Cohen K Bretonnel, Hunter Lawrence E, Palmer Martha
Computational Bioscience Program, University of Colorado School of Medicine, Aurora, Colorado, USA; Department of Linguistics, University of Colorado at Boulder, Boulder, Colorado, USA.
Trust Eternal Syst Via Evol Softw Data Knowl (2012). 2013;379:77-90. doi: 10.1007/978-3-642-45260-4_6.
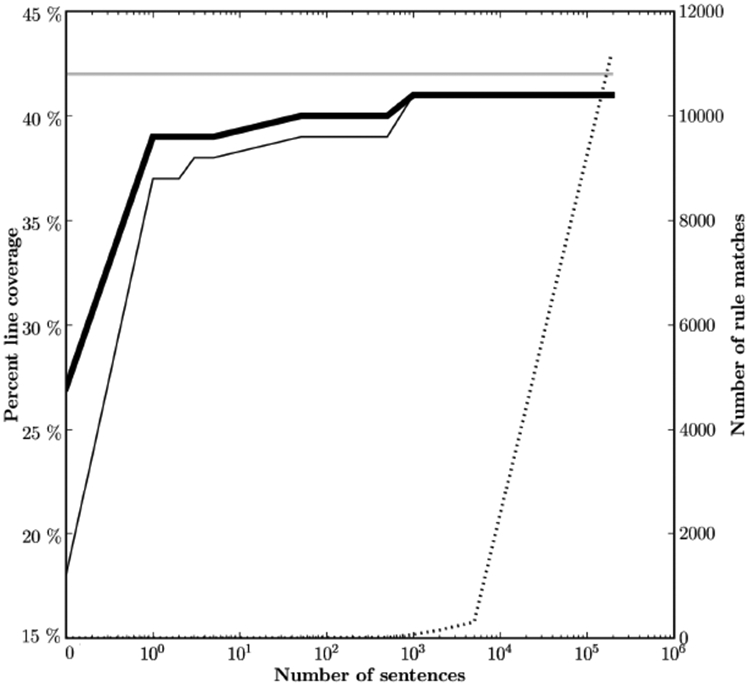
Significant progress has been made in addressing the scientific challenges of biomedical text mining. However, the transition from a demonstration of scientific progress to the production of tools on which a broader community can rely requires that fundamental software engineering requirements be addressed. In this paper we characterize the state of biomedical text mining software with respect to software testing and quality assurance. Biomedical natural language processing software was chosen because it frequently specifically claims to offer production-quality services, rather than just research prototypes. We examined twenty web sites offering a variety of text mining services. On each web site, we performed the most basic software test known to us and classified the results. Seven out of twenty web sites returned either bad results or the worst class of results in response to this simple test. We conclude that biomedical natural language processing tools require greater attention to software quality. We suggest a linguistically motivated approach to granular evaluation of natural language processing applications, and show how it can be used to detect performance errors of several systems and to predict overall performance on specific equivalence classes of inputs. We also assess the ability of linguistically-motivated test suites to provide good software testing, as compared to large corpora of naturally-occurring data. We measure code coverage and find that it is considerably higher when even small structured test suites are utilized than when large corpora are used.
在应对生物医学文本挖掘的科学挑战方面已取得重大进展。然而,从科学进展的展示过渡到生产出更广泛的群体可以依赖的工具,需要解决基本的软件工程要求。在本文中,我们针对软件测试和质量保证描述了生物医学文本挖掘软件的现状。之所以选择生物医学自然语言处理软件,是因为它经常特别宣称提供生产质量的服务,而不仅仅是研究原型。我们考察了提供各种文本挖掘服务的二十个网站。在每个网站上,我们进行了我们所知的最基本的软件测试并对结果进行分类。二十个网站中有七个在回应这个简单测试时返回了错误结果或最差等级的结果。我们得出结论,生物医学自然语言处理工具需要更加关注软件质量。我们提出一种基于语言学的方法来对自然语言处理应用进行粒度评估,并展示它如何用于检测多个系统的性能错误以及预测在特定等效输入类上的整体性能。与大量自然出现的数据语料库相比,我们还评估了基于语言学的测试套件提供良好软件测试的能力。我们测量代码覆盖率,发现即使使用小型结构化测试套件时的代码覆盖率也比使用大型语料库时高得多。