Adams Joel R, Salem Alexandra C, MacFarlane Heather, Ingham Rosemary, Bedrick Steven D, Fombonne Eric, Dolata Jill K, Hill Alison Presmanes, van Santen Jan
Center for Spoken Language Understanding, Oregon Health & Science University, Portland, OR, United States.
Department of Psychiatry, Oregon Health & Science University, Portland, OR, United States.
Front Psychol. 2021 Jul 21;12:668344. doi: 10.3389/fpsyg.2021.668344. eCollection 2021.
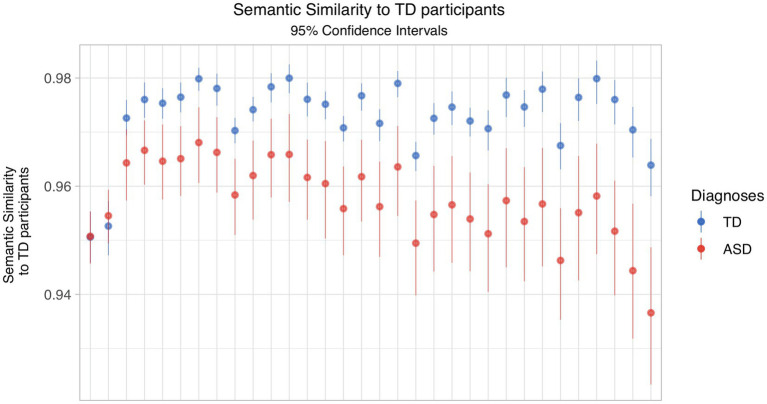
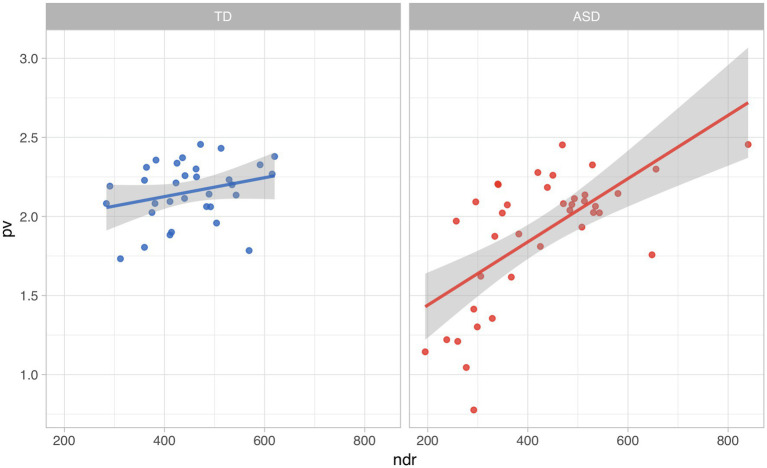
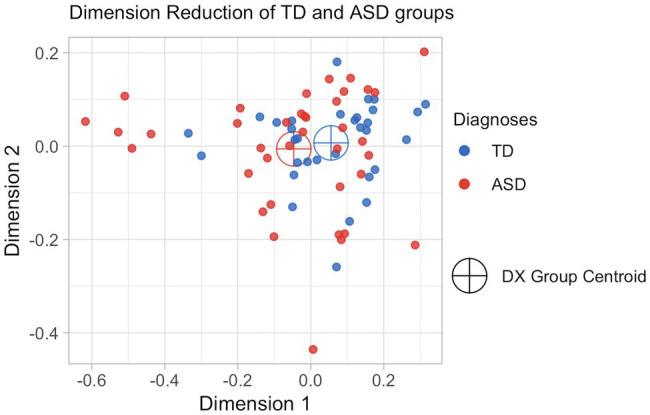
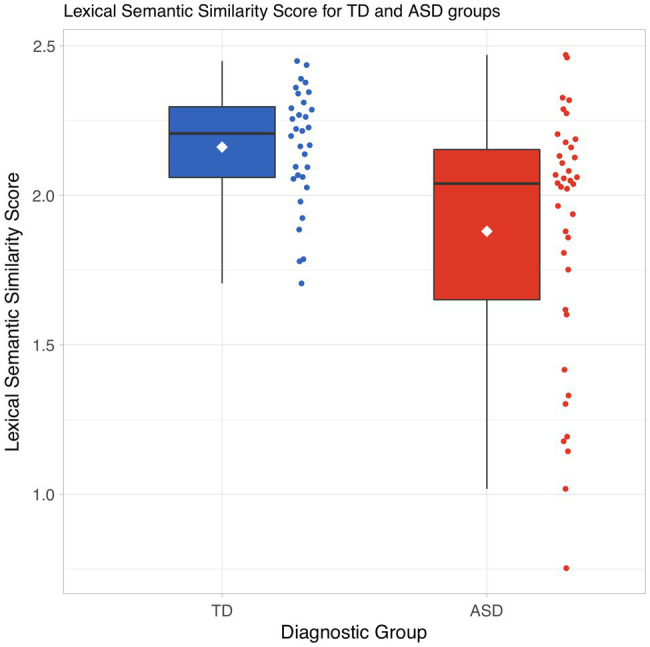
Conversational impairments are well known among people with autism spectrum disorder (ASD), but their measurement requires time-consuming manual annotation of language samples. Natural language processing (NLP) has shown promise in identifying semantic difficulties when compared to clinician-annotated reference transcripts. Our goal was to develop a novel measure of lexico-semantic similarity - based on recent work in natural language processing (NLP) and recent applications of pseudo-value analysis - which could be applied to transcripts of children's conversational language, without recourse to some ground-truth reference document. We hypothesized that: (a) semantic coherence, as measured by this method, would discriminate between children with and without ASD and (b) more variability would be found in the group with ASD. We used data from 70 4- to 8-year-old males with ASD ( = 38) or typically developing (TD; = 32) enrolled in a language study. Participants were administered a battery of standardized diagnostic tests, including the Autism Diagnostic Observation Schedule (ADOS). ADOS was recorded and transcribed, and we analyzed children's language output during the