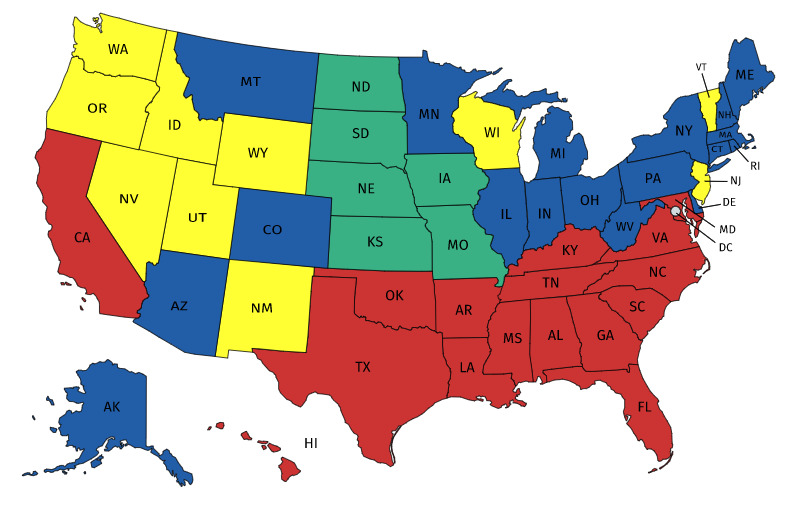
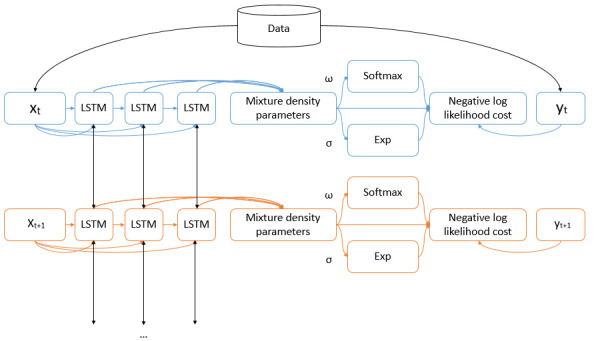
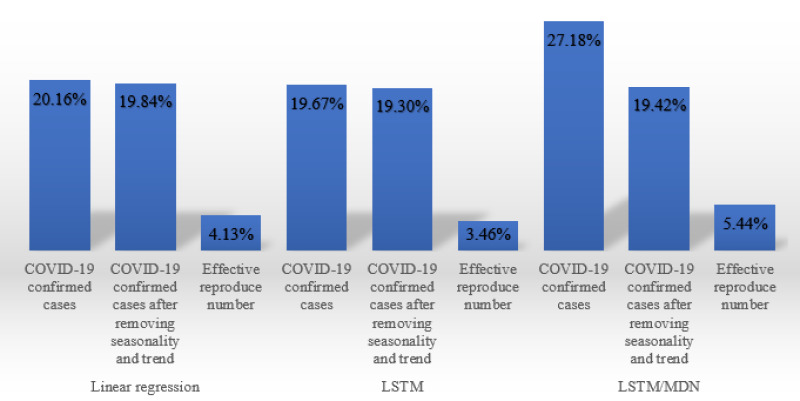
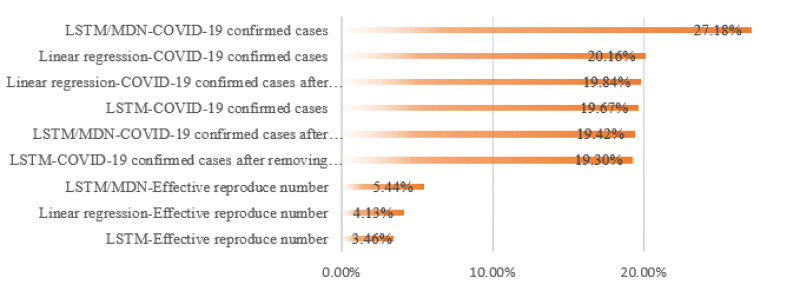
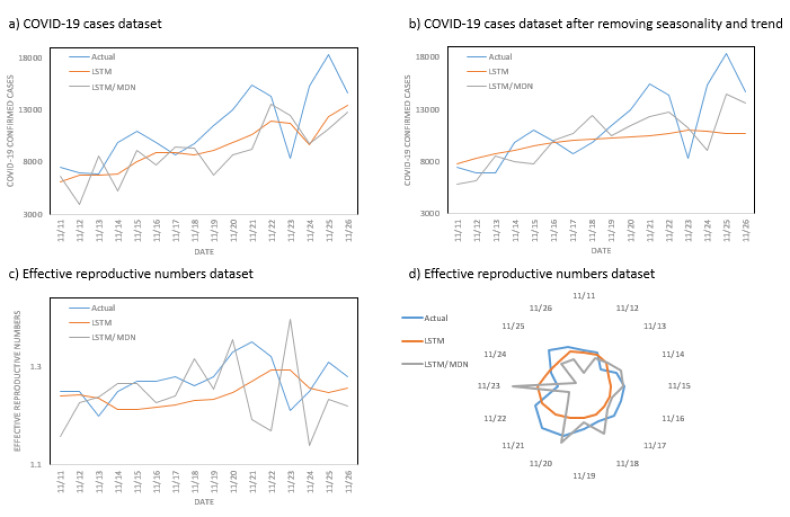
Optimizing COVID-19 vaccine distribution can help plan around the limited production and distribution of vaccination, particularly in early stages. One of the main criteria for equitable vaccine distribution is predicting the geographic distribution of active virus at the time of vaccination. This research developed sequence-learning models to predict the behavior of the COVID-19 pandemic across the US, based on previously reported information. For this objective, we used two time-series datasets of confirmed COVID-19 cases and COVID-19 effective reproduction numbers from January 22, 2020 to November 26, 2020 for all states in the US. The datasets have 310 time-steps (days) and 50 features (US states). To avoid training the models for all states, we categorized US states on the basis of their similarity to previously reported COVID-19 behavior. For this purpose, we used an unsupervised self-organizing map to categorize all states of the US into four groups on the basis