College of Computer Engineering and Applied Mathematics, Changsha University, Changsha, 410022, China.
Hunan Province Key Laboratory of Industrial Internet Technology and Security, Changsha University, Changsha, 410022, China.
BMC Bioinformatics. 2021 Sep 8;22(1):430. doi: 10.1186/s12859-021-04300-7.
Essential proteins have great impacts on cell survival and development, and played important roles in disease analysis and new drug design. However, since it is inefficient and costly to identify essential proteins by using biological experiments, then there is an urgent need for automated and accurate detection methods. In recent years, the recognition of essential proteins in protein interaction networks (PPI) has become a research hotspot, and many computational models for predicting essential proteins have been proposed successively.
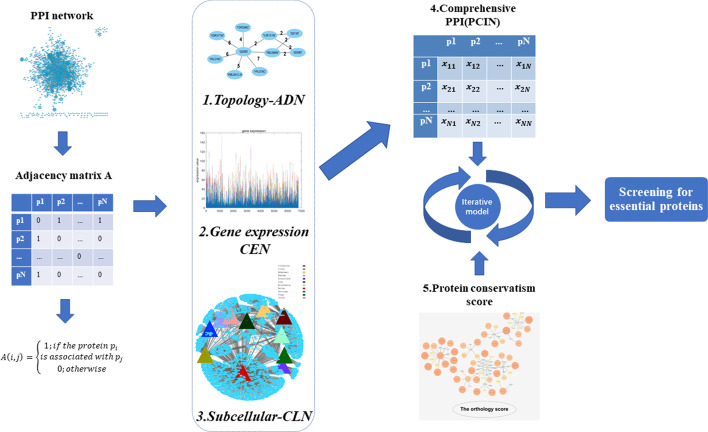
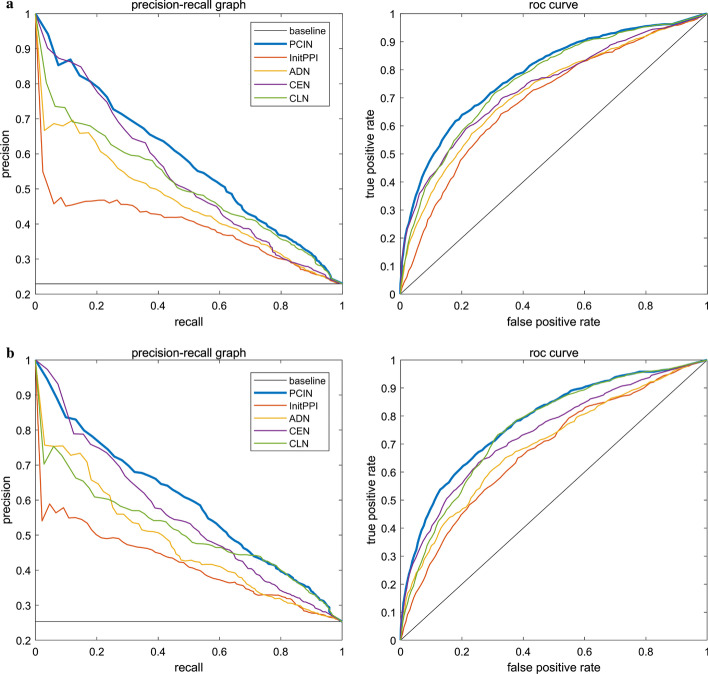
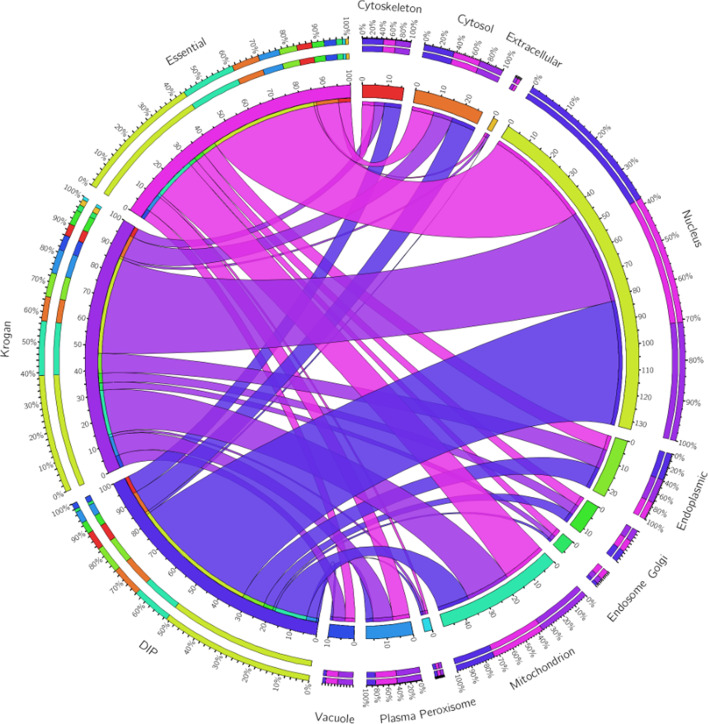
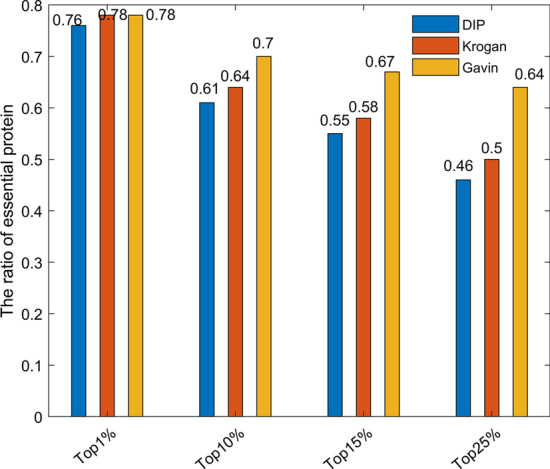
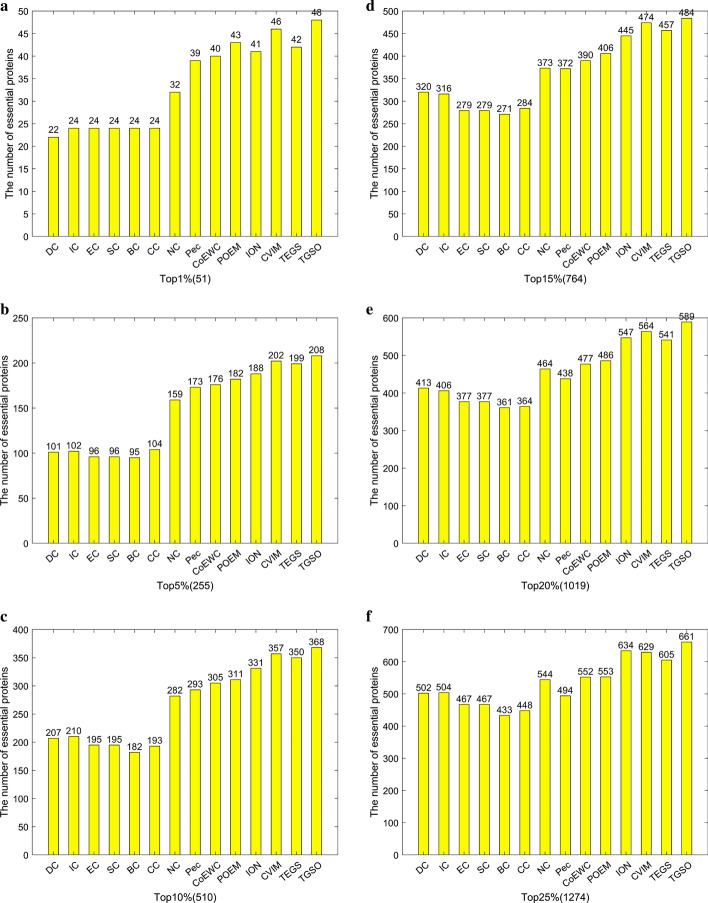
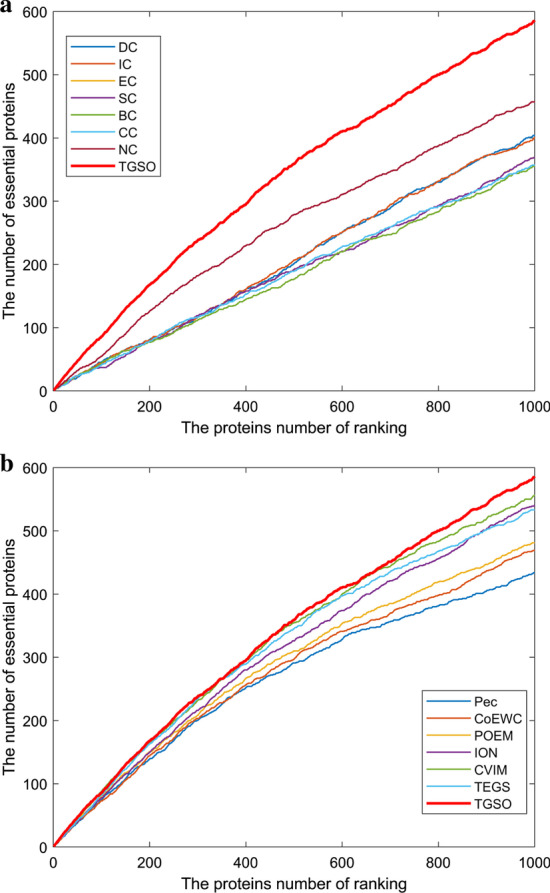
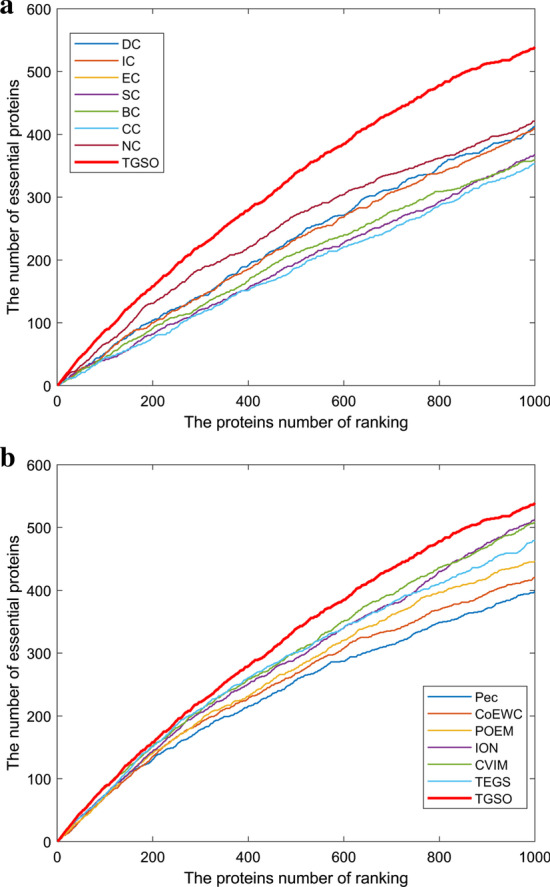
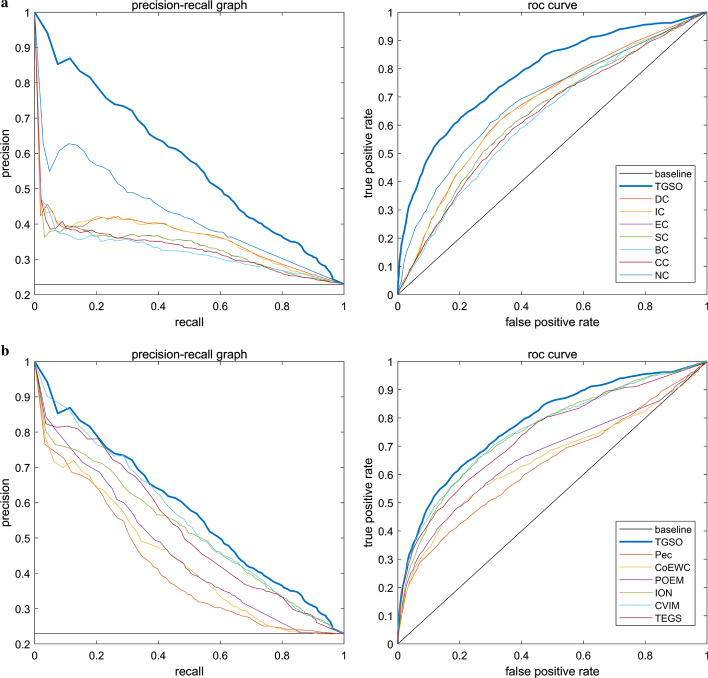
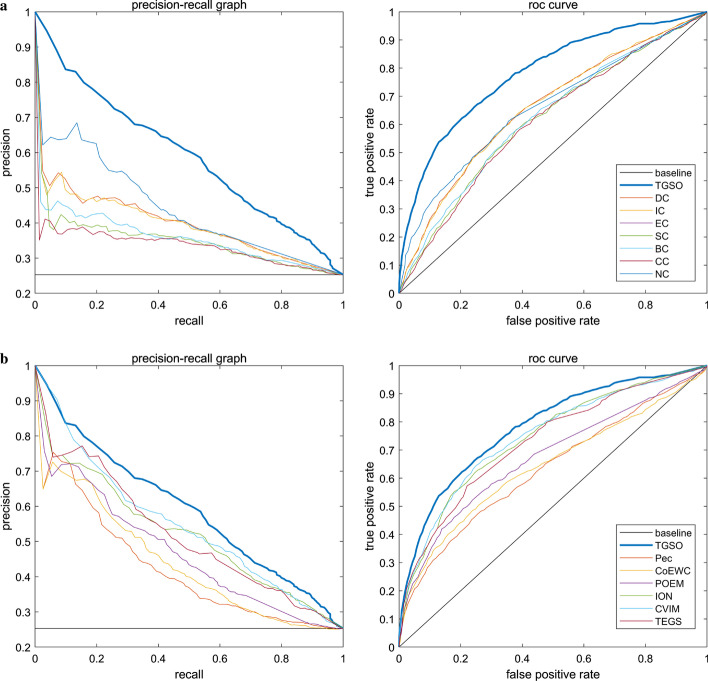
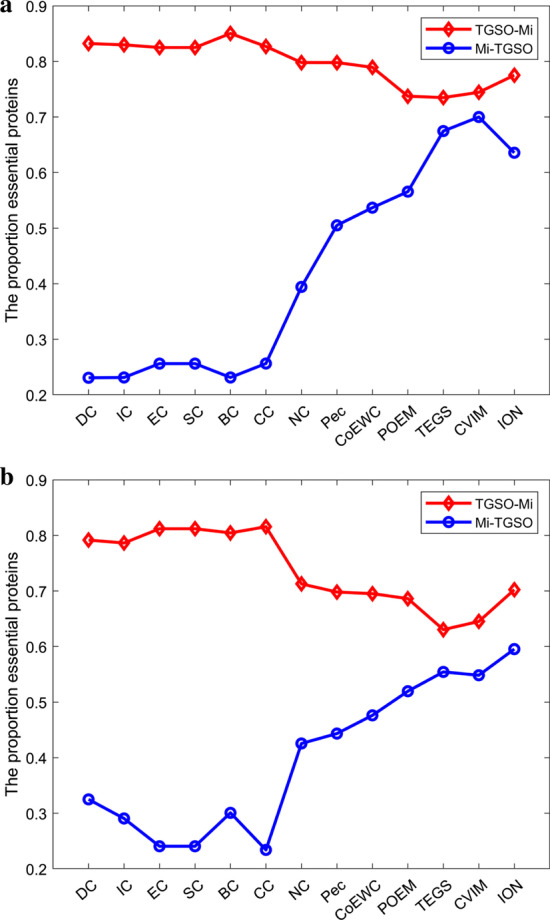
In order to achieve higher prediction performance, in this paper, a new prediction model called TGSO is proposed. In TGSO, a protein aggregation degree network is constructed first by adopting the node density measurement method for complex networks. And simultaneously, a protein co-expression interactive network is constructed by combining the gene expression information with the network connectivity, and a protein co-localization