conversation/interview ADOS tasks. Transcripts were converted to vectors a word2vec model trained on the Google News Corpus. Pairwise similarity across all subjects and a sample grand mean were calculated. Using a leave-one-out algorithm, a pseudo-value, detailed below, representing each subject's contribution to the grand mean was generated. Means of pseudo-values were compared between the two groups. Analyses were co-varied for nonverbal IQ, mean length of utterance, and number of distinct word roots (NDR). Statistically significant differences were observed in means of pseudo-values between TD and ASD groups ( 0.007). TD subjects had higher pseudo-value scores suggesting that similarity scores of TD subjects were more similar to the overall group mean. Variance of pseudo-values was greater in the ASD group. Nonverbal IQ, mean length of utterance, or NDR did not account for between group differences. The findings suggest that our pseudo-value-based method can be effectively used to identify specific semantic difficulties that characterize children with ASD without requiring a reference transcript.
自闭症谱系障碍(ASD)患者存在明显的对话障碍,但其测量需要对语言样本进行耗时的人工标注。与临床医生标注的参考转录本相比,自然语言处理(NLP)在识别语义困难方面显示出了潜力。我们的目标是基于自然语言处理(NLP)的最新研究成果和伪值分析的最新应用,开发一种新的词汇语义相似度测量方法,该方法可应用于儿童对话语言的转录本,而无需借助某些真实的参考文档。我们假设:(a)通过这种方法测量的语义连贯性能够区分患有和未患有ASD的儿童,(b)ASD组会表现出更大的变异性。我们使用了来自70名4至8岁男性的数据,这些男性参与了一项语言研究,其中38名患有ASD,32名发育正常(TD)。参与者接受了一系列标准化诊断测试,包括自闭症诊断观察量表(ADOS)。对ADOS进行了记录和转录,我们分析了儿童在ADOS对话/访谈任务中的语言输出。转录本通过在谷歌新闻语料库上训练的word2vec模型转换为向量。计算了所有受试者之间的成对相似度和样本总体均值。使用留一法算法,生成了一个代表每个受试者对总体均值贡献的伪值(详细信息如下)。比较了两组之间伪值的均值。分析对非言语智商、平均话语长度和不同词根数量(NDR)进行了协变量调整。在TD组和ASD组之间观察到伪值均值存在统计学上的显著差异(P = 0.007)。TD受试者的伪值得分更高,这表明TD受试者的相似度得分与总体组均值更相似。ASD组的伪值方差更大。非言语智商、平均话语长度或NDR并不能解释组间差异。研究结果表明,我们基于伪值的方法可以有效地用于识别患有ASD儿童所特有的特定语义困难,而无需参考转录本。