of the similarity of their effective reproduction numbers. After selecting a leading state (the state with earliest outbreaks) in each group, we developed deterministic and stochastic Long Short Term Memory (LSTM) and Mixture Density Network (MDN) models. We trained the models with data from each leading state to make predictions, then compared the models with a baseline linear regression model. We also remove seasonality and trends from a dataset of non-stationary COVID-19 cases to determine the effects on prediction. We showed that the deterministic LSTM model trained on the COVID-19 effective reproduction numbers outperforms other prediction methods.
优化 COVID-19 疫苗的分配可以帮助规划疫苗的有限生产和分配,尤其是在早期阶段。公平分配疫苗的主要标准之一是预测疫苗接种时活跃病毒的地理分布。这项研究开发了基于先前报告的信息预测美国 COVID-19 大流行行为的序列学习模型。为此,我们使用了来自 2020 年 1 月 22 日至 2020 年 11 月 26 日美国所有州的确诊 COVID-19 病例和 COVID-19 有效繁殖数的两个时间序列数据集。这些数据集有 310 个时间步(天)和 50 个特征(美国各州)。为了避免对所有州进行模型训练,我们根据各州与先前报告的 COVID-19 行为的相似性对美国各州进行了分类。为此,我们使用无监督自组织映射根据各州有效繁殖数的相似性将美国所有州分为四组。在每组中选择一个领先州(最早爆发的州)后,我们开发了确定性和随机长短期记忆(LSTM)和混合密度网络(MDN)模型。我们使用来自每个领先州的数据对模型进行训练以进行预测,然后将模型与基线线性回归模型进行比较。我们还从非平稳 COVID-19 病例的数据集去除季节性和趋势,以确定对预测的影响。我们表明,基于 COVID-19 有效繁殖数训练的确定性 LSTM 模型优于其他预测方法。