interaction network is constructed based on the subcellular localization data. And then, through integrating these three kinds of newly constructed networks, a comprehensive protein-protein interaction network will be obtained. Finally, based on the homology information, scores can be calculated out iteratively for different proteins, which can be utilized to estimate the importance of proteins effectively. Moreover, in order to evaluate the identification performance of TGSO, we have compared TGSO with 13 different latest competitive methods based on three kinds of yeast databases. And experimental results show that TGSO can achieve identification accuracies of 94%, 82% and 72% out of the top 1%, 5% and 10% candidate proteins respectively, which are to some degree superior to these state-of-the-art competitive models.
We constructed a comprehensive interactive network based on multi-source data to reduce the noise and errors in the initial PPI, and combined with iterative methods to improve the accuracy of necessary protein prediction, and means that TGSO may be conducive to the future development of essential protein recognition as well.
必需蛋白对细胞存活和发育有重大影响,在疾病分析和新药设计中发挥着重要作用。然而,由于通过生物实验来鉴定必需蛋白的效率低且成本高,因此需要开发自动化和准确的检测方法。近年来,蛋白质相互作用网络(PPI)中必需蛋白的识别已成为研究热点,相继提出了许多预测必需蛋白的计算模型。
为了提高预测性能,本文提出了一种新的预测模型 TGSO。在 TGSO 中,首先采用复杂网络节点密度测量方法构建蛋白质聚集度网络,同时结合基因表达信息和网络连通性构建蛋白质共表达交互网络,基于亚细胞定位数据构建蛋白质共定位交互网络。然后,通过整合这三种新构建的网络,得到一个综合的蛋白质-蛋白质相互作用网络。最后,基于同源信息,为不同的蛋白质反复计算得分,从而有效地估计蛋白质的重要性。为了评估 TGSO 的识别性能,我们基于三种酵母数据库,将 TGSO 与 13 种最新的竞争方法进行了比较。实验结果表明,TGSO 在候选蛋白质的前 1%、5%和 10%中,识别精度分别达到了 94%、82%和 72%,在一定程度上优于这些最先进的竞争模型。
我们构建了一个基于多源数据的综合交互网络,以减少初始 PPI 中的噪声和误差,并结合迭代方法提高必需蛋白预测的准确性,这意味着 TGSO 可能有助于未来的必需蛋白识别发展。