Faculty of Electrical Engineering, Mathematics and Computer Science, Quantum & Computer Engineering Department, Mekelweg 4, 2628 CD Delft, Netherlands.
IBM Austin, TX, USA.
Gigascience. 2021 Sep 7;10(9). doi: 10.1093/gigascience/giab057.
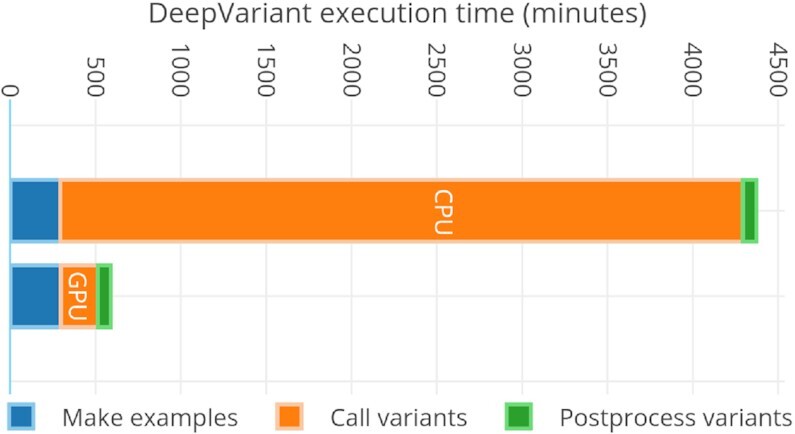
Recently many new deep learning-based variant-calling methods like DeepVariant have emerged as more accurate compared with conventional variant-calling algorithms such as GATK HaplotypeCaller, Sterlka2, and Freebayes albeit at higher computational costs. Therefore, there is a need for more scalable and higher performance workflows of these deep learning methods. Almost all existing cluster-scaled variant-calling workflows that use Apache Spark/Hadoop as big data frameworks loosely integrate existing single-node pre-processing and variant-calling applications. Using Apache Spark just for distributing/scheduling data among loosely coupled applications or using I/O-based storage for storing the output of intermediate applications does not exploit the full benefit of Apache Spark in-memory processing. To achieve this, we propose a native Spark-based workflow that uses Python and Apache Arrow to enable efficient transfer of data between different workflow stages. This benefits from the ease of programmability of Python and the high efficiency of Arrow's columnar in-memory data transformations.
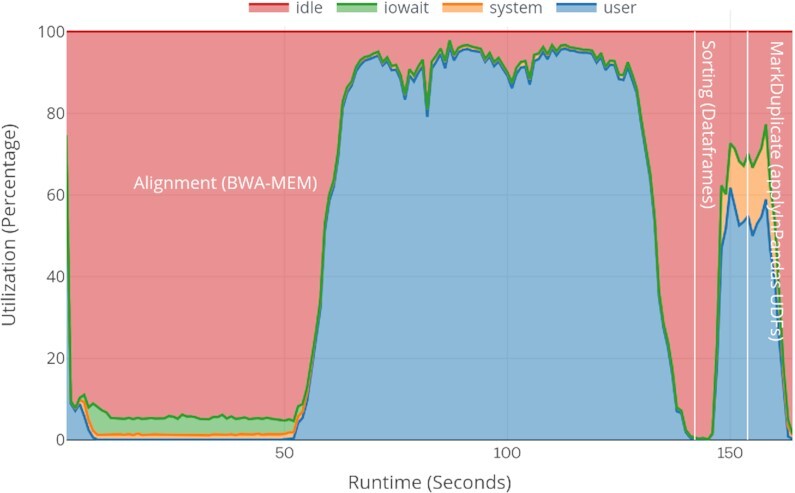
Here we present a scalable, parallel, and efficient implementation of next-generation sequencing data pre-processing and variant-calling workflows. Our design tightly integrates most pre-processing workflow stages, using Spark built-in functions to sort reads by coordinates and mark duplicates efficiently. Our approach outperforms state-of-the-art implementations by >2 times for the pre-processing stages, creating a scalable and high-performance solution for DeepVariant for both CPU-only and CPU + GPU clusters.
We show the feasibility and easy scalability of our approach to achieve high performance and efficient resource utilization for variant-calling analysis on high-performance computing clusters using the standardized Apache Arrow data representations. All codes, scripts, and configurations used to run our implementations are publicly available and open sourced; see https://github.com/abs-tudelft/variant-calling-at-scale.
与 GATK HaplotypeCaller、Sterlka2 和 Freebayes 等传统变异calling 算法相比,最近出现了许多基于深度学习的新型变异calling 方法,如 DeepVariant,其准确性更高,尽管计算成本更高。因此,这些深度学习方法需要更具可扩展性和更高性能的工作流程。几乎所有现有的基于集群的变异calling 工作流程都使用 Apache Spark/Hadoop 作为大数据框架,松散地集成了现有的单节点预处理和变异calling 应用程序。使用 Apache Spark 仅用于在松散耦合的应用程序之间分发/调度数据,或者使用基于 I/O 的存储来存储中间应用程序的输出,并不能充分利用 Apache Spark 的内存处理优势。为了实现这一点,我们提出了一种基于 Spark 的原生工作流程,该流程使用 Python 和 Apache Arrow 来实现不同工作流程阶段之间的数据高效传输。这得益于 Python 的易于编程性和 Arrow 的列式内存数据转换的高效率。
在这里,我们提出了一种可扩展的、并行的和高效的下一代测序数据预处理和变异calling 工作流程的实现。我们的设计紧密集成了大多数预处理工作流程阶段,使用 Spark 内置函数按坐标对读取进行排序,并有效地标记重复项。我们的方法在预处理阶段的性能比最先进的实现高出>2 倍,为仅 CPU 和 CPU+GPU 集群上的 DeepVariant 提供了一种可扩展且高性能的解决方案。
我们展示了我们的方法的可行性和易于扩展性,以使用标准化的 Apache Arrow 数据表示实现高性能和高效的资源利用,用于高性能计算集群上的变异calling 分析。所有用于运行我们的实现的代码、脚本和配置都可公开获得并开源;请访问 https://github.com/abs-tudelft/variant-calling-at-scale。